 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Informed Zeroth-Order Optimization with Adaptive Direction Alignment for Memory-Efficient LLM Fine-Tuning
Jan 08, 2026Fine-tuning large language models (LLMs) has achieved remarkable success across various NLP tasks, but the substantial memory overhead during backpropagation remains a critical bottleneck, especially as model scales grow. Zeroth-order (ZO) optimization alleviates this issue by estimating gradients through forward passes and Gaussian sampling, avoiding the need for backpropagation. However, conventional ZO methods suffer from high variance in gradient estimation due to their reliance on random perturbations, leading to slow convergence and suboptimal performance. We propose a simple plug-and-play method that incorporates prior-informed perturbations to refine gradient estimation. Our method dynamically computes a guiding vector from Gaussian samples, which directs perturbations toward more informative directions, significantly accelerating convergence compared to standard ZO approaches. We further investigate a greedy perturbation strategy to explore the impact of prior knowledge on gradient estimation. Theoretically, we prove that our gradient estimator achieves stronger alignment with the true gradient direction, enhancing optimization efficiency. Extensive experiments across LLMs of varying scales and architectures demonstrate that our proposed method could seamlessly integrate into existing optimization methods, delivering faster convergence and superior performance. Notably, on the OPT-13B model, our method outperforms traditional ZO optimization across all 11 benchmark tasks and surpasses gradient-based baselines on 9 out of 11 tasks, establishing a robust balance between efficiency and accuracy.
Beyond Algorithm Evolution: An LLM-Driven Framework for the Co-Evolution of Swarm Intelligence Optimization Algorithms and Prompts
Dec 10, 2025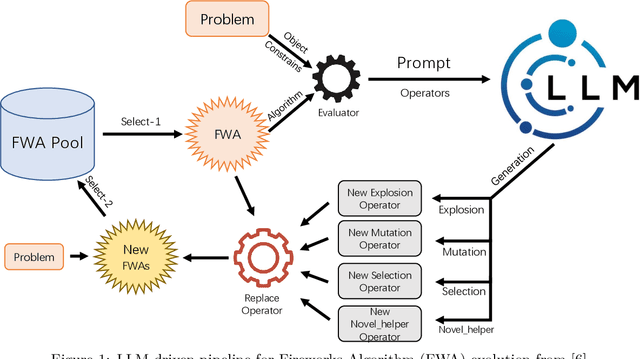

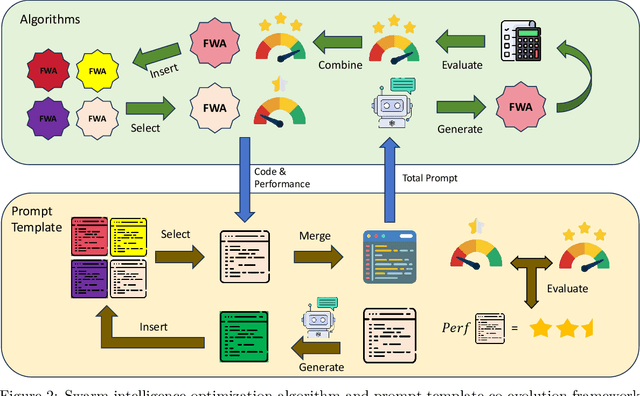

The field of automated algorithm design has been advanced by frameworks such as EoH, FunSearch, and Reevo. Yet, their focus on algorithm evolution alone, neglecting the prompts that guide them, limits their effectiveness with LLMs, especially in complex, uncertain environments where they nonetheless implicitly rely on strategies from swarm intelligence optimization algorithms. Recognizing this, we argue that swarm intelligence optimization provides a more generalized and principled foundation for automated design. Consequently, this paper proposes a novel framework for the collaborative evolution of both swarm intelligence algorithms and guiding prompts using a single LLM. To enhance interpretability, we also propose a simple yet efficient evaluation method for prompt templates. The framework was rigorously evaluated on a range of NP problems, where it demonstrated superior performance compared to several state-of-the-art automated design approaches. Experiments with various LLMs (e.g., GPT-4o-mini, Qwen3-32B, GPT-5) reveal significantly divergent evolutionary trajectories in the generated prompts, further underscoring the necessity of a structured co-evolution framework. Importantly, our approach maintains leading performance across different models, demonstrating reduced reliance on the most powerful LLMs and enabling more cost-effective deployments. Ablation studies and in-depth analysis of the evolved prompts confirm that collaborative evolution is essential for achieving optimal performance. Our work establishes a new paradigm for swarm intelligence optimization algorithms, underscoring the indispensable role of prompt evolution.
Prospect Theory in Physical Human-Robot Interaction: A Pilot Study of Probability Perception
Dec 09, 2025Understanding how humans respond to uncertainty is critical for designing safe and effective physical human-robot interaction (pHRI), as physically working with robots introduces multiple sources of uncertainty, including trust, comfort, and perceived safety. Conventional pHRI control frameworks typically build on optimal control theory, which assumes that human actions minimize a cost function; however, human behavior under uncertainty often departs from such optimal patterns. To address this gap, additional understanding of human behavior under uncertainty is needed. This pilot study implemented a physically coupled target-reaching task in which the robot delivered assistance or disturbances with systematically varied probabilities (10\% to 90\%). Analysis of participants' force inputs and decision-making strategies revealed two distinct behavioral clusters: a "trade-off" group that modulated their physical responses according to disturbance likelihood, and an "always-compensate" group characterized by strong risk aversion irrespective of probability. These findings provide empirical evidence that human decision-making in pHRI is highly individualized and that the perception of probability can differ to its true value. Accordingly, the study highlights the need for more interpretable behavioral models, such as cumulative prospect theory (CPT), to more accurately capture these behaviors and inform the design of future adaptive robot controllers.
MS-UMamba: An Improved Vision Mamba Unet for Fetal Abdominal Medical Image Segmentation
Jun 14, 2025Recently, Mamba-based methods have become popular in medical image segmentation due to their lightweight design and long-range dependency modeling capabilities. However, current segmentation methods frequently encounter challenges in fetal ultrasound images, such as enclosed anatomical structures, blurred boundaries, and small anatomical structures. To address the need for balancing local feature extraction and global context modeling, we propose MS-UMamba, a novel hybrid convolutional-mamba model for fetal ultrasound image segmentation. Specifically, we design a visual state space block integrated with a CNN branch (SS-MCAT-SSM), which leverages Mamba's global modeling strengths and convolutional layers' local representation advantages to enhance feature learning. In addition, we also propose an efficient multi-scale feature fusion module that integrates spatial attention mechanisms, which Integrating feature information from different layers enhances the feature representation ability of the model. Finally, we conduct extensive experiments on a non-public dataset, experimental results demonstrate that MS-UMamba model has excellent performance in segmentation performance.
DCD: A Semantic Segmentation Model for Fetal Ultrasound Four-Chamber View
Jun 10, 2025Accurate segmentation of anatomical structures in the apical four-chamber (A4C) view of fetal echocardiography is essential for early diagnosis and prenatal evaluation of congenital heart disease (CHD). However, precise segmentation remains challenging due to ultrasound artifacts, speckle noise, anatomical variability, and boundary ambiguity across different gestational stages. To reduce the workload of sonographers and enhance segmentation accuracy, we propose DCD, an advanced deep learning-based model for automatic segmentation of key anatomical structures in the fetal A4C view. Our model incorporates a Dense Atrous Spatial Pyramid Pooling (Dense ASPP) module, enabling superior multi-scale feature extraction, and a Convolutional Block Attention Module (CBAM) to enhance adaptive feature representation. By effectively capturing both local and global contextual information, DCD achieves precise and robust segmentation, contributing to improved prenatal cardiac assessment.
FAMSeg: Fetal Femur and Cranial Ultrasound Segmentation Using Feature-Aware Attention and Mamba Enhancement
Jun 09, 2025Accurate ultrasound image segmentation is a prerequisite for precise biometrics and accurate assessment. Relying on manual delineation introduces significant errors and is time-consuming. However, existing segmentation models are designed based on objects in natural scenes, making them difficult to adapt to ultrasound objects with high noise and high similarity. This is particularly evident in small object segmentation, where a pronounced jagged effect occurs. Therefore, this paper proposes a fetal femur and cranial ultrasound image segmentation model based on feature perception and Mamba enhancement to address these challenges. Specifically, a longitudinal and transverse independent viewpoint scanning convolution block and a feature perception module were designed to enhance the ability to capture local detail information and improve the fusion of contextual information. Combined with the Mamba-optimized residual structure, this design suppresses the interference of raw noise and enhances local multi-dimensional scanning. The system builds global information and local feature dependencies, and is trained with a combination of different optimizers to achieve the optimal solution. After extensive experimental validation, the FAMSeg network achieved the fastest loss reduction and the best segmentation performance across images of varying sizes and orientations.
Repetitive Contrastive Learning Enhances Mamba's Selectivity in Time Series Prediction
Apr 12, 2025Long sequence prediction is a key challenge in time series forecasting. While Mamba-based models have shown strong performance due to their sequence selection capabilities, they still struggle with insufficient focus on critical time steps and incomplete noise suppression, caused by limited selective abilities. To address this, we introduce Repetitive Contrastive Learning (RCL), a token-level contrastive pretraining framework aimed at enhancing Mamba's selective capabilities. RCL pretrains a single Mamba block to strengthen its selective abilities and then transfers these pretrained parameters to initialize Mamba blocks in various backbone models, improving their temporal prediction performance. RCL uses sequence augmentation with Gaussian noise and applies inter-sequence and intra-sequence contrastive learning to help the Mamba module prioritize information-rich time steps while ignoring noisy ones. Extensive experiments show that RCL consistently boosts the performance of backbone models, surpassing existing methods and achieving state-of-the-art results. Additionally, we propose two metrics to quantify Mamba's selective capabilities, providing theoretical, qualitative, and quantitative evidence for the improvements brought by RCL.
Exploring Interference between Concurrent Skin Stretches
Mar 26, 2025Proprioception is essential for coordinating human movements and enhancing the performance of assistive robotic devices. Skin stretch feedback, which closely aligns with natural proprioception mechanisms, presents a promising method for conveying proprioceptive information. To better understand the impact of interference on skin stretch perception, we conducted a user study with 30 participants that evaluated the effect of two simultaneous skin stretches on user perception. We observed that when participants experience simultaneous skin stretch stimuli, a masking effect occurs which deteriorates perception performance in the collocated skin stretch configurations. However, the perceived workload stays the same. These findings show that interference can affect the perception of skin stretch such that multi-channel skin stretch feedback designs should avoid locating modules in close proximity.
Hierarchical Information-Guided Spatio-Temporal Mamba for Stock Time Series Forecasting
Mar 14, 2025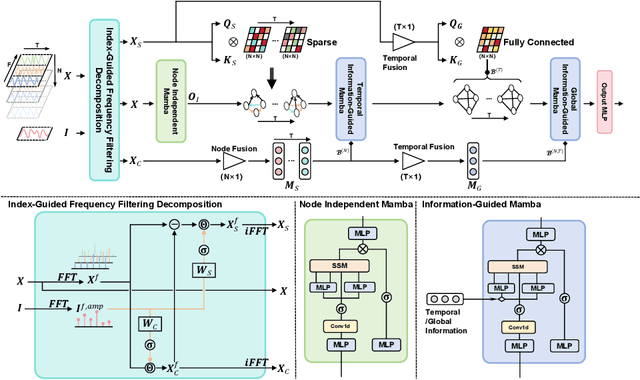


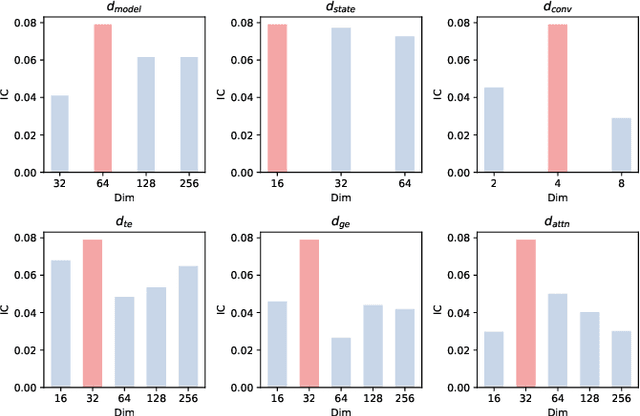
Mamba has demonstrated excellent performance in various time series forecasting tasks due to its superior selection mechanism. Nevertheless, conventional Mamba-based models encounter significant challenges in accurately predicting stock time series, as they fail to adequately capture both the overarching market dynamics and the intricate interdependencies among individual stocks. To overcome these constraints, we introduce the Hierarchical Information-Guided Spatio-Temporal Mamba (HIGSTM) framework. HIGSTM introduces Index-Guided Frequency Filtering Decomposition to extract commonality and specificity from time series. The model architecture features a meticulously designed hierarchical framework that systematically captures both temporal dynamic patterns and global static relationships within the stock market. Furthermore, we propose an Information-Guided Mamba that integrates macro informations into the sequence selection process, thereby facilitating more market-conscious decision-making. Comprehensive experimental evaluations conducted on the CSI500, CSI800 and CSI1000 datasets demonstrate that HIGSTM achieves state-of-the-art performance.
A GPU Implementation of Multi-Guiding Spark Fireworks Algorithm for Efficient Black-Box Neural Network Optimization
Jan 07, 2025
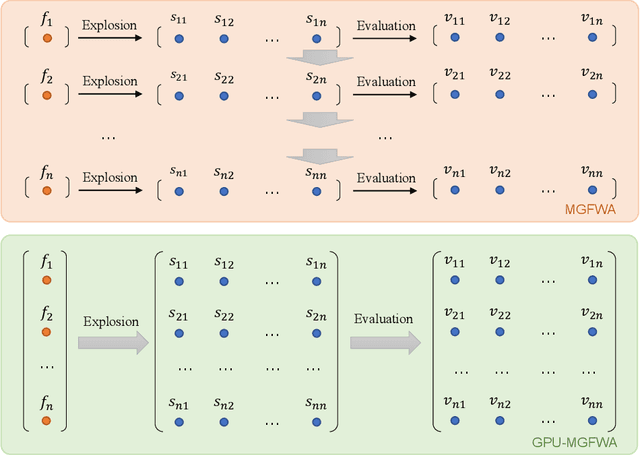

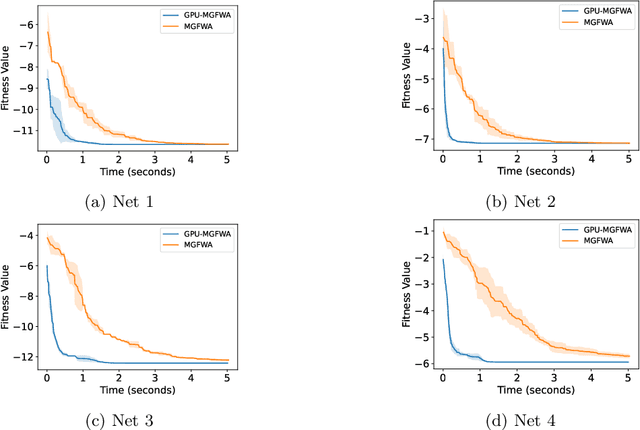
Swarm intelligence optimization algorithms have gained significant attention due to their ability to solve complex optimization problems. However, the efficiency of optimization in large-scale problems limits the use of related methods. This paper presents a GPU-accelerated version of the Multi-Guiding Spark Fireworks Algorithm (MGFWA), which significantly improves the computational efficiency compared to its traditional CPU-based counterpart. We benchmark the GPU-MGFWA on several neural network black-box optimization problems and demonstrate its superior performance in terms of both speed and solution quality. By leveraging the parallel processing power of modern GPUs, the proposed GPU-MGFWA results in faster convergence and reduced computation time for large-scale optimization tasks. The proposed implementation offers a promising approach to accelerate swarm intelligence algorithms, making them more suitable for real-time applications and large-scale industrial problems. Source code is released at https://github.com/mxxxr/MGFWA.