 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Data-Frame Dynamics in AI-assisted Decision Making
Apr 22, 2025High stakes decision-making often requires a continuous interplay between evolving evidence and shifting hypotheses, a dynamic that is not well supported by current AI decision support systems. In this paper, we introduce a mixed-initiative framework for AI assisted decision making that is grounded in the data-frame theory of sensemaking and the evaluative AI paradigm. Our approach enables both humans and AI to collaboratively construct, validate, and adapt hypotheses. We demonstrate our framework with an AI-assisted skin cancer diagnosis prototype that leverages a concept bottleneck model to facilitate interpretable interactions and dynamic updates to diagnostic hypotheses.
* Presented at the 2025 ACM Workshop on Human-AI Interaction for Augmented Reasoning, Report Number: CHI25-WS-AUGMENTED-REASONING
Exploring Explainable Multi-player MCTS-minimax Hybrids in Board Game Using Process Mining
Mar 30, 2025



Monte-Carlo Tree Search (MCTS) is a family of sampling-based search algorithms widely used for online planning in sequential decision-making domains and at the heart of many recent advances in artificial intelligence. Understanding the behavior of MCTS agents is difficult for developers and users due to the frequently large and complex search trees that result from the simulation of many possible futures, their evaluations, and their relationships. This paper presents our ongoing investigation into potential explanations for the decision-making and behavior of MCTS. A weakness of MCTS is that it constructs a highly selective tree and, as a result, can miss crucial moves and fall into tactical traps. Full-width minimax search constitutes the solution. We integrate shallow minimax search into the rollout phase of multi-player MCTS and use process mining technique to explain agents' strategies in 3v3 checkers.
Where Common Knowledge Cannot Be Formed, Common Belief Can -- Planning with Multi-Agent Belief Using Group Justified Perspectives
Dec 10, 2024Epistemic planning is the sub-field of AI planning that focuses on changing knowledge and belief. It is important in both multi-agent domains where agents need to have knowledge/belief regarding the environment, but also the beliefs of other agents, including nested beliefs. When modeling knowledge in multi-agent settings, many models face an exponential growth challenge in terms of nested depth. A contemporary method, known as Planning with Perspectives (PWP), addresses these challenges through the use of perspectives and set operations for knowledge. The JP model defines that an agent's belief is justified if and only if the agent has seen evidence that this belief was true in the past and has not seen evidence to suggest that this has changed. The current paper extends the JP model to handle \emph{group belief}, including distributed belief and common belief. We call this the Group Justified Perspective (GJP) model. Using experimental problems crafted by adapting well-known benchmarks to a group setting, we show the efficiency and expressiveness of our GJP model at handling planning problems that cannot be handled by other epistemic planning tools.
Evaluating Explanations Through LLMs: Beyond Traditional User Studies
Oct 23, 2024



As AI becomes fundamental in sectors like healthcare, explainable AI (XAI) tools are essential for trust and transparency. However, traditional user studies used to evaluate these tools are often costly, time consuming, and difficult to scale. In this paper, we explore the use of Large Language Models (LLMs) to replicate human participants to help streamline XAI evaluation. We reproduce a user study comparing counterfactual and causal explanations, replicating human participants with seven LLMs under various settings. Our results show that (i) LLMs can replicate most conclusions from the original study, (ii) different LLMs yield varying levels of alignment in the results, and (iii) experimental factors such as LLM memory and output variability affect alignment with human responses. These initial findings suggest that LLMs could provide a scalable and cost-effective way to simplify qualitative XAI evaluation.
Towards Explainable Goal Recognition Using Weight of Evidence (WoE): A Human-Centered Approach
Sep 18, 2024



Goal recognition (GR) involves inferring an agent's unobserved goal from a sequence of observations. This is a critical problem in AI with diverse applications. Traditionally, GR has been addressed using 'inference to the best explanation' or abduction, where hypotheses about the agent's goals are generated as the most plausible explanations for observed behavior. Alternatively, some approaches enhance interpretability by ensuring that an agent's behavior aligns with an observer's expectations or by making the reasoning behind decisions more transparent. In this work, we tackle a different challenge: explaining the GR process in a way that is comprehensible to humans. We introduce and evaluate an explainable model for goal recognition (GR) agents, grounded in the theoretical framework and cognitive processes underlying human behavior explanation. Drawing on insights from two human-agent studies, we propose a conceptual framework for human-centered explanations of GR. Using this framework, we develop the eXplainable Goal Recognition (XGR) model, which generates explanations for both why and why not questions. We evaluate the model computationally across eight GR benchmarks and through three user studies. The first study assesses the efficiency of generating human-like explanations within the Sokoban game domain, the second examines perceived explainability in the same domain, and the third evaluates the model's effectiveness in aiding decision-making in illegal fishing detection. Results demonstrate that the XGR model significantly enhances user understanding, trust, and decision-making compared to baseline models, underscoring its potential to improve human-agent collaboration.
Towards the new XAI: A Hypothesis-Driven Approach to Decision Support Using Evidence
Feb 02, 2024



Prior research on AI-assisted human decision-making has explored several different explainable AI (XAI) approaches. A recent paper has proposed a paradigm shift calling for hypothesis-driven XAI through a conceptual framework called evaluative AI that gives people evidence that supports or refutes hypotheses without necessarily giving a decision-aid recommendation. In this paper we describe and evaluate an approach for hypothesis-driven XAI based on the Weight of Evidence (WoE) framework, which generates both positive and negative evidence for a given hypothesis. Through human behavioural experiments, we show that our hypothesis-driven approach increases decision accuracy, reduces reliance compared to a recommendation-driven approach and an AI-explanation-only baseline, but with a small increase in under-reliance compared to the recommendation-driven approach. Further, we show that participants used our hypothesis-driven approach in a materially different way to the two baselines.
Diverse, Top-k, and Top-Quality Planning Over Simulators
Aug 25, 2023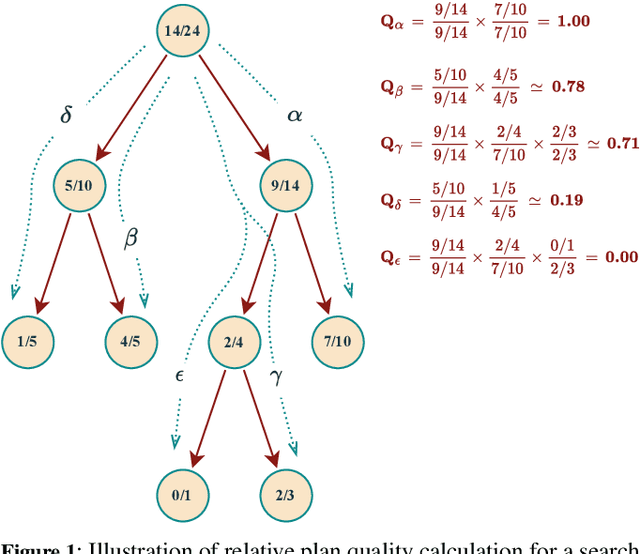
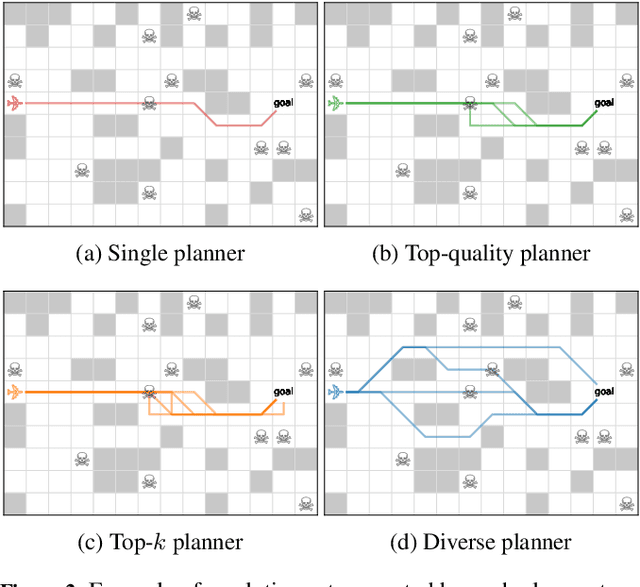

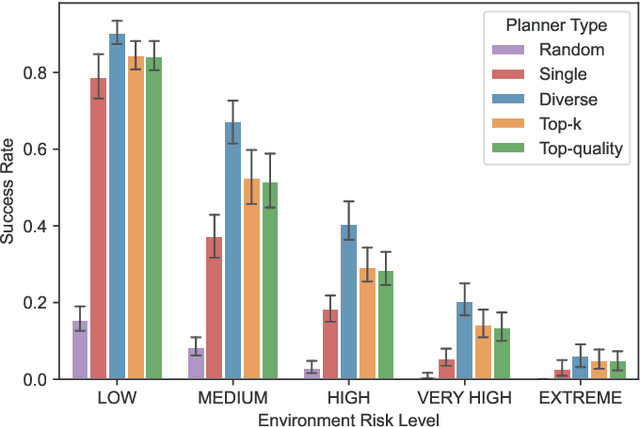
Diverse, top-k, and top-quality planning are concerned with the generation of sets of solutions to sequential decision problems. Previously this area has been the domain of classical planners that require a symbolic model of the problem instance. This paper proposes a novel alternative approach that uses Monte Carlo Tree Search (MCTS), enabling application to problems for which only a black-box simulation model is available. We present a procedure for extracting bounded sets of plans from pre-generated search trees in best-first order, and a metric for evaluating the relative quality of paths through a search tree. We demonstrate this approach on a path-planning problem with hidden information, and suggest adaptations to the MCTS algorithm to increase the diversity of generated plans. Our results show that our method can generate diverse and high-quality plan sets in domains where classical planners are not applicable.
Deceptive Reinforcement Learning in Model-Free Domains
Mar 20, 2023



This paper investigates deceptive reinforcement learning for privacy preservation in model-free and continuous action space domains. In reinforcement learning, the reward function defines the agent's objective. In adversarial scenarios, an agent may need to both maximise rewards and keep its reward function private from observers. Recent research presented the ambiguity model (AM), which selects actions that are ambiguous over a set of possible reward functions, via pre-trained $Q$-functions. Despite promising results in model-based domains, our investigation shows that AM is ineffective in model-free domains due to misdirected state space exploration. It is also inefficient to train and inapplicable in continuous action space domains. We propose the deceptive exploration ambiguity model (DEAM), which learns using the deceptive policy during training, leading to targeted exploration of the state space. DEAM is also applicable in continuous action spaces. We evaluate DEAM in discrete and continuous action space path planning environments. DEAM achieves similar performance to an optimal model-based version of AM and outperforms a model-free version of AM in terms of path cost, deceptiveness and training efficiency. These results extend to the continuous domain.
Explainable AI is Dead, Long Live Explainable AI! Hypothesis-driven decision support
Mar 11, 2023



In this paper, we argue for a paradigm shift from the current model of explainable artificial intelligence (XAI), which may be counter-productive to better human decision making. In early decision support systems, we assumed that we could give people recommendations and that they would consider them, and then follow them when required. However, research found that people often ignore recommendations because they do not trust them; or perhaps even worse, people follow them blindly, even when the recommendations are wrong. Explainable artificial intelligence mitigates this by helping people to understand how and why models give certain recommendations. However, recent research shows that people do not always engage with explainability tools enough to help improve decision making. The assumption that people will engage with recommendations and explanations has proven to be unfounded. We argue this is because we have failed to account for two things. First, recommendations (and their explanations) take control from human decision makers, limiting their agency. Second, giving recommendations and explanations does not align with the cognitive processes employed by people making decisions. This position paper proposes a new conceptual framework called Evaluative AI for explainable decision support. This is a machine-in-the-loop paradigm in which decision support tools provide evidence for and against decisions made by people, rather than provide recommendations to accept or reject. We argue that this mitigates issues of over- and under-reliance on decision support tools, and better leverages human expertise in decision making.
Explaining Model Confidence Using Counterfactuals
Mar 10, 2023Displaying confidence scores in human-AI interaction has been shown to help build trust between humans and AI systems. However, most existing research uses only the confidence score as a form of communication. As confidence scores are just another model output, users may want to understand why the algorithm is confident to determine whether to accept the confidence score. In this paper, we show that counterfactual explanations of confidence scores help study participants to better understand and better trust a machine learning model's prediction. We present two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space. Both increase understanding and trust for study participants over a baseline of no explanation, but qualitative results show that they are used quite differently, leading to recommendations of when to use each one and directions of designing better explanations.