 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Detection of a Human-Comprehensible Gestural Language for Underwater Multi-Human-Robot Collaboration
Paper and Code
Jul 12, 2022
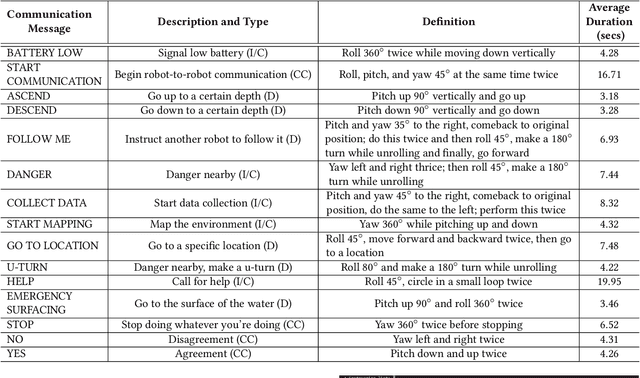

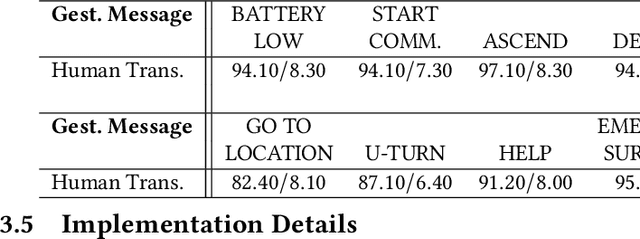
In this paper, we present a motion-based robotic communication framework that enables non-verbal communication among autonomous underwater vehicles (AUVs) and human divers. We design a gestural language for AUV-to-AUV communication which can be easily understood by divers observing the conversation unlike typical radio frequency, light, or audio based AUV communication. To allow AUVs to visually understand a gesture from another AUV, we propose a deep network (RRCommNet) which exploits a self-attention mechanism to learn to recognize each message by extracting maximally discriminative spatio-temporal features. We train this network on diverse simulated and real-world data. Our experimental evaluations, both in simulation and in closed-water robot trials, demonstrate that the proposed RRCommNet architecture is able to decipher gesture-based messages with an average accuracy of 88-94% on simulated data, 73-83% on real data (depending on the version of the model used). Further, by performing a message transcription study with human participants, we also show that the proposed language can be understood by humans, with an overall transcription accuracy of 88%. Finally, we discuss the inference runtime of RRCommNet on embedded GPU hardware, for real-time use on board AUVs in the field.