Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Model Understanding and Trust with Counterfactual Explanations of Model Confidence
Paper and Code
Jun 06, 2022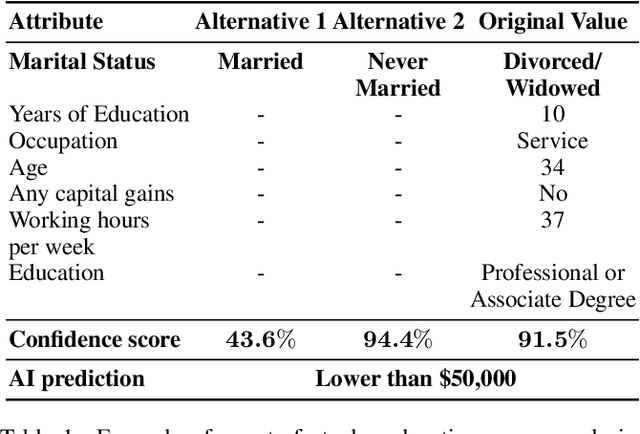


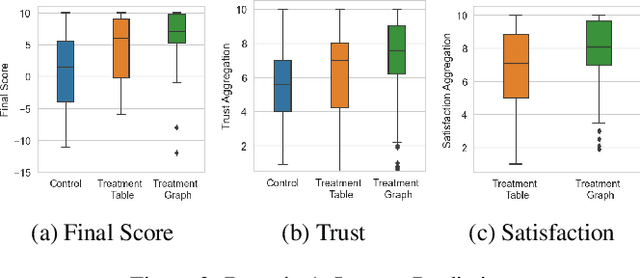
In this paper, we show that counterfactual explanations of confidence scores help users better understand and better trust an AI model's prediction in human-subject studies. Showing confidence scores in human-agent interaction systems can help build trust between humans and AI systems. However, most existing research only used the confidence score as a form of communication, and we still lack ways to explain why the algorithm is confident. This paper also presents two methods for understanding model confidence using counterfactual explanation: (1) based on counterfactual examples; and (2) based on visualisation of the counterfactual space.
* 8 pages, Accepted to IJCAI Workshop on Explainable Artificial
Intelligence 2022
View paper on