 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation of Underwater Imagery: Dataset and Benchmark
Apr 02, 2020


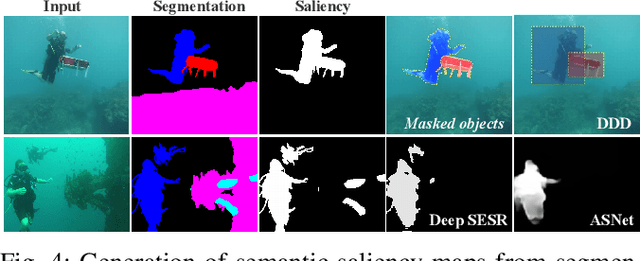
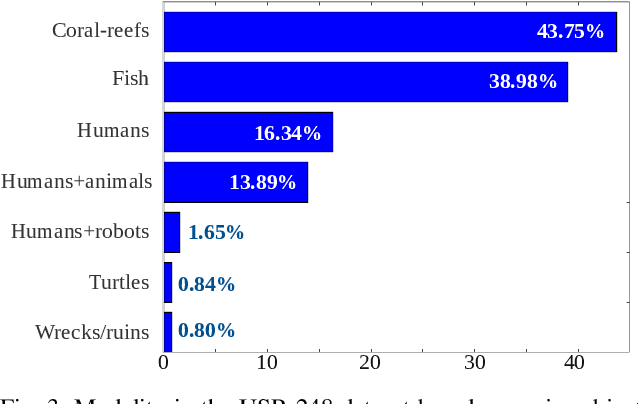
In this paper, we present the first large-scale dataset for semantic Segmentation of Underwater IMagery (SUIM). It contains over 1500 images with pixel annotations for eight object categories: fish (vertebrates), reefs (invertebrates), aquatic plants, wrecks/ruins, human divers, robots, and sea-floor. The images are rigorously collected during oceanic explorations and human-robot collaborative experiments, and annotated by human participants. We also present a comprehensive benchmark evaluation of several state-of-the-art semantic segmentation approaches based on standard performance metrics. Additionally, we present SUIM-Net, a fully-convolutional deep residual model that balances the trade-off between performance and computational efficiency. It offers competitive performance while ensuring fast end-to-end inference, which is essential for its use in the autonomy pipeline by visually-guided underwater robots. In particular, we demonstrate its usability benefits for visual servoing, saliency prediction, and detailed scene understanding. With a variety of use cases, the proposed model and benchmark dataset open up promising opportunities for future research on underwater robot vision.
Simultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception
Feb 04, 2020



In this paper, we introduce and tackle the simultaneous enhancement and super-resolution (SESR) problem for underwater robot vision and provide an efficient solution for near real-time applications. We present Deep SESR, a residual-in-residual network-based generative model that can learn to restore perceptual image qualities at 2x, 3x, or 4x higher spatial resolution. We supervise its training by formulating a multi-modal objective function that addresses the chrominance-specific underwater color degradation, lack of image sharpness, and loss in high-level feature representation. It is also supervised to learn salient foreground regions in the image, which in turn guides the network to learn global contrast enhancement. We design an end-to-end training pipeline to jointly learn the saliency prediction and SESR on a shared hierarchical feature space for fast inference. Moreover, we present UFO-120, the first dataset to facilitate large-scale SESR learning; it contains over 1500 training samples and a benchmark test set of 120 samples. By thorough experimental evaluation on the UFO-120 and other standard datasets, we demonstrate that Deep SESR outperforms the existing solutions for underwater image enhancement and super-resolution. We also validate its generalization performance on several test cases that include underwater images with diverse spectral and spatial degradation levels, and also terrestrial images with unseen natural objects. Lastly, we analyze its computational feasibility for single-board deployments and demonstrate its operational benefits for visually-guided underwater robots. The model and dataset information will be available at: https://github.com/xahidbuffon/Deep-SESR.
Underwater Image Super-Resolution using Deep Residual Multipliers
Sep 20, 2019

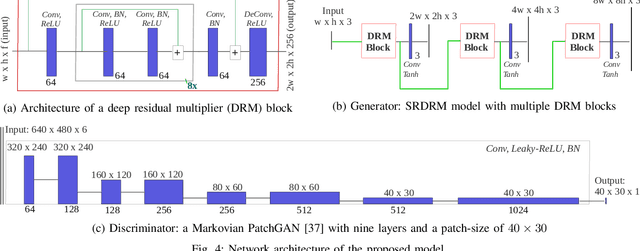
We present a deep residual network-based generative model for single image super-resolution (SISR) of underwater imagery for use by autonomous underwater robots. We also provide an adversarial training pipeline for learning SISR from paired data. In order to supervise the training, we formulate an objective function that evaluates the perceptual quality of an image based on its global content, color, and local style information. Additionally, we present USR-248, a large-scale dataset of three sets of underwater images of high (640x480) and low (80x60, 160x120, and 320x240) resolution. USR-248 contains over 7K paired instances in each set of data for supervised training of 2x, 4x, or 8x SISR models. Furthermore, we validate the effectiveness of our proposed model through qualitative and quantitative experiments and compare the results with several state-of-the-art models' performances. We also analyze its practical feasibility for applications such as scene understanding and attention modeling in noisy visual conditions.