 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderwater Image Super-Resolution using Deep Residual Multipliers
Paper and Code


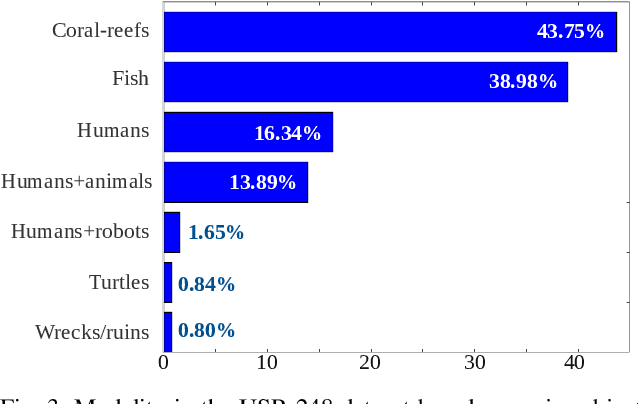
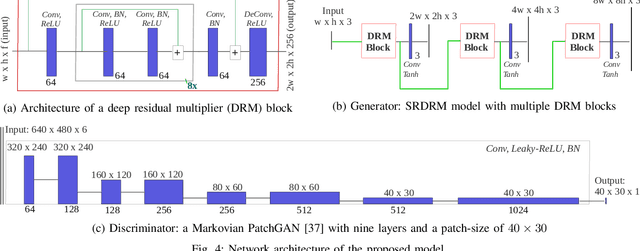
We present a deep residual network-based generative model for single image super-resolution (SISR) of underwater imagery for use by autonomous underwater robots. We also provide an adversarial training pipeline for learning SISR from paired data. In order to supervise the training, we formulate an objective function that evaluates the perceptual quality of an image based on its global content, color, and local style information. Additionally, we present USR-248, a large-scale dataset of three sets of underwater images of high (640x480) and low (80x60, 160x120, and 320x240) resolution. USR-248 contains over 7K paired instances in each set of data for supervised training of 2x, 4x, or 8x SISR models. Furthermore, we validate the effectiveness of our proposed model through qualitative and quantitative experiments and compare the results with several state-of-the-art models' performances. We also analyze its practical feasibility for applications such as scene understanding and attention modeling in noisy visual conditions.