 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the new XAI: A Hypothesis-Driven Approach to Decision Support Using Evidence
Feb 02, 2024



Prior research on AI-assisted human decision-making has explored several different explainable AI (XAI) approaches. A recent paper has proposed a paradigm shift calling for hypothesis-driven XAI through a conceptual framework called evaluative AI that gives people evidence that supports or refutes hypotheses without necessarily giving a decision-aid recommendation. In this paper we describe and evaluate an approach for hypothesis-driven XAI based on the Weight of Evidence (WoE) framework, which generates both positive and negative evidence for a given hypothesis. Through human behavioural experiments, we show that our hypothesis-driven approach increases decision accuracy, reduces reliance compared to a recommendation-driven approach and an AI-explanation-only baseline, but with a small increase in under-reliance compared to the recommendation-driven approach. Further, we show that participants used our hypothesis-driven approach in a materially different way to the two baselines.
Explaining Model Confidence Using Counterfactuals
Mar 10, 2023Displaying confidence scores in human-AI interaction has been shown to help build trust between humans and AI systems. However, most existing research uses only the confidence score as a form of communication. As confidence scores are just another model output, users may want to understand why the algorithm is confident to determine whether to accept the confidence score. In this paper, we show that counterfactual explanations of confidence scores help study participants to better understand and better trust a machine learning model's prediction. We present two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space. Both increase understanding and trust for study participants over a baseline of no explanation, but qualitative results show that they are used quite differently, leading to recommendations of when to use each one and directions of designing better explanations.
Improving Model Understanding and Trust with Counterfactual Explanations of Model Confidence
Jun 06, 2022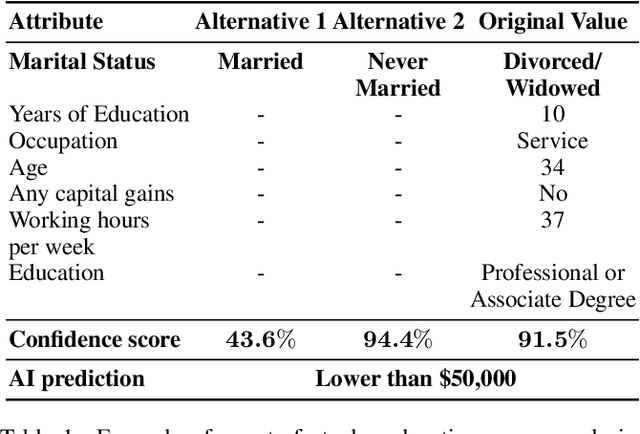


In this paper, we show that counterfactual explanations of confidence scores help users better understand and better trust an AI model's prediction in human-subject studies. Showing confidence scores in human-agent interaction systems can help build trust between humans and AI systems. However, most existing research only used the confidence score as a form of communication, and we still lack ways to explain why the algorithm is confident. This paper also presents two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space.
Collaborative Human-Agent Planning for Resilience
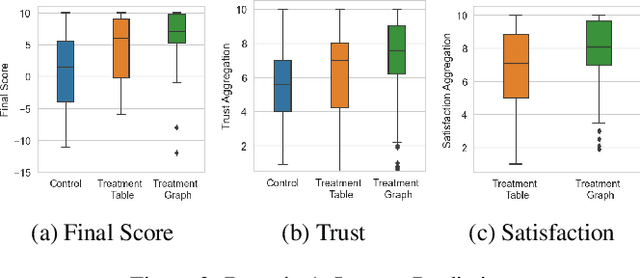
Apr 29, 2021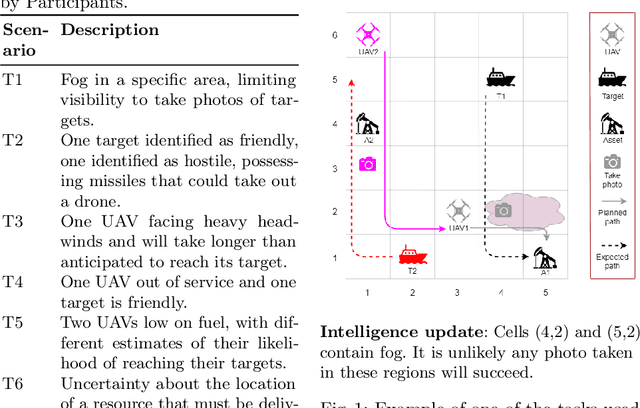

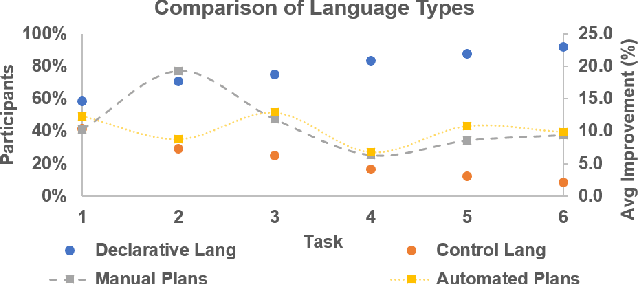
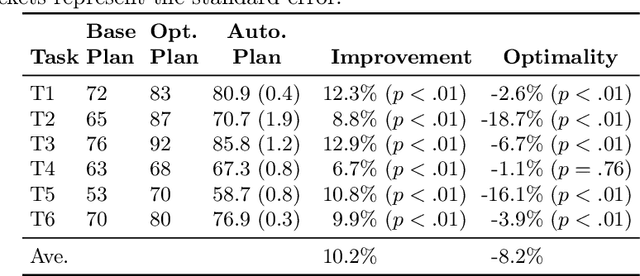
Intelligent agents powered by AI planning assist people in complex scenarios, such as managing teams of semi-autonomous vehicles. However, AI planning models may be incomplete, leading to plans that do not adequately meet the stated objectives, especially in unpredicted situations. Humans, who are apt at identifying and adapting to unusual situations, may be able to assist planning agents in these situations by encoding their knowledge into a planner at run-time. We investigate whether people can collaborate with agents by providing their knowledge to an agent using linear temporal logic (LTL) at run-time without changing the agent's domain model. We presented 24 participants with baseline plans for situations in which a planner had limitations, and asked the participants for workarounds for these limitations. We encoded these workarounds as LTL constraints. Results show that participants' constraints improved the expected return of the plans by 10% ($p < 0.05$) relative to baseline plans, demonstrating that human insight can be used in collaborative planning for resilience. However, participants used more declarative than control constraints over time, but declarative constraints produced plans less similar to the expectation of the participants, which could lead to potential trust issues.
LEx: A Framework for Operationalising Layers of Machine Learning Explanations
Apr 15, 2021Several social factors impact how people respond to AI explanations used to justify AI decisions affecting them personally. In this position paper, we define a framework called the \textit{layers of explanation} (LEx), a lens through which we can assess the appropriateness of different types of explanations. The framework uses the notions of \textit{sensitivity} (emotional responsiveness) of features and the level of \textit{stakes} (decision's consequence) in a domain to determine whether different types of explanations are \textit{appropriate} in a given context. We demonstrate how to use the framework to assess the appropriateness of different types of explanations in different domains.
Directive Explanations for Actionable Explainability in Machine Learning Applications
Feb 03, 2021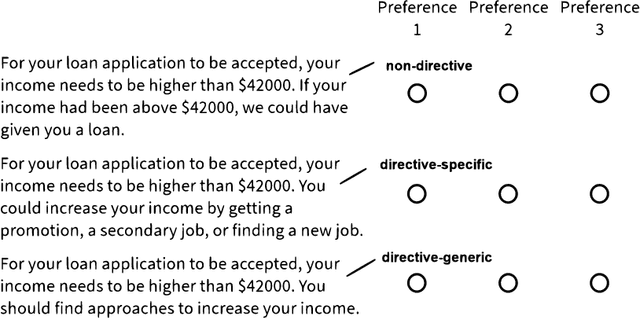
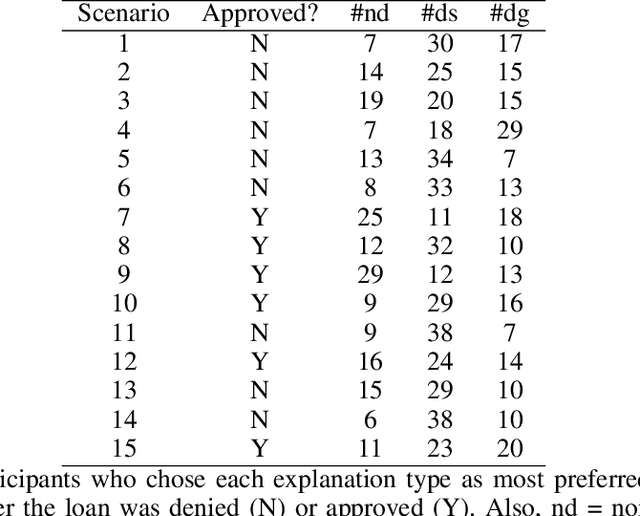
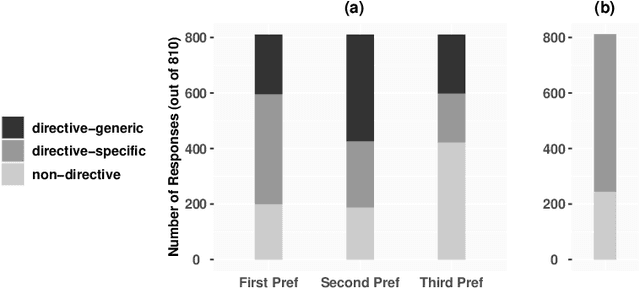

This paper investigates the prospects of using directive explanations to assist people in achieving recourse of machine learning decisions. Directive explanations list which specific actions an individual needs to take to achieve their desired outcome. If a machine learning model makes a decision that is detrimental to an individual (e.g. denying a loan application), then it needs to both explain why it made that decision and also explain how the individual could obtain their desired outcome (if possible). At present, this is often done using counterfactual explanations, but such explanations generally do not tell individuals how to act. We assert that counterfactual explanations can be improved by explicitly providing people with actions they could use to achieve their desired goal. This paper makes two contributions. First, we present the results of an online study investigating people's perception of directive explanations. Second, we propose a conceptual model to generate such explanations. Our online study showed a significant preference for directive explanations ($p<0.001$). However, the participants' preferred explanation type was affected by multiple factors, such as individual preferences, social factors, and the feasibility of the directives. Our findings highlight the need for a human-centred and context-specific approach for creating directive explanations.
Interaction Design for Explainable AI: Workshop Proceedings
Dec 13, 2018
As artificial intelligence (AI) systems become increasingly complex and ubiquitous, these systems will be responsible for making decisions that directly affect individuals and society as a whole. Such decisions will need to be justified due to ethical concerns as well as trust, but achieving this has become difficult due to the `black-box' nature many AI models have adopted. Explainable AI (XAI) can potentially address this problem by explaining its actions, decisions and behaviours of the system to users. However, much research in XAI is done in a vacuum using only the researchers' intuition of what constitutes a `good' explanation while ignoring the interaction and the human aspect. This workshop invites researchers in the HCI community and related fields to have a discourse about human-centred approaches to XAI rooted in interaction and to shed light and spark discussion on interaction design challenges in XAI.