 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the new XAI: A Hypothesis-Driven Approach to Decision Support Using Evidence
Feb 02, 2024



Prior research on AI-assisted human decision-making has explored several different explainable AI (XAI) approaches. A recent paper has proposed a paradigm shift calling for hypothesis-driven XAI through a conceptual framework called evaluative AI that gives people evidence that supports or refutes hypotheses without necessarily giving a decision-aid recommendation. In this paper we describe and evaluate an approach for hypothesis-driven XAI based on the Weight of Evidence (WoE) framework, which generates both positive and negative evidence for a given hypothesis. Through human behavioural experiments, we show that our hypothesis-driven approach increases decision accuracy, reduces reliance compared to a recommendation-driven approach and an AI-explanation-only baseline, but with a small increase in under-reliance compared to the recommendation-driven approach. Further, we show that participants used our hypothesis-driven approach in a materially different way to the two baselines.
Explaining Model Confidence Using Counterfactuals
Mar 10, 2023Displaying confidence scores in human-AI interaction has been shown to help build trust between humans and AI systems. However, most existing research uses only the confidence score as a form of communication. As confidence scores are just another model output, users may want to understand why the algorithm is confident to determine whether to accept the confidence score. In this paper, we show that counterfactual explanations of confidence scores help study participants to better understand and better trust a machine learning model's prediction. We present two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space. Both increase understanding and trust for study participants over a baseline of no explanation, but qualitative results show that they are used quite differently, leading to recommendations of when to use each one and directions of designing better explanations.
Improving Model Understanding and Trust with Counterfactual Explanations of Model Confidence
Jun 06, 2022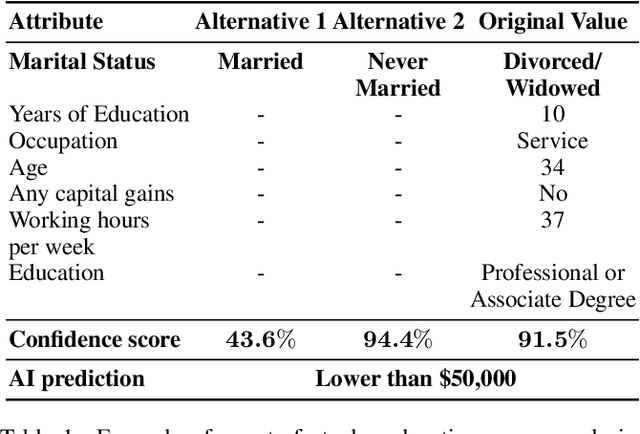


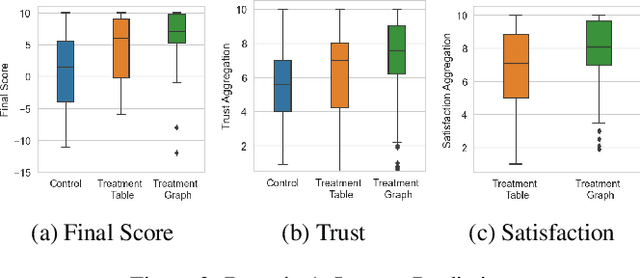
In this paper, we show that counterfactual explanations of confidence scores help users better understand and better trust an AI model's prediction in human-subject studies. Showing confidence scores in human-agent interaction systems can help build trust between humans and AI systems. However, most existing research only used the confidence score as a form of communication, and we still lack ways to explain why the algorithm is confident. This paper also presents two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space.
Efficient Multi-agent Epistemic Planning: Teaching Planners About Nested Belief
Oct 06, 2021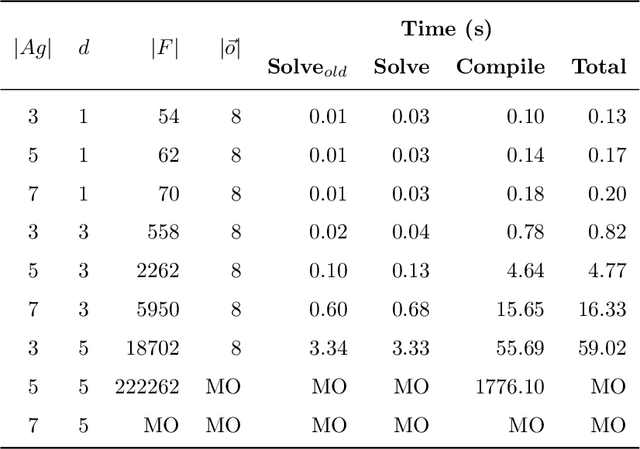
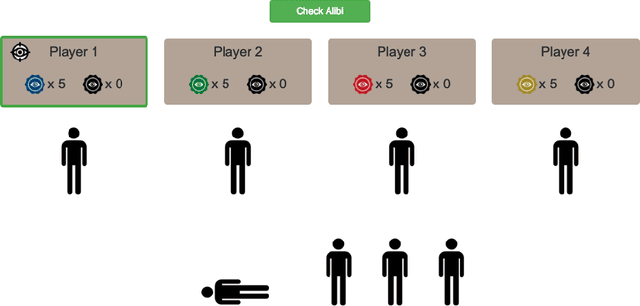
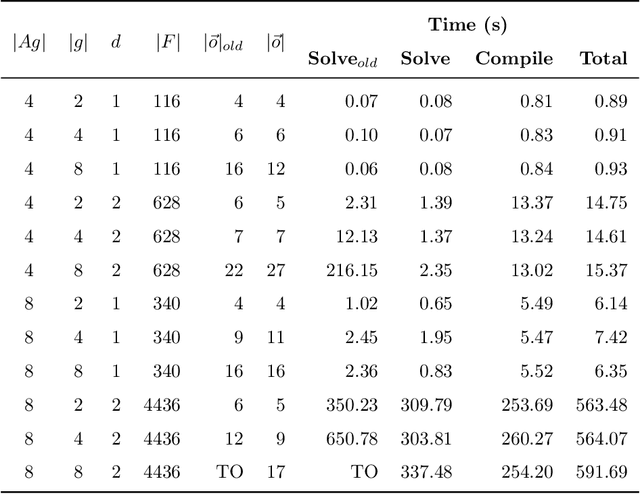
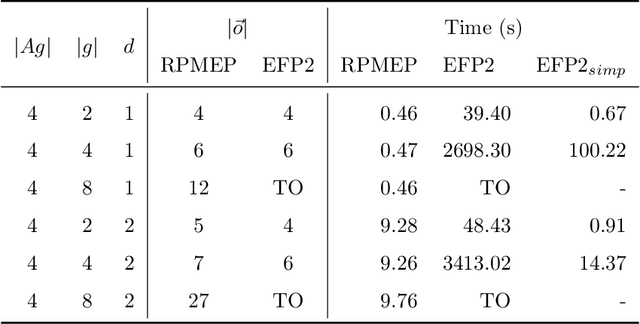
Many AI applications involve the interaction of multiple autonomous agents, requiring those agents to reason about their own beliefs, as well as those of other agents. However, planning involving nested beliefs is known to be computationally challenging. In this work, we address the task of synthesizing plans that necessitate reasoning about the beliefs of other agents. We plan from the perspective of a single agent with the potential for goals and actions that involve nested beliefs, non-homogeneous agents, co-present observations, and the ability for one agent to reason as if it were another. We formally characterize our notion of planning with nested belief, and subsequently demonstrate how to automatically convert such problems into problems that appeal to classical planning technology for solving efficiently. Our approach represents an important step towards applying the well-established field of automated planning to the challenging task of planning involving nested beliefs of multiple agents.
Directive Explanations for Actionable Explainability in Machine Learning Applications
Feb 03, 2021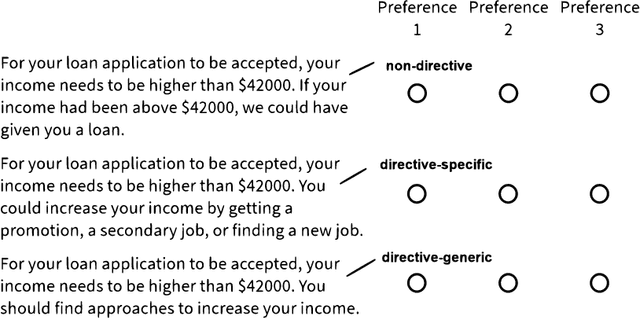
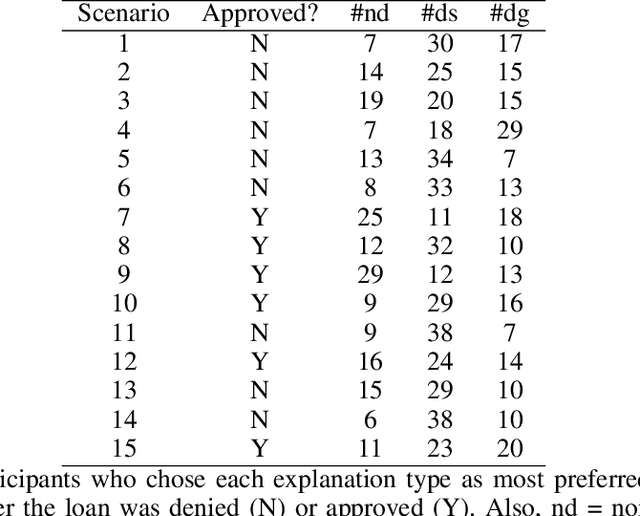
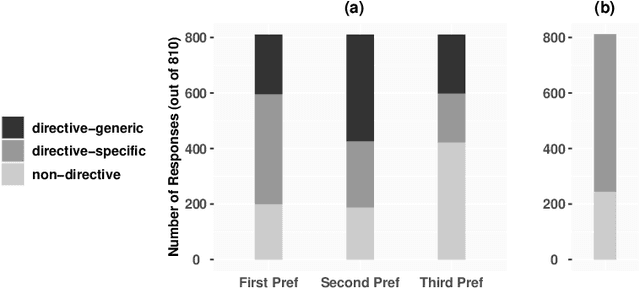

This paper investigates the prospects of using directive explanations to assist people in achieving recourse of machine learning decisions. Directive explanations list which specific actions an individual needs to take to achieve their desired outcome. If a machine learning model makes a decision that is detrimental to an individual (e.g. denying a loan application), then it needs to both explain why it made that decision and also explain how the individual could obtain their desired outcome (if possible). At present, this is often done using counterfactual explanations, but such explanations generally do not tell individuals how to act. We assert that counterfactual explanations can be improved by explicitly providing people with actions they could use to achieve their desired goal. This paper makes two contributions. First, we present the results of an online study investigating people's perception of directive explanations. Second, we propose a conceptual model to generate such explanations. Our online study showed a significant preference for directive explanations ($p<0.001$). However, the participants' preferred explanation type was affected by multiple factors, such as individual preferences, social factors, and the feasibility of the directives. Our findings highlight the need for a human-centred and context-specific approach for creating directive explanations.
Distal Explanations for Explainable Reinforcement Learning Agents
Jan 28, 2020
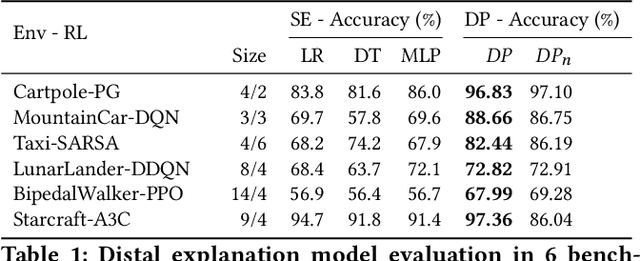
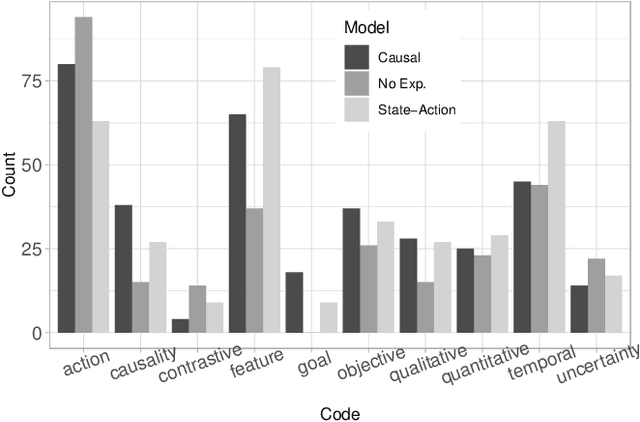
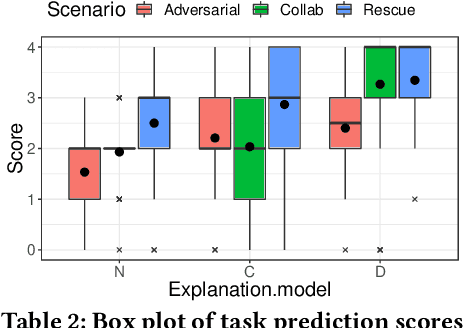
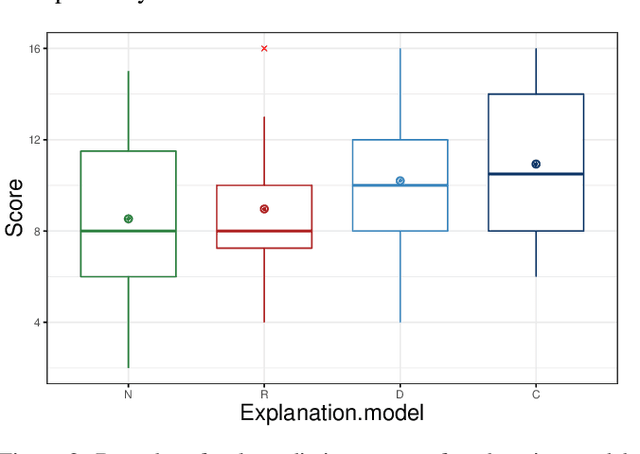
Causal explanations present an intuitive way to understand the course of events through causal chains, and are widely accepted in cognitive science as the prominent model humans use for explanation. Importantly, causal models can generate opportunity chains, which take the form of `A enables B and B causes C'. We ground the notion of opportunity chains in human-agent experimental data, where we present participants with explanations from different models and ask them to provide their own explanations for agent behaviour. Results indicate that humans do in-fact use the concept of opportunity chains frequently for describing artificial agent behaviour. Recently, action influence models have been proposed to provide causal explanations for model-free reinforcement learning (RL). While these models can generate counterfactuals---things that did not happen but could have under different conditions---they lack the ability to generate explanations of opportunity chains. We introduce a distal explanation model that can analyse counterfactuals and opportunity chains using decision trees and causal models. We employ a recurrent neural network to learn opportunity chains and make use of decision trees to improve the accuracy of task prediction and the generated counterfactuals. We computationally evaluate the model in 6 RL benchmarks using different RL algorithms, and show that our model performs better in task prediction. We report on a study with 90 participants who receive explanations of RL agents behaviour in solving three scenarios: 1) Adversarial; 2) Search and rescue; and 3) Human-Agent collaborative scenarios. We investigate the participants' understanding of the agent through task prediction and their subjective satisfaction of the explanations and show that our distal explanation model results in improved outcomes over the three scenarios compared with two baseline explanation models.
Explainable Reinforcement Learning Through a Causal Lens
May 27, 2019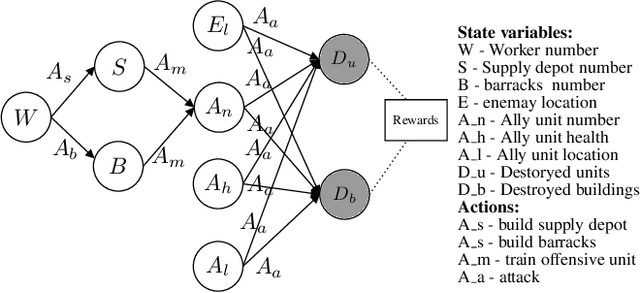
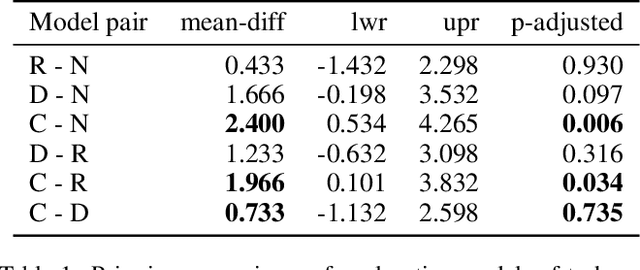
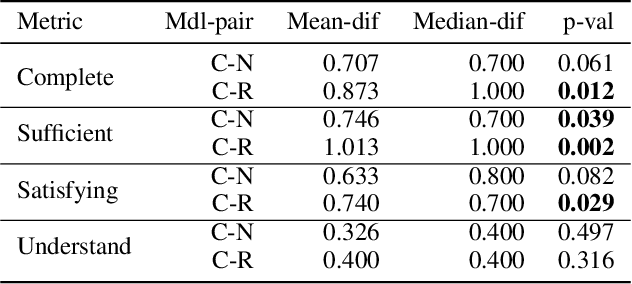
Prevalent theories in cognitive science propose that humans understand and represent the knowledge of the world through causal relationships. In making sense of the world, we build causal models in our mind to encode cause-effect relations of events and use these to explain why new events happen. In this paper, we use causal models to derive causal explanations of behaviour of reinforcement learning agents. We present an approach that learns a structural causal model during reinforcement learning and encodes causal relationships between variables of interest. This model is then used to generate explanations of behaviour based on counterfactual analysis of the causal model. We report on a study with 120 participants who observe agents playing a real-time strategy game (Starcraft II) and then receive explanations of the agents' behaviour. We investigated: 1) participants' understanding gained by explanations through task prediction; 2) explanation satisfaction and 3) trust. Our results show that causal model explanations perform better on these measures compared to two other baseline explanation models.
A Grounded Interaction Protocol for Explainable Artificial Intelligence
Mar 05, 2019
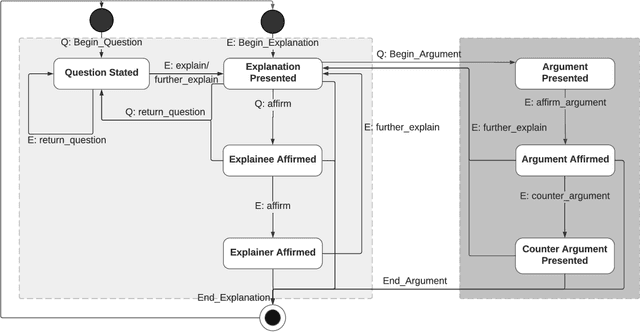
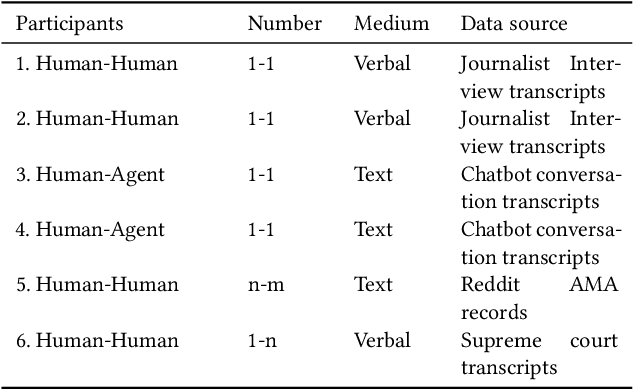
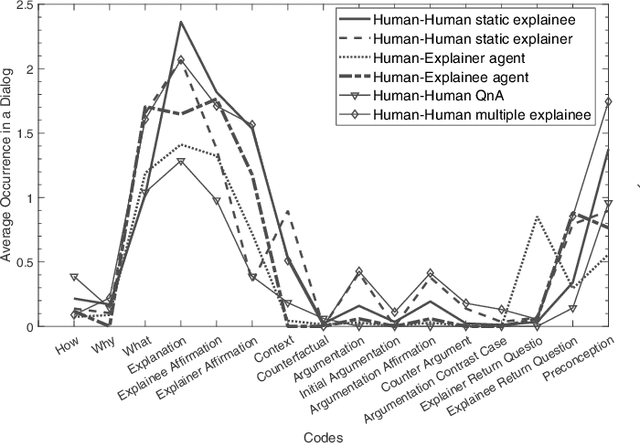
Explainable Artificial Intelligence (XAI) systems need to include an explanation model to communicate the internal decisions, behaviours and actions to the interacting humans. Successful explanation involves both cognitive and social processes. In this paper we focus on the challenge of meaningful interaction between an explainer and an explainee and investigate the structural aspects of an interactive explanation to propose an interaction protocol. We follow a bottom-up approach to derive the model by analysing transcripts of different explanation dialogue types with 398 explanation dialogues. We use grounded theory to code and identify key components of an explanation dialogue. We formalize the model using the agent dialogue framework (ADF) as a new dialogue type and then evaluate it in a human-agent interaction study with 101 dialogues from 14 participants. Our results show that the proposed model can closely follow the explanation dialogues of human-agent conversations.
Towards a Grounded Dialog Model for Explainable Artificial Intelligence
Jun 21, 2018
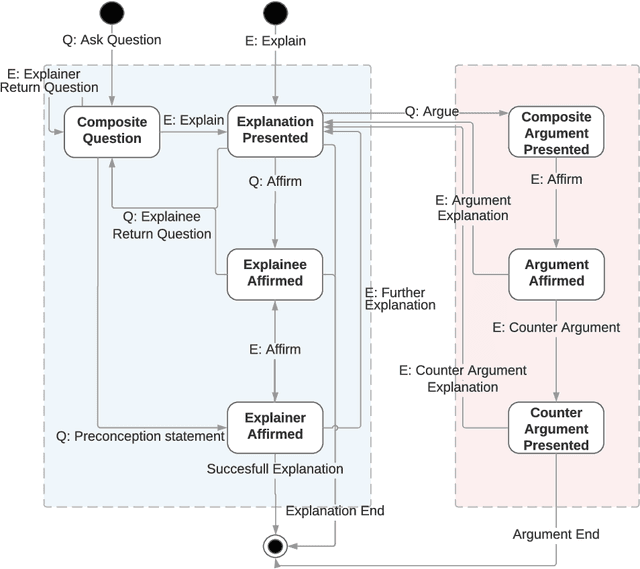
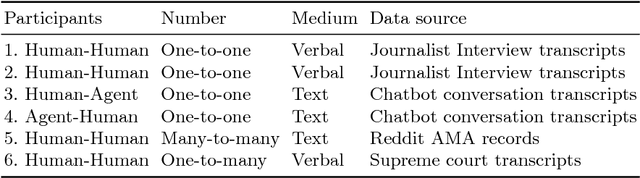
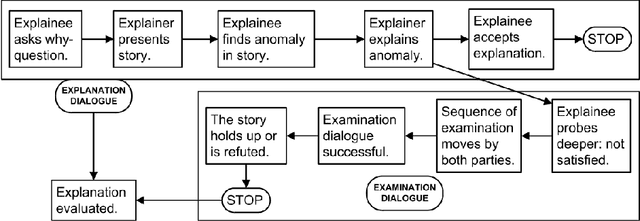
To generate trust with their users, Explainable Artificial Intelligence (XAI) systems need to include an explanation model that can communicate the internal decisions, behaviours and actions to the interacting humans. Successful explanation involves both cognitive and social processes. In this paper we focus on the challenge of meaningful interaction between an explainer and an explainee and investigate the structural aspects of an explanation in order to propose a human explanation dialog model. We follow a bottom-up approach to derive the model by analysing transcripts of 398 different explanation dialog types. We use grounded theory to code and identify key components of which an explanation dialog consists. We carry out further analysis to identify the relationships between components and sequences and cycles that occur in a dialog. We present a generalized state model obtained by the analysis and compare it with an existing conceptual dialog model of explanation.
Explainable AI: Beware of Inmates Running the Asylum Or: How I Learnt to Stop Worrying and Love the Social and Behavioural Sciences
Dec 05, 2017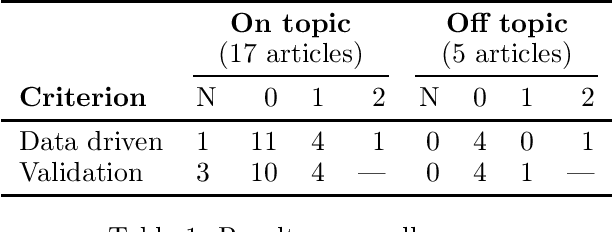
In his seminal book `The Inmates are Running the Asylum: Why High-Tech Products Drive Us Crazy And How To Restore The Sanity' [2004, Sams Indianapolis, IN, USA], Alan Cooper argues that a major reason why software is often poorly designed (from a user perspective) is that programmers are in charge of design decisions, rather than interaction designers. As a result, programmers design software for themselves, rather than for their target audience, a phenomenon he refers to as the `inmates running the asylum'. This paper argues that explainable AI risks a similar fate. While the re-emergence of explainable AI is positive, this paper argues most of us as AI researchers are building explanatory agents for ourselves, rather than for the intended users. But explainable AI is more likely to succeed if researchers and practitioners understand, adopt, implement, and improve models from the vast and valuable bodies of research in philosophy, psychology, and cognitive science, and if evaluation of these models is focused more on people than on technology. From a light scan of literature, we demonstrate that there is considerable scope to infuse more results from the social and behavioural sciences into explainable AI, and present some key results from these fields that are relevant to explainable AI.