 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeletons Speak Louder than Text: A Motion-Aware Pretraining Paradigm for Video-Based Person Re-Identification
Nov 17, 2025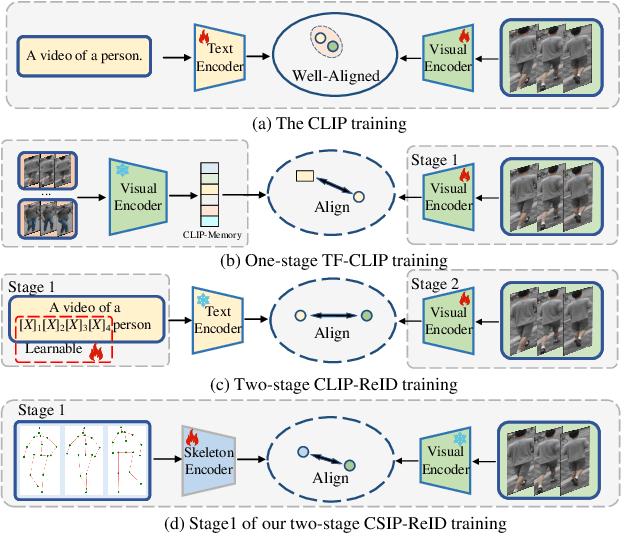
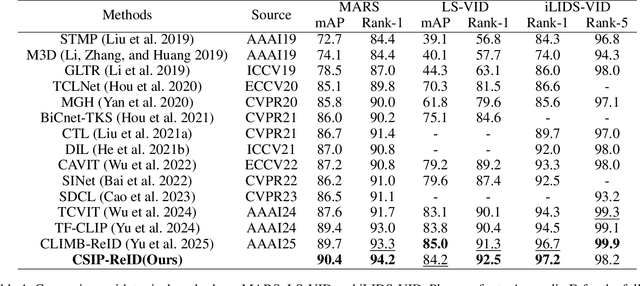
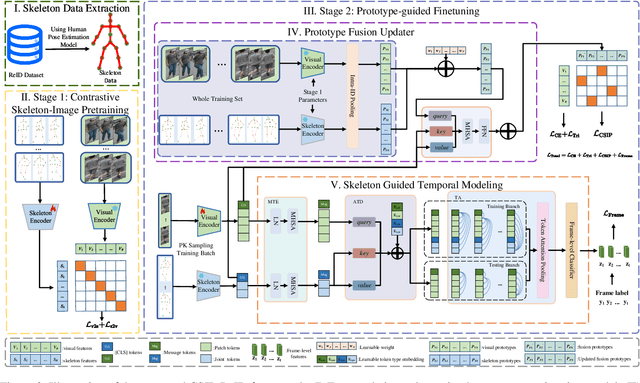

Multimodal pretraining has revolutionized visual understanding, but its impact on video-based person re-identification (ReID) remains underexplored. Existing approaches often rely on video-text pairs, yet suffer from two fundamental limitations: (1) lack of genuine multimodal pretraining, and (2) text poorly captures fine-grained temporal motion-an essential cue for distinguishing identities in video. In this work, we take a bold departure from text-based paradigms by introducing the first skeleton-driven pretraining framework for ReID. To achieve this, we propose Contrastive Skeleton-Image Pretraining for ReID (CSIP-ReID), a novel two-stage method that leverages skeleton sequences as a spatiotemporally informative modality aligned with video frames. In the first stage, we employ contrastive learning to align skeleton and visual features at sequence level. In the second stage, we introduce a dynamic Prototype Fusion Updater (PFU) to refine multimodal identity prototypes, fusing motion and appearance cues. Moreover, we propose a Skeleton Guided Temporal Modeling (SGTM) module that distills temporal cues from skeleton data and integrates them into visual features. Extensive experiments demonstrate that CSIP-ReID achieves new state-of-the-art results on standard video ReID benchmarks (MARS, LS-VID, iLIDS-VID). Moreover, it exhibits strong generalization to skeleton-only ReID tasks (BIWI, IAS), significantly outperforming previous methods. CSIP-ReID pioneers an annotation-free and motion-aware pretraining paradigm for ReID, opening a new frontier in multimodal representation learning.
MoChat: Joints-Grouped Spatio-Temporal Grounding LLM for Multi-Turn Motion Comprehension and Description
Oct 15, 2024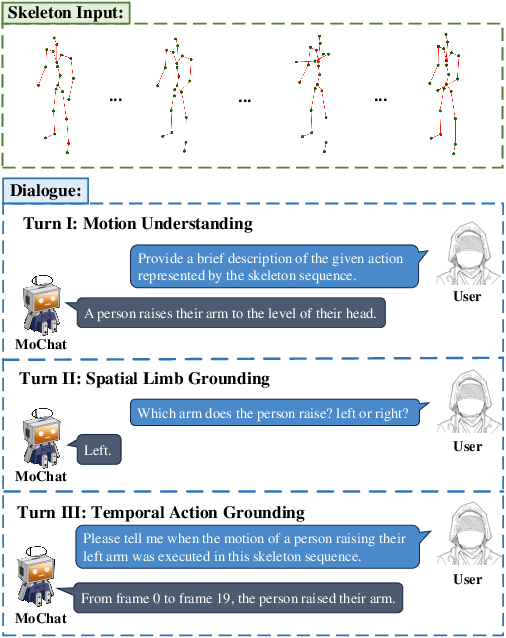
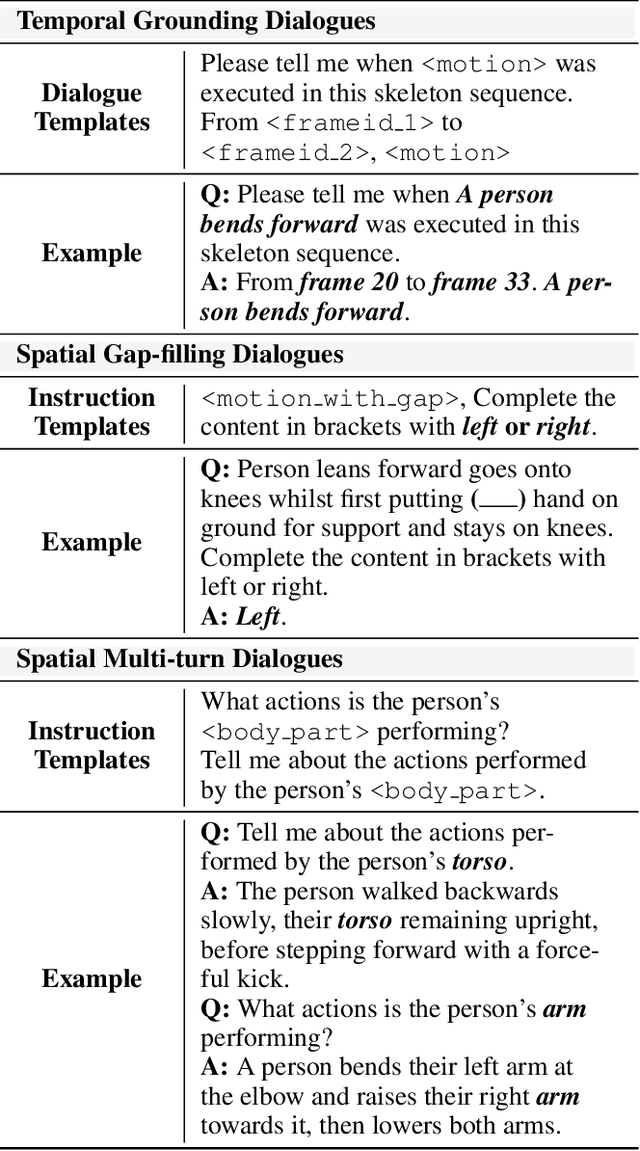
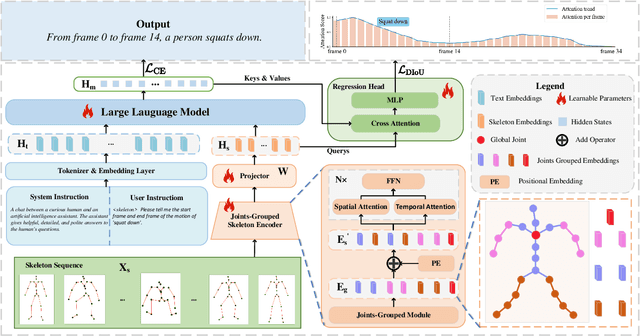

Despite continuous advancements in deep learning for understanding human motion, existing models often struggle to accurately identify action timing and specific body parts, typically supporting only single-round interaction. Such limitations in capturing fine-grained motion details reduce their effectiveness in motion understanding tasks. In this paper, we propose MoChat, a multimodal large language model capable of spatio-temporal grounding of human motion and understanding multi-turn dialogue context. To achieve these capabilities, we group the spatial information of each skeleton frame based on human anatomical structure and then apply them with Joints-Grouped Skeleton Encoder, whose outputs are combined with LLM embeddings to create spatio-aware and temporal-aware embeddings separately. Additionally, we develop a pipeline for extracting timestamps from skeleton sequences based on textual annotations, and construct multi-turn dialogues for spatially grounding. Finally, various task instructions are generated for jointly training. Experimental results demonstrate that MoChat achieves state-of-the-art performance across multiple metrics in motion understanding tasks, making it as the first model capable of fine-grained spatio-temporal grounding of human motion.