 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivative-Free Optimization for Low-Rank Adaptation in Large Language Models
Paper and Code

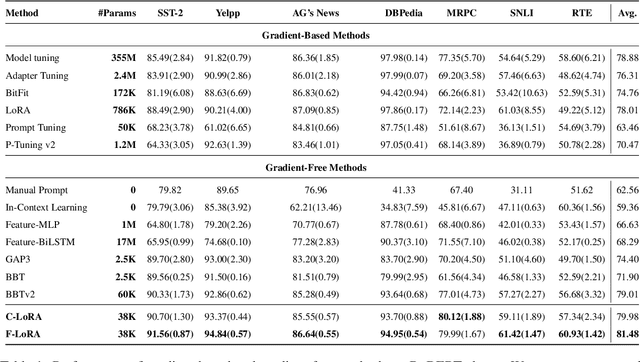

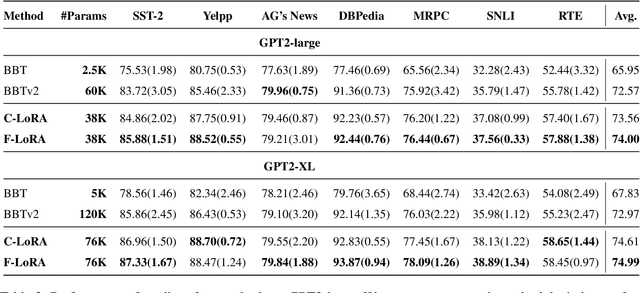
Parameter-efficient tuning methods such as LoRA could achieve comparable performance to model tuning by tuning a small portion of the parameters. However, substantial computational resources are still required, as this process involves calculating gradients and performing back-propagation throughout the model. Much effort has recently been devoted to utilizing the derivative-free optimization method to eschew the computation of gradients and showcase an augmented level of robustness in few-shot settings. In this paper, we prepend the low-rank modules into each self-attention layer of the model and employ two derivative-free optimization methods to optimize these low-rank modules at each layer alternately. Extensive results on various tasks and language models demonstrate that our proposed method achieves substantial improvement and exhibits clear advantages in memory usage and convergence speed compared to existing gradient-based parameter-efficient tuning and derivative-free optimization methods in few-shot settings.