 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextEditBench: Evaluating Reasoning-aware Text Editing Beyond Rendering
Dec 18, 2025Text rendering has recently emerged as one of the most challenging frontiers in visual generation, drawing significant attention from large-scale diffusion and multimodal models. However, text editing within images remains largely unexplored, as it requires generating legible characters while preserving semantic, geometric, and contextual coherence. To fill this gap, we introduce TextEditBench, a comprehensive evaluation benchmark that explicitly focuses on text-centric regions in images. Beyond basic pixel manipulations, our benchmark emphasizes reasoning-intensive editing scenarios that require models to understand physical plausibility, linguistic meaning, and cross-modal dependencies. We further propose a novel evaluation dimension, Semantic Expectation (SE), which measures reasoning ability of model to maintain semantic consistency, contextual coherence, and cross-modal alignment during text editing. Extensive experiments on state-of-the-art editing systems reveal that while current models can follow simple textual instructions, they still struggle with context-dependent reasoning, physical consistency, and layout-aware integration. By focusing evaluation on this long-overlooked yet fundamental capability, TextEditBench establishes a new testing ground for advancing text-guided image editing and reasoning in multimodal generation.
Cross-Sparsity-Enabled Multipath Perception via Structured Bayesian Inference for Multi-Target Estimation
Nov 18, 2025In this paper, we investigate a multi-target sensing system in multipath environment, where inter-target scattering gives rise to first-order reflected paths whose angles of departure (AoDs) and angles of arrival (AoAs) coincide with the direct-path angles of different targets. Unlike other multipath components, these first-order paths carry structural information that can be exploited as additional prior knowledge for target direction estimation. To exploit this property, we construct a sparse representation of the multi-target sensing channel and propose a novel cross sparsity structure under a three-layer hierarchical structured (3LHS) prior model, which leverages the first-order paths to enhance the prior probability of the direct paths and thereby improve the estimation accuracy. Building on this model, we propose a structured fast turbo variational Bayesian inference (SF-TVBI) algorithm, which integrates an efficient message-passing strategy to enable tractable probabilistic exchange within the cross sparsity, and a two-timescale update scheme to reduce the update frequency of the high-dimensional sparse vector. Simulation results demonstrate that leveraging the proposed cross sparsity structure is able to improve the target angle estimation accuracy substantially, and the SF-TVBI algorithm achieves estimation performance comparable to that of the Turbo-VBI, but with lower computational complexity.
Skeletons Speak Louder than Text: A Motion-Aware Pretraining Paradigm for Video-Based Person Re-Identification
Nov 17, 2025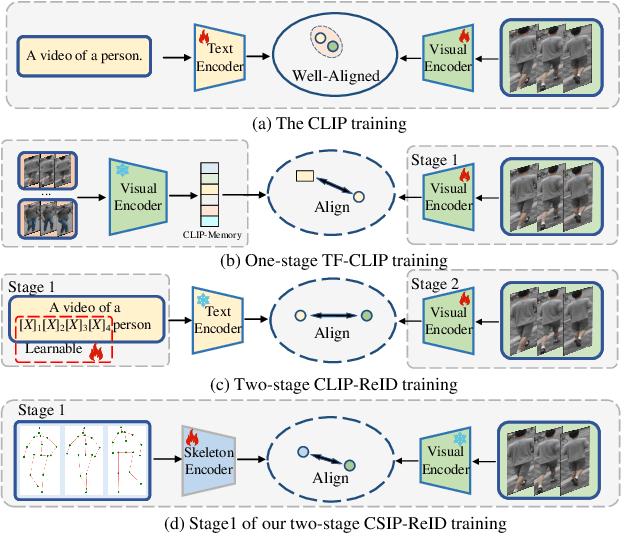
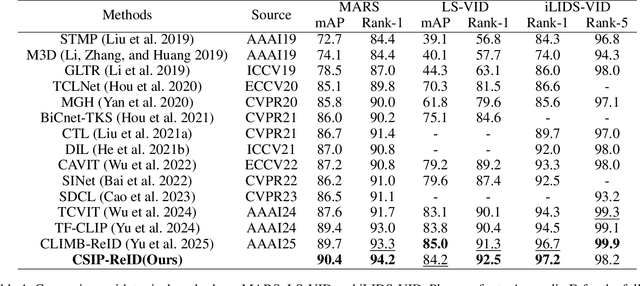
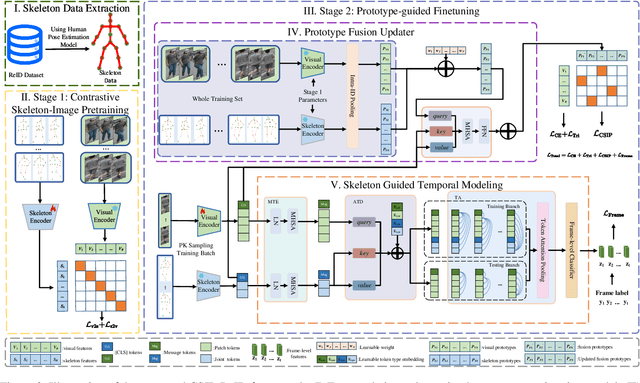

Multimodal pretraining has revolutionized visual understanding, but its impact on video-based person re-identification (ReID) remains underexplored. Existing approaches often rely on video-text pairs, yet suffer from two fundamental limitations: (1) lack of genuine multimodal pretraining, and (2) text poorly captures fine-grained temporal motion-an essential cue for distinguishing identities in video. In this work, we take a bold departure from text-based paradigms by introducing the first skeleton-driven pretraining framework for ReID. To achieve this, we propose Contrastive Skeleton-Image Pretraining for ReID (CSIP-ReID), a novel two-stage method that leverages skeleton sequences as a spatiotemporally informative modality aligned with video frames. In the first stage, we employ contrastive learning to align skeleton and visual features at sequence level. In the second stage, we introduce a dynamic Prototype Fusion Updater (PFU) to refine multimodal identity prototypes, fusing motion and appearance cues. Moreover, we propose a Skeleton Guided Temporal Modeling (SGTM) module that distills temporal cues from skeleton data and integrates them into visual features. Extensive experiments demonstrate that CSIP-ReID achieves new state-of-the-art results on standard video ReID benchmarks (MARS, LS-VID, iLIDS-VID). Moreover, it exhibits strong generalization to skeleton-only ReID tasks (BIWI, IAS), significantly outperforming previous methods. CSIP-ReID pioneers an annotation-free and motion-aware pretraining paradigm for ReID, opening a new frontier in multimodal representation learning.
GRACE: Designing Generative Face Video Codec via Agile Hardware-Centric Workflow
Nov 12, 2025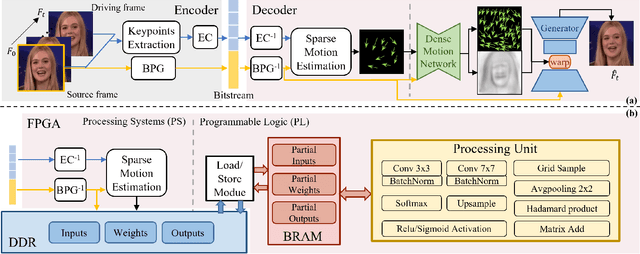


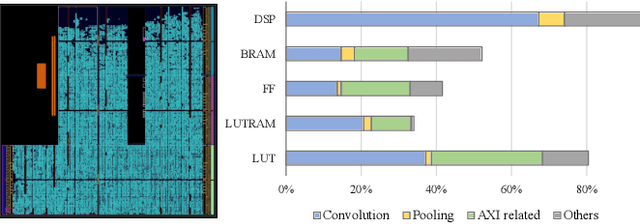
The Animation-based Generative Codec (AGC) is an emerging paradigm for talking-face video compression. However, deploying its intricate decoder on resource and power-constrained edge devices presents challenges due to numerous parameters, the inflexibility to adapt to dynamically evolving algorithms, and the high power consumption induced by extensive computations and data transmission. This paper for the first time proposes a novel field programmable gate arrays (FPGAs)-oriented AGC deployment scheme for edge-computing video services. Initially, we analyze the AGC algorithm and employ network compression methods including post-training static quantization and layer fusion techniques. Subsequently, we design an overlapped accelerator utilizing the co-processor paradigm to perform computations through software-hardware co-design. The hardware processing unit comprises engines such as convolution, grid sampling, upsample, etc. Parallelization optimization strategies like double-buffered pipelines and loop unrolling are employed to fully exploit the resources of FPGA. Ultimately, we establish an AGC FPGA prototype on the PYNQ-Z1 platform using the proposed scheme, achieving \textbf{24.9$\times$} and \textbf{4.1$\times$} higher energy efficiency against commercial Central Processing Unit (CPU) and Graphic Processing Unit (GPU), respectively. Specifically, only \textbf{11.7} microjoules ($\upmu$J) are required for one pixel reconstructed by this FPGA system.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025
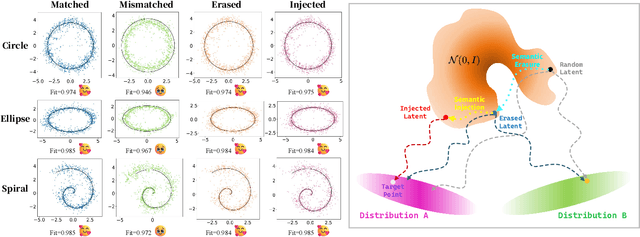


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
GateFuseNet: An Adaptive 3D Multimodal Neuroimaging Fusion Network for Parkinson's Disease Diagnosis
Oct 26, 2025Accurate diagnosis of Parkinson's disease (PD) from MRI remains challenging due to symptom variability and pathological heterogeneity. Most existing methods rely on conventional magnitude-based MRI modalities, such as T1-weighted images (T1w), which are less sensitive to PD pathology than Quantitative Susceptibility Mapping (QSM), a phase-based MRI technique that quantifies iron deposition in deep gray matter nuclei. In this study, we propose GateFuseNet, an adaptive 3D multimodal fusion network that integrates QSM and T1w images for PD diagnosis. The core innovation lies in a gated fusion module that learns modality-specific attention weights and channel-wise gating vectors for selective feature modulation. This hierarchical gating mechanism enhances ROI-aware features while suppressing irrelevant signals. Experimental results show that our method outperforms three existing state-of-the-art approaches, achieving 85.00% accuracy and 92.06% AUC. Ablation studies further validate the contributions of ROI guidance, multimodal integration, and fusion positioning. Grad-CAM visualizations confirm the model's focus on clinically relevant pathological regions. The source codes and pretrained models can be found at https://github.com/YangGaoUQ/GateFuseNet
Whole-body Motion Control of an Omnidirectional Wheel-Legged Mobile Manipulator via Contact-Aware Dynamic Optimization
Sep 17, 2025Wheel-legged robots with integrated manipulators hold great promise for mobile manipulation in logistics, industrial automation, and human-robot collaboration. However, unified control of such systems remains challenging due to the redundancy in degrees of freedom, complex wheel-ground contact dynamics, and the need for seamless coordination between locomotion and manipulation. In this work, we present the design and whole-body motion control of an omnidirectional wheel-legged quadrupedal robot equipped with a dexterous manipulator. The proposed platform incorporates independently actuated steering modules and hub-driven wheels, enabling agile omnidirectional locomotion with high maneuverability in structured environments. To address the challenges of contact-rich interaction, we develop a contact-aware whole-body dynamic optimization framework that integrates point-contact modeling for manipulation with line-contact modeling for wheel-ground interactions. A warm-start strategy is introduced to accelerate online optimization, ensuring real-time feasibility for high-dimensional control. Furthermore, a unified kinematic model tailored for the robot's 4WIS-4WID actuation scheme eliminates the need for mode switching across different locomotion strategies, improving control consistency and robustness. Simulation and experimental results validate the effectiveness of the proposed framework, demonstrating agile terrain traversal, high-speed omnidirectional mobility, and precise manipulation under diverse scenarios, underscoring the system's potential for factory automation, urban logistics, and service robotics in semi-structured environments.
Improving Densification in 3D Gaussian Splatting for High-Fidelity Rendering
Aug 17, 2025Although 3D Gaussian Splatting (3DGS) has achieved impressive performance in real-time rendering, its densification strategy often results in suboptimal reconstruction quality. In this work, we present a comprehensive improvement to the densification pipeline of 3DGS from three perspectives: when to densify, how to densify, and how to mitigate overfitting. Specifically, we propose an Edge-Aware Score to effectively select candidate Gaussians for splitting. We further introduce a Long-Axis Split strategy that reduces geometric distortions introduced by clone and split operations. To address overfitting, we design a set of techniques, including Recovery-Aware Pruning, Multi-step Update, and Growth Control. Our method enhances rendering fidelity without introducing additional training or inference overhead, achieving state-of-the-art performance with fewer Gaussians.
ActivityDiff: A diffusion model with Positive and Negative Activity Guidance for De Novo Drug Design
Aug 08, 2025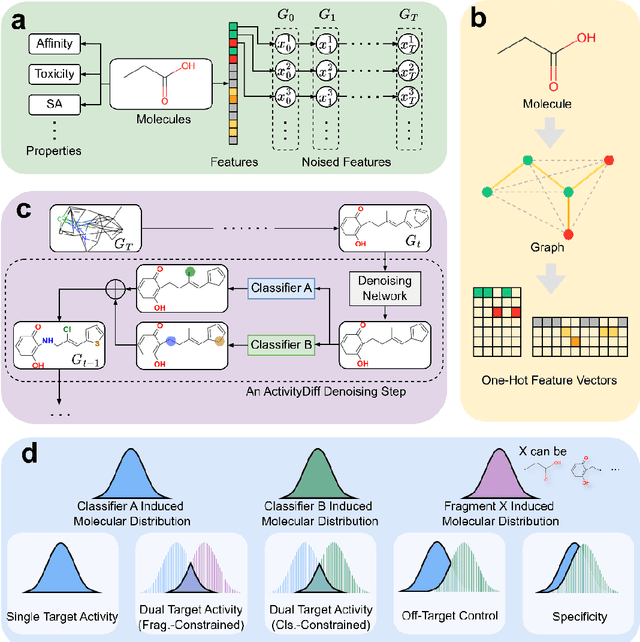
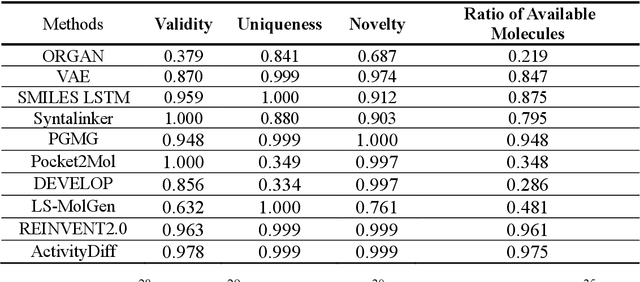
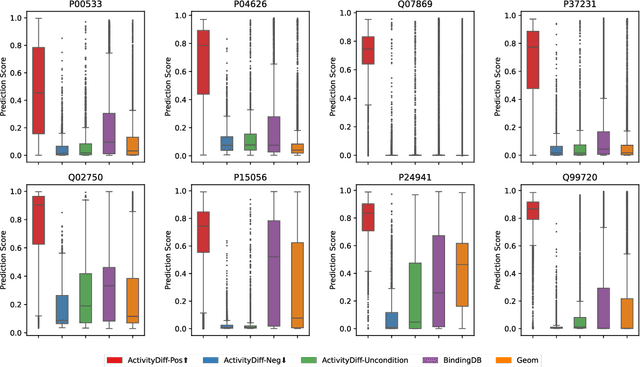
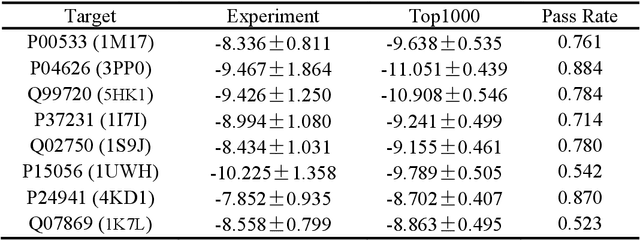
Achieving precise control over a molecule's biological activity-encompassing targeted activation/inhibition, cooperative multi-target modulation, and off-target toxicity mitigation-remains a critical challenge in de novo drug design. However, existing generative methods primarily focus on producing molecules with a single desired activity, lacking integrated mechanisms for the simultaneous management of multiple intended and unintended molecular interactions. Here, we propose ActivityDiff, a generative approach based on the classifier-guidance technique of diffusion models. It leverages separately trained drug-target classifiers for both positive and negative guidance, enabling the model to enhance desired activities while minimizing harmful off-target effects. Experimental results show that ActivityDiff effectively handles essential drug design tasks, including single-/dual-target generation, fragment-constrained dual-target design, selective generation to enhance target specificity, and reduction of off-target effects. These results demonstrate the effectiveness of classifier-guided diffusion in balancing efficacy and safety in molecular design. Overall, our work introduces a novel paradigm for achieving integrated control over molecular activity, and provides ActivityDiff as a versatile and extensible framework.
AgREE: Agentic Reasoning for Knowledge Graph Completion on Emerging Entities
Aug 06, 2025Open-domain Knowledge Graph Completion (KGC) faces significant challenges in an ever-changing world, especially when considering the continual emergence of new entities in daily news. Existing approaches for KGC mainly rely on pretrained language models' parametric knowledge, pre-constructed queries, or single-step retrieval, typically requiring substantial supervision and training data. Even so, they often fail to capture comprehensive and up-to-date information about unpopular and/or emerging entities. To this end, we introduce Agentic Reasoning for Emerging Entities (AgREE), a novel agent-based framework that combines iterative retrieval actions and multi-step reasoning to dynamically construct rich knowledge graph triplets. Experiments show that, despite requiring zero training efforts, AgREE significantly outperforms existing methods in constructing knowledge graph triplets, especially for emerging entities that were not seen during language models' training processes, outperforming previous methods by up to 13.7%. Moreover, we propose a new evaluation methodology that addresses a fundamental weakness of existing setups and a new benchmark for KGC on emerging entities. Our work demonstrates the effectiveness of combining agent-based reasoning with strategic information retrieval for maintaining up-to-date knowledge graphs in dynamic information environments.