 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI-assisted Participatory Modeling in Socio-Environmental Planning under Deep Uncertainty
Mar 17, 2026Socio-environmental planning under deep uncertainty requires researchers to identify and conceptualize problems before exploring policies and deploying plans. In practice and model-based planning approaches, this problem conceptualization process often relies on participatory modeling to translate stakeholders' natural-language descriptions into a quantitative model, making this process complex and time-consuming. To facilitate this process, we propose a templated workflow that uses large language models for an initial conceptualization process. During the workflow, researchers can use large language models to identify the essential model components from stakeholders' intuitive problem descriptions, explore their diverse perspectives approaching the problem, assemble these components into a unified model, and eventually implement the model in Python through iterative communication. These results will facilitate the subsequent socio-environmental planning under deep uncertainty steps. Using ChatGPT 5.2 Instant, we demonstrated this workflow on the lake problem and an electricity market problem, both of which demonstrate socio-environmental planning problems. In both cases, acceptable outputs were obtained after a few iterations with human verification and refinement. These experiments indicated that large language models can serve as an effective tool for facilitating participatory modeling in the problem conceptualization process in socio-environmental planning.
Planning as Goal Recognition: Deriving Heuristics from Intention Models - Extended Version
Mar 16, 2026Classical planning aims to find a sequence of actions, a plan, that maps a starting state into one of the goal states. If a trajectory appears to be leading to the goal, should we prioritise exploring it? Seminal work in goal recognition (GR) has defined GR in terms of a classical planning problem, adopting classical solvers and heuristics to recognise plans. We come full circle, and study the adoption and properties of GR-derived heuristics for seeking solutions to classical planning problems. We propose a new framework for assessing goal intention, which informs a new class of efficiently-computable heuristics. As a proof of concept, we derive two such heuristics, and show that they can already yield improvements for top-scoring classical planners. Our work provides foundational knowledge for understanding and deriving probabilistic intention-based heuristics for planning.
From Reasoning to Generalization: Knowledge-Augmented LLMs for ARC Benchmark
May 23, 2025Recent reasoning-oriented LLMs have demonstrated strong performance on challenging tasks such as mathematics and science examinations. However, core cognitive faculties of human intelligence, such as abstract reasoning and generalization, remain underexplored. To address this, we evaluate recent reasoning-oriented LLMs on the Abstraction and Reasoning Corpus (ARC) benchmark, which explicitly demands both faculties. We formulate ARC as a program synthesis task and propose nine candidate solvers. Experimental results show that repeated-sampling planning-aided code generation (RSPC) achieves the highest test accuracy and demonstrates consistent generalization across most LLMs. To further improve performance, we introduce an ARC solver, Knowledge Augmentation for Abstract Reasoning (KAAR), which encodes core knowledge priors within an ontology that classifies priors into three hierarchical levels based on their dependencies. KAAR progressively expands LLM reasoning capacity by gradually augmenting priors at each level, and invokes RSPC to generate candidate solutions after each augmentation stage. This stage-wise reasoning reduces interference from irrelevant priors and improves LLM performance. Empirical results show that KAAR maintains strong generalization and consistently outperforms non-augmented RSPC across all evaluated LLMs, achieving around 5% absolute gains and up to 64.52% relative improvement. Despite these achievements, ARC remains a challenging benchmark for reasoning-oriented LLMs, highlighting future avenues of progress in LLMs.
State-Based Disassembly Planning
Jan 09, 2025



It has been shown recently that physics-based simulation significantly enhances the disassembly capabilities of real-world assemblies with diverse 3D shapes and stringent motion constraints. However, the efficiency suffers when tackling intricate disassembly tasks that require numerous simulations and increased simulation time. In this work, we propose a State-Based Disassembly Planning (SBDP) approach, prioritizing physics-based simulation with translational motion over rotational motion to facilitate autonomy, reducing dependency on human input, while storing intermediate motion states to improve search scalability. We introduce two novel evaluation functions derived from new Directional Blocking Graphs (DBGs) enriched with state information to scale up the search. Our experiments show that SBDP with new evaluation functions and DBGs constraints outperforms the state-of-the-art in disassembly planning in terms of success rate and computational efficiency over benchmark datasets consisting of thousands of physically valid industrial assemblies.
Chasing Progress, Not Perfection: Revisiting Strategies for End-to-End LLM Plan Generation
Dec 14, 2024The capability of Large Language Models (LLMs) to plan remains a topic of debate. Some critics argue that strategies to boost LLMs' reasoning skills are ineffective in planning tasks, while others report strong outcomes merely from training models on a planning corpus. This study reassesses recent strategies by developing an end-to-end LLM planner and employing diverse metrics for a thorough evaluation. We find that merely fine-tuning LLMs on a corpus of planning instances does not lead to robust planning skills, as indicated by poor performance on out-of-distribution test sets. At the same time, we find that various strategies, including Chain-of-Thought, do enhance the probability of a plan being executable. This indicates progress towards better plan quality, despite not directly enhancing the final validity rate. Among the strategies we evaluated, reinforcement learning with our novel `Longest Contiguous Common Subsequence' reward emerged as the most effective, contributing to both plan validity and executability. Overall, our research addresses key misconceptions in the LLM-planning literature; we validate incremental progress in plan executability, although plan validity remains a challenge. Hence, future strategies should focus on both these aspects, drawing insights from our findings.
Where Common Knowledge Cannot Be Formed, Common Belief Can -- Planning with Multi-Agent Belief Using Group Justified Perspectives
Dec 10, 2024Epistemic planning is the sub-field of AI planning that focuses on changing knowledge and belief. It is important in both multi-agent domains where agents need to have knowledge/belief regarding the environment, but also the beliefs of other agents, including nested beliefs. When modeling knowledge in multi-agent settings, many models face an exponential growth challenge in terms of nested depth. A contemporary method, known as Planning with Perspectives (PWP), addresses these challenges through the use of perspectives and set operations for knowledge. The JP model defines that an agent's belief is justified if and only if the agent has seen evidence that this belief was true in the past and has not seen evidence to suggest that this has changed. The current paper extends the JP model to handle \emph{group belief}, including distributed belief and common belief. We call this the Group Justified Perspective (GJP) model. Using experimental problems crafted by adapting well-known benchmarks to a group setting, we show the efficiency and expressiveness of our GJP model at handling planning problems that cannot be handled by other epistemic planning tools.
Planning-Driven Programming: A Large Language Model Programming Workflow
Nov 21, 2024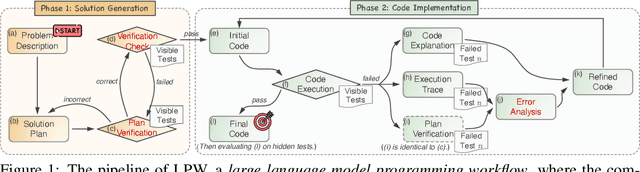
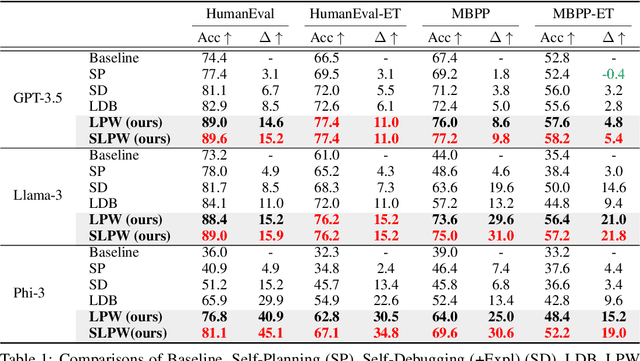


The strong performance of large language models (LLMs) on natural language processing tasks raises extensive discussion on their application to code generation. Recent work suggests multiple sampling approaches to improve initial code generation accuracy or program repair approaches to refine the code. However, these methods suffer from LLMs' inefficiencies and limited reasoning capacity. In this work, we propose an LLM programming workflow (LPW) designed to improve both initial code generation and subsequent refinements within a structured two-phase workflow. Specifically, in the solution generation phase, the LLM first outlines a solution plan that decomposes the problem into manageable sub-problems and then verifies the generated solution plan through visible test cases. Subsequently, in the code implementation phase, the LLM initially drafts a code according to the solution plan and its verification. If the generated code fails the visible tests, the plan verification serves as the intended natural language solution to inform the refinement process for correcting bugs. We further introduce SLPW, a sampling variant of LPW, which initially generates multiple solution plans and plan verifications, produces a program for each plan and its verification, and refines each program as necessary until one successfully passes the visible tests. Compared to the state-of-the-art methods across various existing LLMs, our experimental results show that LPW significantly improves the Pass@1 accuracy by up to 16.4% on well-established text-to-code generation benchmarks, especially with a notable improvement of around 10% on challenging benchmarks. Additionally, SLPW demonstrates up to a 5.6% improvement over LPW and sets new state-of-the-art Pass@1 accuracy on various benchmarks, e.g., 98.2% on HumanEval, 84.8% on MBPP, 64.0% on APPS, and 35.3% on CodeContest, using GPT-4o as the backbone.
Overcoming Reward Model Noise in Instruction-Guided Reinforcement Learning
Sep 24, 2024



Vision-language models (VLMs) have gained traction as auxiliary reward models to provide more informative reward signals in sparse reward environments. However, our work reveals a critical vulnerability of this method: a small amount of noise in the reward signal can severely degrade agent performance. In challenging environments with sparse rewards, we show that reinforcement learning agents using VLM-based reward models without proper noise handling perform worse than agents relying solely on exploration-driven methods. We hypothesize that false positive rewards -- where the reward model incorrectly assigns rewards to trajectories that do not fulfill the given instruction -- are more detrimental to learning than false negatives. Our analysis confirms this hypothesis, revealing that the widely used cosine similarity metric, when applied to comparing agent trajectories and language instructions, is prone to generating false positive reward signals. To address this, we introduce BiMI (Binary Mutual Information), a novel noise-resilient reward function. Our experiments demonstrate that, BiMI significantly boosts the agent performance, with an average improvement ratio of 44.5\% across diverse environments with learned, non-oracle VLMs, thereby making VLM-based reward models practical for real-world applications.
Planning in the Dark: LLM-Symbolic Planning Pipeline without Experts
Sep 24, 2024Large Language Models (LLMs) have shown promise in solving natural language-described planning tasks, but their direct use often leads to inconsistent reasoning and hallucination. While hybrid LLM-symbolic planning pipelines have emerged as a more robust alternative, they typically require extensive expert intervention to refine and validate generated action schemas. It not only limits scalability but also introduces a potential for biased interpretation, as a single expert's interpretation of ambiguous natural language descriptions might not align with the user's actual intent. To address this, we propose a novel approach that constructs an action schema library to generate multiple candidates, accounting for the diverse possible interpretations of natural language descriptions. We further introduce a semantic validation and ranking module that automatically filter and rank the generated schemas and plans without expert-in-the-loop. The experiments showed our pipeline maintains superiority in planning over the direct LLM planning approach. These findings demonstrate the feasibility of a fully automated end-to-end LLM-symbolic planner that requires no expert intervention, opening up the possibility for a broader audience to engage with AI planning with less prerequisite of domain expertise.
Count-based Novelty Exploration in Classical Planning
Aug 25, 2024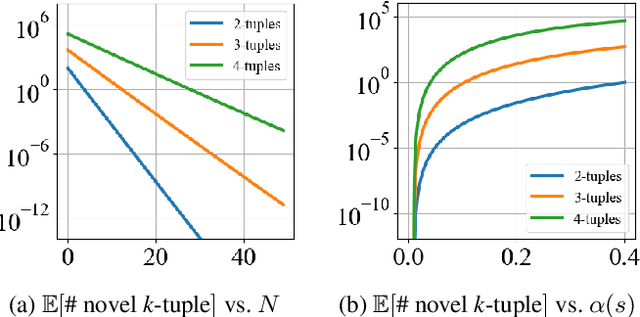
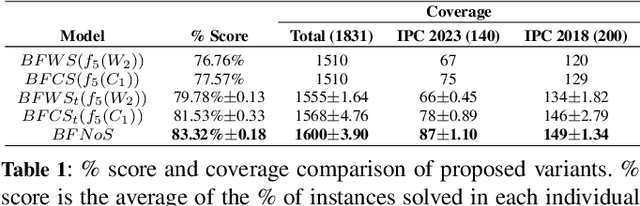
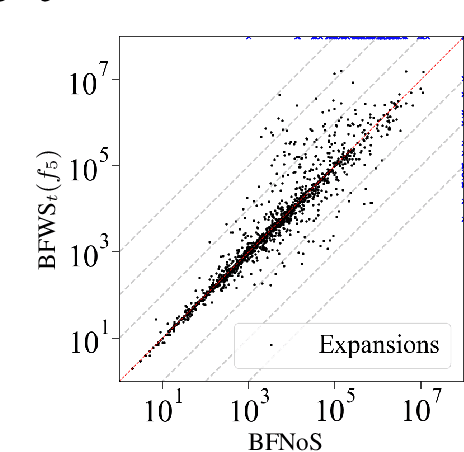

Count-based exploration methods are widely employed to improve the exploratory behavior of learning agents over sequential decision problems. Meanwhile, Novelty search has achieved success in Classical Planning through recording of the first, but not successive, occurrences of tuples. In order to structure the exploration, however, the number of tuples considered needs to grow exponentially as the search progresses. We propose a new novelty technique, classical count-based novelty, which aims to explore the state space with a constant number of tuples, by leveraging the frequency of each tuple's appearance in a search tree. We then justify the mechanisms through which lower tuple counts lead the search towards novel tuples. We also introduce algorithmic contributions in the form of a trimmed open list that maintains a constant size by pruning nodes with bad novelty values. These techniques are shown to complement existing novelty heuristics when integrated in a classical solver, achieving competitive results in challenging benchmarks from recent International Planning Competitions. Moreover, adapting our solver as the frontend planner in dual configurations that utilize both memory and time thresholds demonstrates a significant increase in instance coverage, surpassing current state-of-the-art solvers.