 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletons Speak Louder than Text: A Motion-Aware Pretraining Paradigm for Video-Based Person Re-Identification
Nov 17, 2025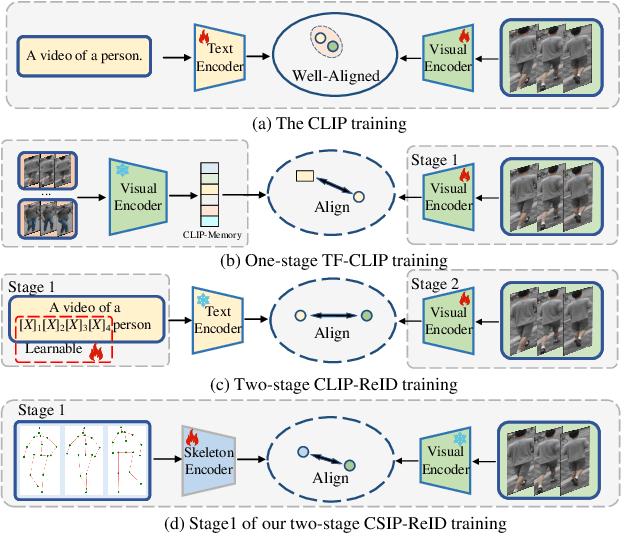
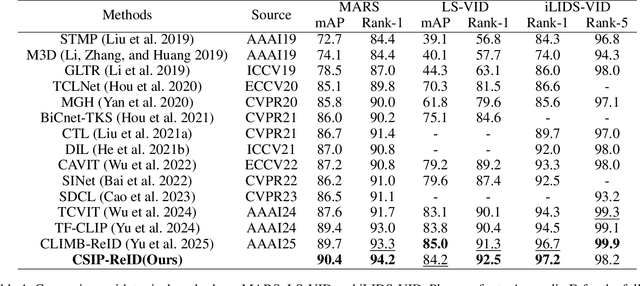
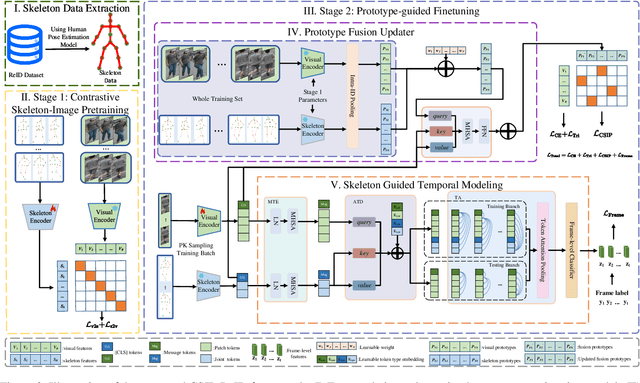

Multimodal pretraining has revolutionized visual understanding, but its impact on video-based person re-identification (ReID) remains underexplored. Existing approaches often rely on video-text pairs, yet suffer from two fundamental limitations: (1) lack of genuine multimodal pretraining, and (2) text poorly captures fine-grained temporal motion-an essential cue for distinguishing identities in video. In this work, we take a bold departure from text-based paradigms by introducing the first skeleton-driven pretraining framework for ReID. To achieve this, we propose Contrastive Skeleton-Image Pretraining for ReID (CSIP-ReID), a novel two-stage method that leverages skeleton sequences as a spatiotemporally informative modality aligned with video frames. In the first stage, we employ contrastive learning to align skeleton and visual features at sequence level. In the second stage, we introduce a dynamic Prototype Fusion Updater (PFU) to refine multimodal identity prototypes, fusing motion and appearance cues. Moreover, we propose a Skeleton Guided Temporal Modeling (SGTM) module that distills temporal cues from skeleton data and integrates them into visual features. Extensive experiments demonstrate that CSIP-ReID achieves new state-of-the-art results on standard video ReID benchmarks (MARS, LS-VID, iLIDS-VID). Moreover, it exhibits strong generalization to skeleton-only ReID tasks (BIWI, IAS), significantly outperforming previous methods. CSIP-ReID pioneers an annotation-free and motion-aware pretraining paradigm for ReID, opening a new frontier in multimodal representation learning.
MoChat: Joints-Grouped Spatio-Temporal Grounding LLM for Multi-Turn Motion Comprehension and Description
Oct 15, 2024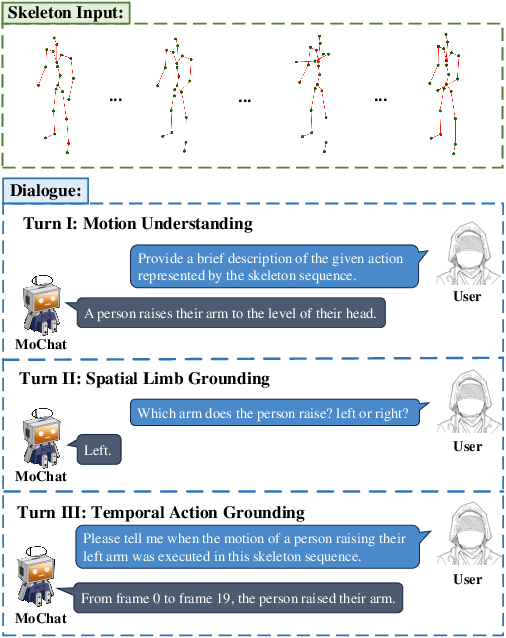
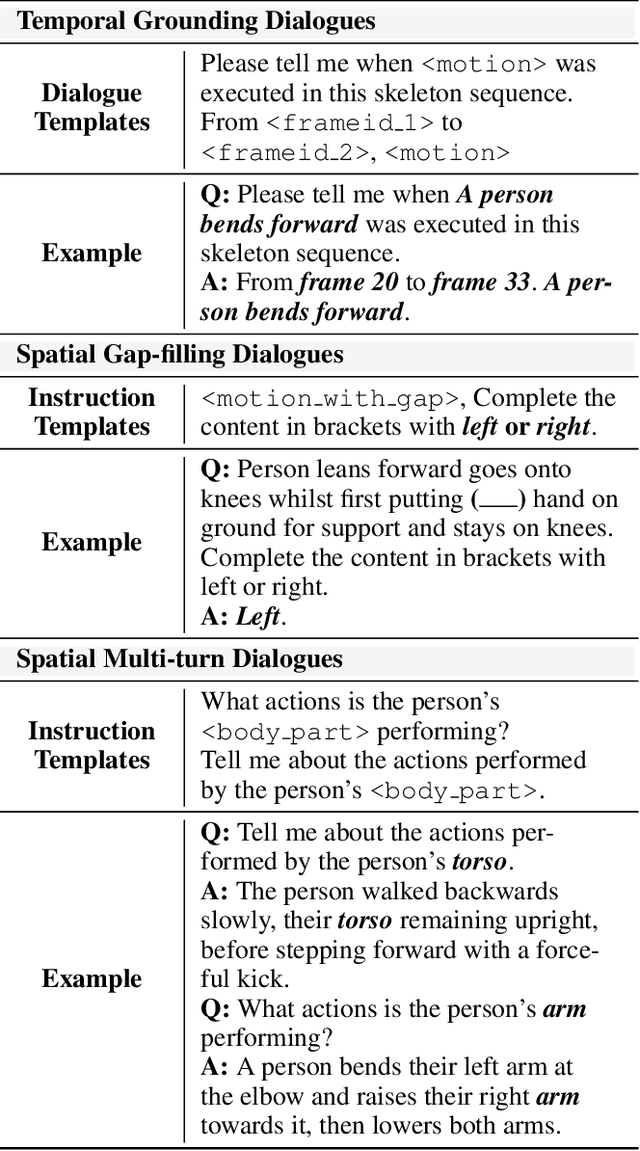
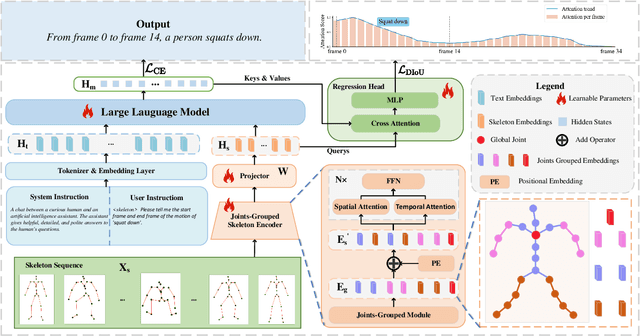

Despite continuous advancements in deep learning for understanding human motion, existing models often struggle to accurately identify action timing and specific body parts, typically supporting only single-round interaction. Such limitations in capturing fine-grained motion details reduce their effectiveness in motion understanding tasks. In this paper, we propose MoChat, a multimodal large language model capable of spatio-temporal grounding of human motion and understanding multi-turn dialogue context. To achieve these capabilities, we group the spatial information of each skeleton frame based on human anatomical structure and then apply them with Joints-Grouped Skeleton Encoder, whose outputs are combined with LLM embeddings to create spatio-aware and temporal-aware embeddings separately. Additionally, we develop a pipeline for extracting timestamps from skeleton sequences based on textual annotations, and construct multi-turn dialogues for spatially grounding. Finally, various task instructions are generated for jointly training. Experimental results demonstrate that MoChat achieves state-of-the-art performance across multiple metrics in motion understanding tasks, making it as the first model capable of fine-grained spatio-temporal grounding of human motion.
Grounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Apr 28, 2024



In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
Fast Sparse View Guided NeRF Update for Object Reconfigurations
Mar 16, 2024Neural Radiance Field (NeRF), as an implicit 3D scene representation, lacks inherent ability to accommodate changes made to the initial static scene. If objects are reconfigured, it is difficult to update the NeRF to reflect the new state of the scene without time-consuming data re-capturing and NeRF re-training. To address this limitation, we develop the first update method for NeRFs to physical changes. Our method takes only sparse new images (e.g. 4) of the altered scene as extra inputs and update the pre-trained NeRF in around 1 to 2 minutes. Particularly, we develop a pipeline to identify scene changes and update the NeRF accordingly. Our core idea is the use of a second helper NeRF to learn the local geometry and appearance changes, which sidesteps the optimization difficulties in direct NeRF fine-tuning. The interpolation power of the helper NeRF is the key to accurately reconstruct the un-occluded objects regions under sparse view supervision. Our method imposes no constraints on NeRF pre-training, and requires no extra user input or explicit semantic priors. It is an order of magnitude faster than re-training NeRF from scratch while maintaining on-par and even superior performance.
A Quantitative Evaluation of Score Distillation Sampling Based Text-to-3D
Feb 29, 2024The development of generative models that create 3D content from a text prompt has made considerable strides thanks to the use of the score distillation sampling (SDS) method on pre-trained diffusion models for image generation. However, the SDS method is also the source of several artifacts, such as the Janus problem, the misalignment between the text prompt and the generated 3D model, and 3D model inaccuracies. While existing methods heavily rely on the qualitative assessment of these artifacts through visual inspection of a limited set of samples, in this work we propose more objective quantitative evaluation metrics, which we cross-validate via human ratings, and show analysis of the failure cases of the SDS technique. We demonstrate the effectiveness of this analysis by designing a novel computationally efficient baseline model that achieves state-of-the-art performance on the proposed metrics while addressing all the above-mentioned artifacts.
Towards Visual Foundational Models of Physical Scenes
Jun 06, 2023



We describe a first step towards learning general-purpose visual representations of physical scenes using only image prediction as a training criterion. To do so, we first define "physical scene" and show that, even though different agents may maintain different representations of the same scene, the underlying physical scene that can be inferred is unique. Then, we show that NeRFs cannot represent the physical scene, as they lack extrapolation mechanisms. Those, however, could be provided by Diffusion Models, at least in theory. To test this hypothesis empirically, NeRFs can be combined with Diffusion Models, a process we refer to as NeRF Diffusion, used as unsupervised representations of the physical scene. Our analysis is limited to visual data, without external grounding mechanisms that can be provided by independent sensory modalities.
Fast Direct Stereo Visual SLAM
Dec 03, 2021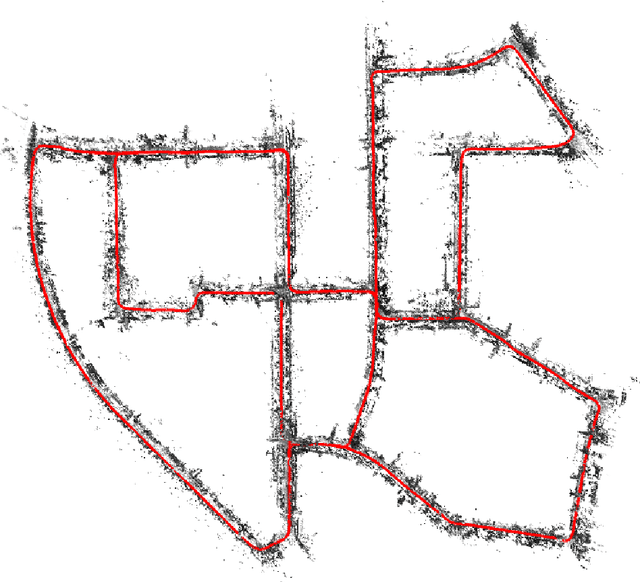
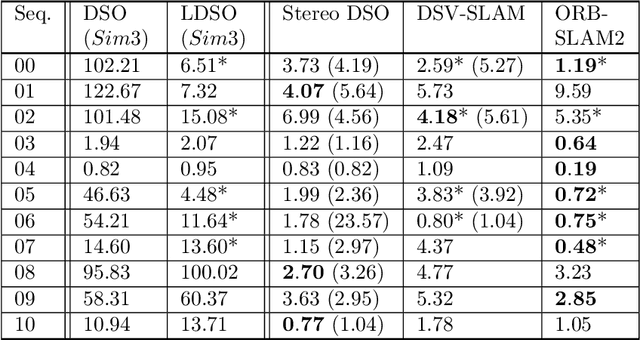
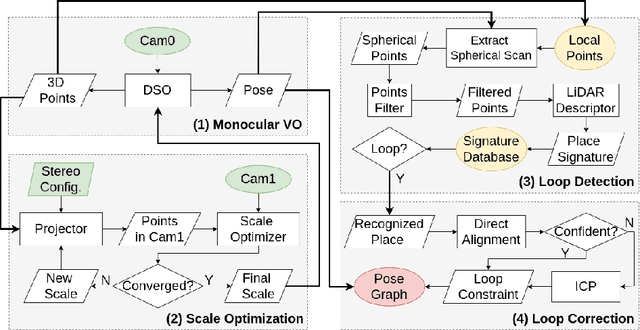
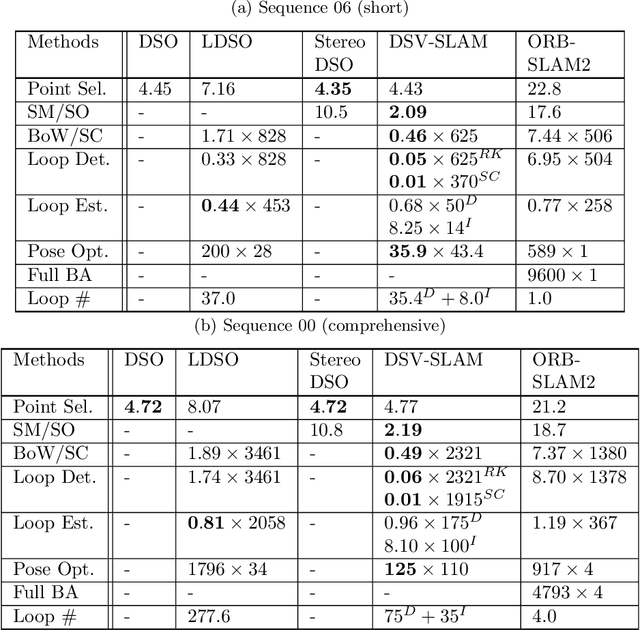
We propose a novel approach for fast and accurate stereo visual Simultaneous Localization and Mapping (SLAM) independent of feature detection and matching. We extend monocular Direct Sparse Odometry (DSO) to a stereo system by optimizing the scale of the 3D points to minimize photometric error for the stereo configuration, which yields a computationally efficient and robust method compared to conventional stereo matching. We further extend it to a full SLAM system with loop closure to reduce accumulated errors. With the assumption of forward camera motion, we imitate a LiDAR scan using the 3D points obtained from the visual odometry and adapt a LiDAR descriptor for place recognition to facilitate more efficient detection of loop closures. Afterward, we estimate the relative pose using direct alignment by minimizing the photometric error for potential loop closures. Optionally, further improvement over direct alignment is achieved by using the Iterative Closest Point (ICP) algorithm. Lastly, we optimize a pose graph to improve SLAM accuracy globally. By avoiding feature detection or matching in our SLAM system, we ensure high computational efficiency and robustness. Thorough experimental validations on public datasets demonstrate its effectiveness compared to the state-of-the-art approaches.
Continuous-Time Spline Visual-Inertial Odometry
Sep 19, 2021
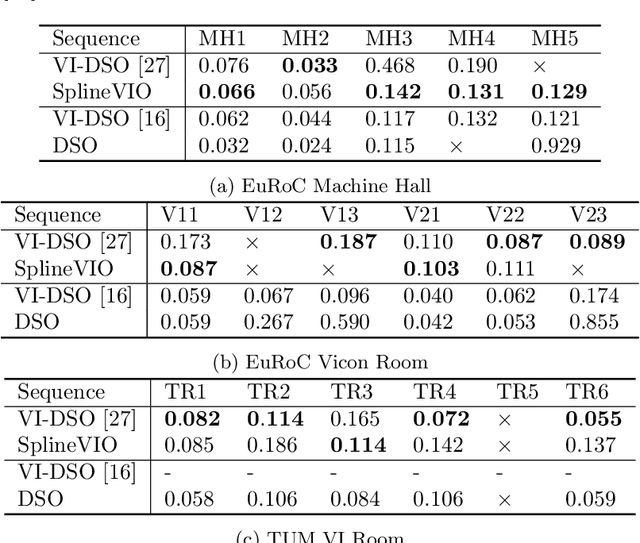
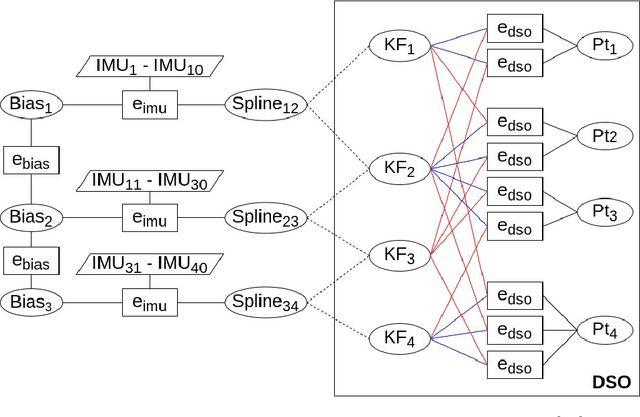

We propose a continuous-time spline-based formulation for visual-inertial odometry (VIO). Specifically, we model the poses as a cubic spline, whose temporal derivatives are used to synthesize linear acceleration and angular velocity, which are compared to the measurements from the inertial measurement unit (IMU) for optimal state estimation. The spline boundary conditions create constraints between the camera and the IMU, with which we formulate VIO as a constrained nonlinear optimization problem. Continuous-time pose representation makes it possible to address many VIO challenges, e.g., rolling shutter distortion and sensors that may lack synchronization. We conduct experiments on two publicly available datasets that demonstrate the state-of-the-art accuracy and real-time computational efficiency of our method.
Learning Rolling Shutter Correction from Real Data without Camera Motion Assumption
Nov 05, 2020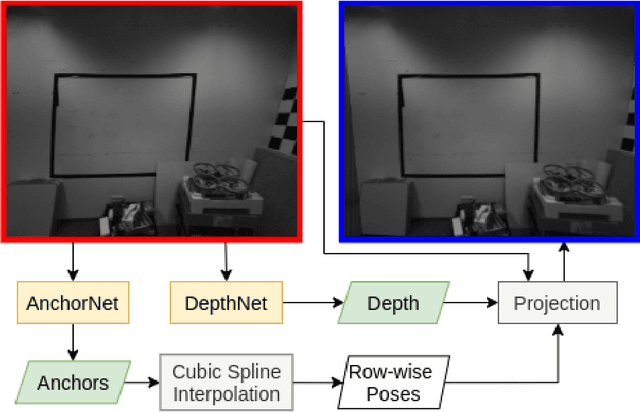

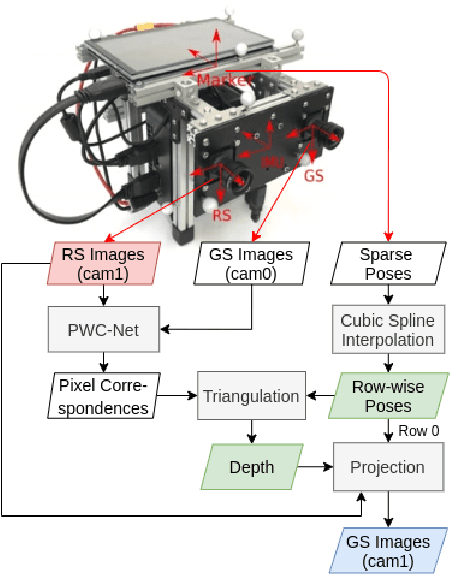
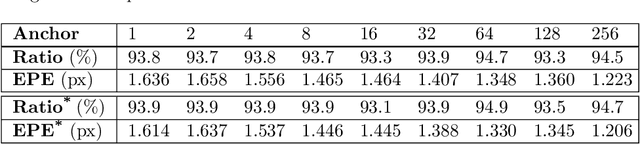
The rolling shutter mechanism in modern cameras generates distortions as the images are formed on the sensor through a row-by-row readout process; this is highly undesirable for photography and vision-based algorithms (e.g., structure-from-motion and visual SLAM). In this paper, we propose a deep neural network to predict depth and camera poses for single-frame rolling shutter correction. Compared to the state-of-the-art, the proposed method has no assumptions on camera motion. It is enabled by training on real images captured by rolling shutter cameras instead of synthetic ones generated with certain motion assumption. Consequently, the proposed method performs better for real rolling shutter images. This makes it possible for numerous vision-based algorithms to use imagery captured using rolling shutter cameras and produce highly accurate results. Our evaluations on the TUM rolling shutter dataset using DSO and COLMAP validate the accuracy and robustness of the proposed method.
Design and Experiments with LoCO AUV: A Low Cost Open-Source Autonomous Underwater Vehicle
Mar 19, 2020


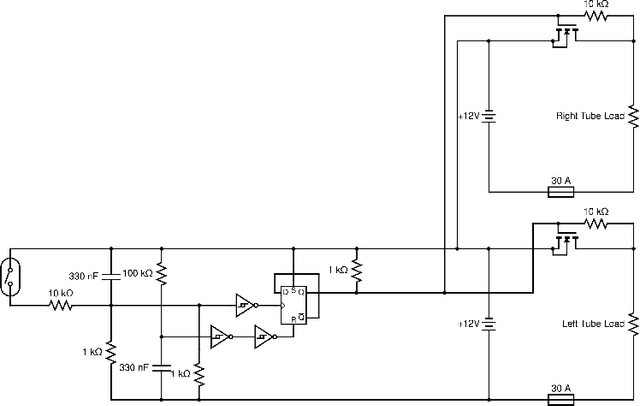
In this paper we present LoCO AUV, a Low-Cost, Open Autonomous Underwater Vehicle. LoCO is a general-purpose, single-person-deployable, vision-guided AUV, rated to a depth of 100 meters. We discuss the open and expandable design of this underwater robot, as well as the design of a simulator in Gazebo. Additionally, we explore the platform's preliminary local motion control and state estimation abilities, which enable it to perform maneuvers autonomously. In order to demonstrate its usefulness for a variety of tasks, we implement a variety of our previously presented human-robot interaction capabilities on LoCO, including gestural control, diver following, and robot communication via motion. Finally, we discuss the practical concerns of deployment and our experiences in using this robot in pools, lakes, and the ocean. All design details, instructions on assembly, and code will be released under a permissive, open-source license.