 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Asymptotic Global Convergence of PPO-Clip
Dec 18, 2025
Reinforcement learning (RL) has gained attention for aligning large language models (LLMs) via reinforcement learning from human feedback (RLHF). The actor-only variants of Proximal Policy Optimization (PPO) are widely applied for their efficiency. These algorithms incorporate a clipping mechanism to improve stability. Besides, a regularization term, such as the reverse KL-divergence or a more general \(f\)-divergence, is introduced to prevent policy drift. Despite their empirical success, a rigorous theoretical understanding of the problem and the algorithm's properties is limited. This paper advances the theoretical foundations of the PPO-Clip algorithm by analyzing a deterministic actor-only PPO algorithm within the general RL setting with \(f\)-divergence regularization under the softmax policy parameterization. We derive a non-uniform Lipschitz smoothness condition and a Łojasiewicz inequality for the considered problem. Based on these, a non-asymptotic linear convergence rate to the globally optimal policy is established for the forward KL-regularizer. Furthermore, stationary convergence and local linear convergence are derived for the reverse KL-regularizer.
Understanding Overparametrization in Survival Models through Interpolation
Dec 17, 2025Classical statistical learning theory predicts a U-shaped relationship between test loss and model capacity, driven by the bias-variance trade-off. Recent advances in modern machine learning have revealed a more complex pattern, \textit{double-descent}, in which test loss, after peaking near the interpolation threshold, decreases again as model capacity continues to grow. While this behavior has been extensively analyzed in regression and classification, its manifestation in survival analysis remains unexplored. This study investigates overparametrization in four representative survival models: DeepSurv, PC-Hazard, Nnet-Survival, and N-MTLR. We rigorously define \textit{interpolation} and \textit{finite-norm interpolation}, two key characteristics of loss-based models to understand \textit{double-descent}. We then show the existence (or absence) of \textit{(finite-norm) interpolation} of all four models. Our findings clarify how likelihood-based losses and model implementation jointly determine the feasibility of \textit{interpolation} and show that overparametrization should not be regarded as benign for survival models. All theoretical results are supported by numerical experiments that highlight the distinct generalization behaviors of survival models.
GateFuseNet: An Adaptive 3D Multimodal Neuroimaging Fusion Network for Parkinson's Disease Diagnosis
Oct 26, 2025Accurate diagnosis of Parkinson's disease (PD) from MRI remains challenging due to symptom variability and pathological heterogeneity. Most existing methods rely on conventional magnitude-based MRI modalities, such as T1-weighted images (T1w), which are less sensitive to PD pathology than Quantitative Susceptibility Mapping (QSM), a phase-based MRI technique that quantifies iron deposition in deep gray matter nuclei. In this study, we propose GateFuseNet, an adaptive 3D multimodal fusion network that integrates QSM and T1w images for PD diagnosis. The core innovation lies in a gated fusion module that learns modality-specific attention weights and channel-wise gating vectors for selective feature modulation. This hierarchical gating mechanism enhances ROI-aware features while suppressing irrelevant signals. Experimental results show that our method outperforms three existing state-of-the-art approaches, achieving 85.00% accuracy and 92.06% AUC. Ablation studies further validate the contributions of ROI guidance, multimodal integration, and fusion positioning. Grad-CAM visualizations confirm the model's focus on clinically relevant pathological regions. The source codes and pretrained models can be found at https://github.com/YangGaoUQ/GateFuseNet
SUSEP-Net: Simulation-Supervised and Contrastive Learning-based Deep Neural Networks for Susceptibility Source Separation
Jun 16, 2025Quantitative susceptibility mapping (QSM) provides a valuable tool for quantifying susceptibility distributions in human brains; however, two types of opposing susceptibility sources (i.e., paramagnetic and diamagnetic), may coexist in a single voxel, and cancel each other out in net QSM images. Susceptibility source separation techniques enable the extraction of sub-voxel information from QSM maps. This study proposes a novel SUSEP-Net for susceptibility source separation by training a dual-branch U-net with a simulation-supervised training strategy. In addition, a contrastive learning framework is included to explicitly impose similarity-based constraints between the branch-specific guidance features in specially-designed encoders and the latent features in the decoders. Comprehensive experiments were carried out on both simulated and in vivo data, including healthy subjects and patients with pathological conditions, to compare SUSEP-Net with three state-of-the-art susceptibility source separation methods (i.e., APART-QSM, \c{hi}-separation, and \c{hi}-sepnet). SUSEP-Net consistently showed improved results compared with the other three methods, with better numerical metrics, improved high-intensity hemorrhage and calcification lesion contrasts, and reduced artifacts in brains with pathological conditions. In addition, experiments on an agarose gel phantom data were conducted to validate the accuracy and the generalization capability of SUSEP-Net.
A Memory Efficient Randomized Subspace Optimization Method for Training Large Language Models
Feb 11, 2025The memory challenges associated with training Large Language Models (LLMs) have become a critical concern, particularly when using the Adam optimizer. To address this issue, numerous memory-efficient techniques have been proposed, with GaLore standing out as a notable example designed to reduce the memory footprint of optimizer states. However, these approaches do not alleviate the memory burden imposed by activations, rendering them unsuitable for scenarios involving long context sequences or large mini-batches. Moreover, their convergence properties are still not well-understood in the literature. In this work, we introduce a Randomized Subspace Optimization framework for pre-training and fine-tuning LLMs. Our approach decomposes the high-dimensional training problem into a series of lower-dimensional subproblems. At each iteration, a random subspace is selected, and the parameters within that subspace are optimized. This structured reduction in dimensionality allows our method to simultaneously reduce memory usage for both activations and optimizer states. We establish comprehensive convergence guarantees and derive rates for various scenarios, accommodating different optimization strategies to solve the subproblems. Extensive experiments validate the superior memory and communication efficiency of our method, achieving performance comparable to GaLore and Adam.
Derivative-Free Optimization for Low-Rank Adaptation in Large Language Models
Mar 04, 2024
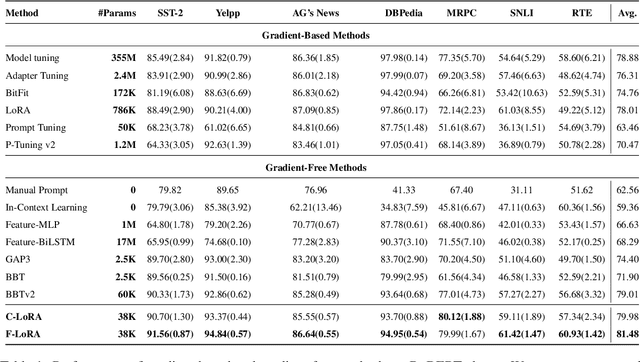

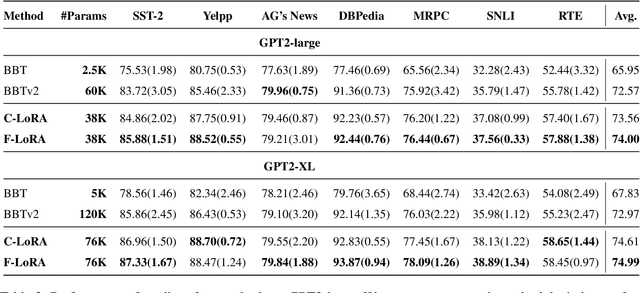
Parameter-efficient tuning methods such as LoRA could achieve comparable performance to model tuning by tuning a small portion of the parameters. However, substantial computational resources are still required, as this process involves calculating gradients and performing back-propagation throughout the model. Much effort has recently been devoted to utilizing the derivative-free optimization method to eschew the computation of gradients and showcase an augmented level of robustness in few-shot settings. In this paper, we prepend the low-rank modules into each self-attention layer of the model and employ two derivative-free optimization methods to optimize these low-rank modules at each layer alternately. Extensive results on various tasks and language models demonstrate that our proposed method achieves substantial improvement and exhibits clear advantages in memory usage and convergence speed compared to existing gradient-based parameter-efficient tuning and derivative-free optimization methods in few-shot settings.
Plug-and-Play Latent Feature Editing for Orientation-Adaptive Quantitative Susceptibility Mapping Neural Networks
Nov 14, 2023Quantitative susceptibility mapping (QSM) is a post-processing technique for deriving tissue magnetic susceptibility distribution from MRI phase measurements. Deep learning (DL) algorithms hold great potential for solving the ill-posed QSM reconstruction problem. However, a significant challenge facing current DL-QSM approaches is their limited adaptability to magnetic dipole field orientation variations during training and testing. In this work, we propose a novel Orientation-Adaptive Latent Feature Editing (OA-LFE) module to learn the encoding of acquisition orientation vectors and seamlessly integrate them into the latent features of deep networks. Importantly, it can be directly Plug-and-Play (PnP) into various existing DL-QSM architectures, enabling reconstructions of QSM from arbitrary magnetic dipole orientations. Its effectiveness is demonstrated by combining the OA-LFE module into our previously proposed phase-to-susceptibility single-step instant QSM (iQSM) network, which was initially tailored for pure-axial acquisitions. The proposed OA-LFE-empowered iQSM, which we refer to as iQSM+, is trained in a self-supervised manner on a specially-designed simulation brain dataset. Comprehensive experiments are conducted on simulated and in vivo human brain datasets, encompassing subjects ranging from healthy individuals to those with pathological conditions. These experiments involve various MRI platforms (3T and 7T) and aim to compare our proposed iQSM+ against several established QSM reconstruction frameworks, including the original iQSM. The iQSM+ yields QSM images with significantly improved accuracies and mitigates artifacts, surpassing other state-of-the-art DL-QSM algorithms.
Quantitative Susceptibility Mapping through Model-based Deep Image Prior (MoDIP)
Aug 18, 2023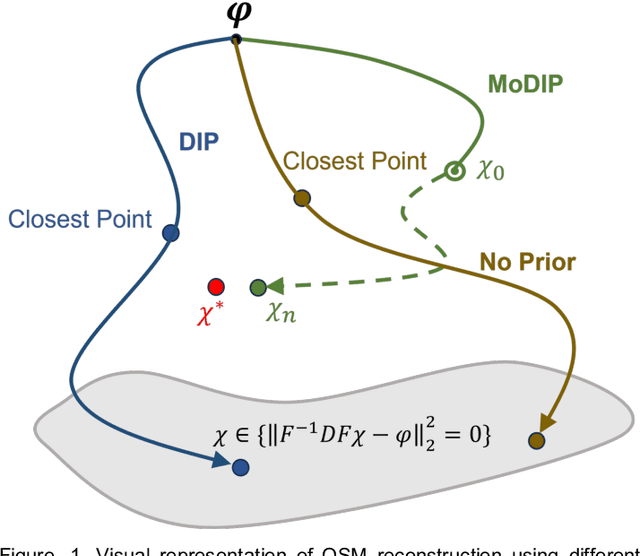
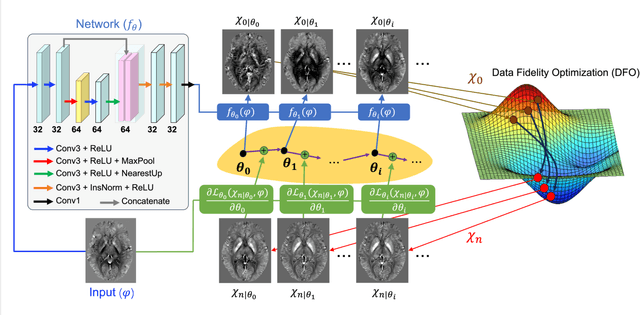
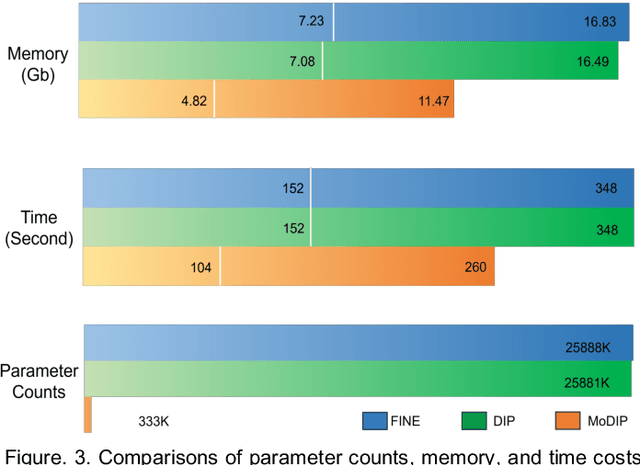
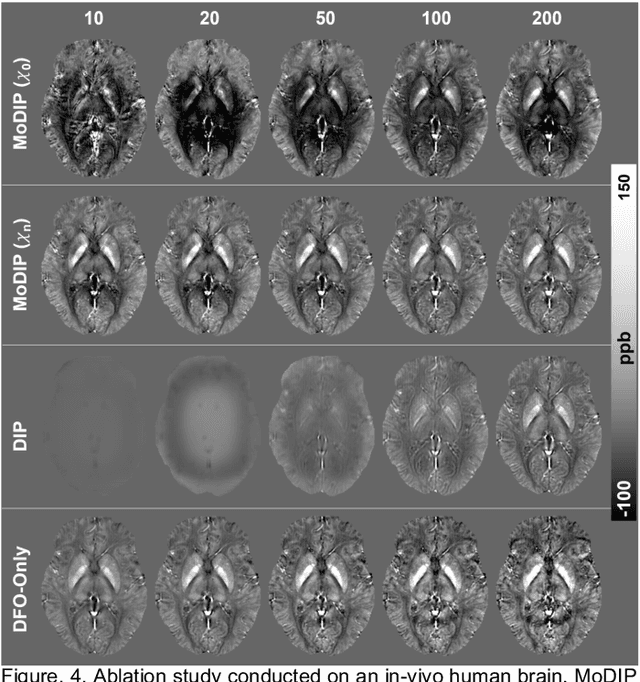
The data-driven approach of supervised learning methods has limited applicability in solving dipole inversion in Quantitative Susceptibility Mapping (QSM) with varying scan parameters across different objects. To address this generalization issue in supervised QSM methods, we propose a novel training-free model-based unsupervised method called MoDIP (Model-based Deep Image Prior). MoDIP comprises a small, untrained network and a Data Fidelity Optimization (DFO) module. The network converges to an interim state, acting as an implicit prior for image regularization, while the optimization process enforces the physical model of QSM dipole inversion. Experimental results demonstrate MoDIP's excellent generalizability in solving QSM dipole inversion across different scan parameters. It exhibits robustness against pathological brain QSM, achieving over 32% accuracy improvement than supervised deep learning and traditional iterative methods. It is also 33% more computationally efficient and runs 4 times faster than conventional DIP-based approaches, enabling 3D high-resolution image reconstruction in under 4.5 minutes.
Associating Multi-Scale Receptive Fields for Fine-grained Recognition
May 19, 2020



Extracting and fusing part features have become the key of fined-grained image recognition. Recently, Non-local (NL) module has shown excellent improvement in image recognition. However, it lacks the mechanism to model the interactions between multi-scale part features, which is vital for fine-grained recognition. In this paper, we propose a novel cross-layer non-local (CNL) module to associate multi-scale receptive fields by two operations. First, CNL computes correlations between features of a query layer and all response layers. Second, all response features are weighted according to the correlations and are added to the query features. Due to the interactions of cross-layer features, our model builds spatial dependencies among multi-level layers and learns more discriminative features. In addition, we can reduce the aggregation cost if we set low-dimensional deep layer as query layer. Experiments are conducted to show our model achieves or surpasses state-of-the-art results on three benchmark datasets of fine-grained classification. Our codes can be found at github.com/FouriYe/CNL-ICIP2020.