 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManaging AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft
Jun 05, 2023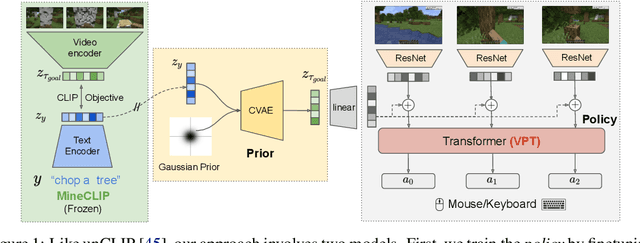



Constructing AI models that respond to text instructions is challenging, especially for sequential decision-making tasks. This work introduces an instruction-tuned Video Pretraining (VPT) model for Minecraft called STEVE-1, demonstrating that the unCLIP approach, utilized in DALL-E 2, is also effective for creating instruction-following sequential decision-making agents. STEVE-1 is trained in two steps: adapting the pretrained VPT model to follow commands in MineCLIP's latent space, then training a prior to predict latent codes from text. This allows us to finetune VPT through self-supervised behavioral cloning and hindsight relabeling, bypassing the need for costly human text annotations. By leveraging pretrained models like VPT and MineCLIP and employing best practices from text-conditioned image generation, STEVE-1 costs just $60 to train and can follow a wide range of short-horizon open-ended text and visual instructions in Minecraft. STEVE-1 sets a new bar for open-ended instruction following in Minecraft with low-level controls (mouse and keyboard) and raw pixel inputs, far outperforming previous baselines. We provide experimental evidence highlighting key factors for downstream performance, including pretraining, classifier-free guidance, and data scaling. All resources, including our model weights, training scripts, and evaluation tools are made available for further research.
Optimal Decision Trees For Interpretable Clustering with Constraints
Jan 30, 2023



Constrained clustering is a semi-supervised task that employs a limited amount of labelled data, formulated as constraints, to incorporate domain-specific knowledge and to significantly improve clustering accuracy. Previous work has considered exact optimization formulations that can guarantee optimal clustering while satisfying all constraints, however these approaches lack interpretability. Recently, decision-trees have been used to produce inherently interpretable clustering solutions, however existing approaches do not support clustering constraints and do not provide strong theoretical guarantees on solution quality. In this work, we present a novel SAT-based framework for interpretable clustering that supports clustering constraints and that also provides strong theoretical guarantees on solution quality. We also present new insight into the trade-off between interpretability and satisfaction of such user-provided constraints. Our framework is the first approach for interpretable and constrained clustering. Experiments with a range of real-world and synthetic datasets demonstrate that our approach can produce high-quality and interpretable constrained clustering solutions.
You Can't Count on Luck: Why Decision Transformers Fail in Stochastic Environments
May 31, 2022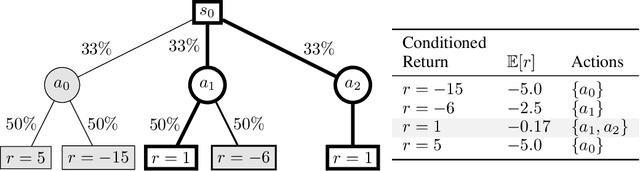
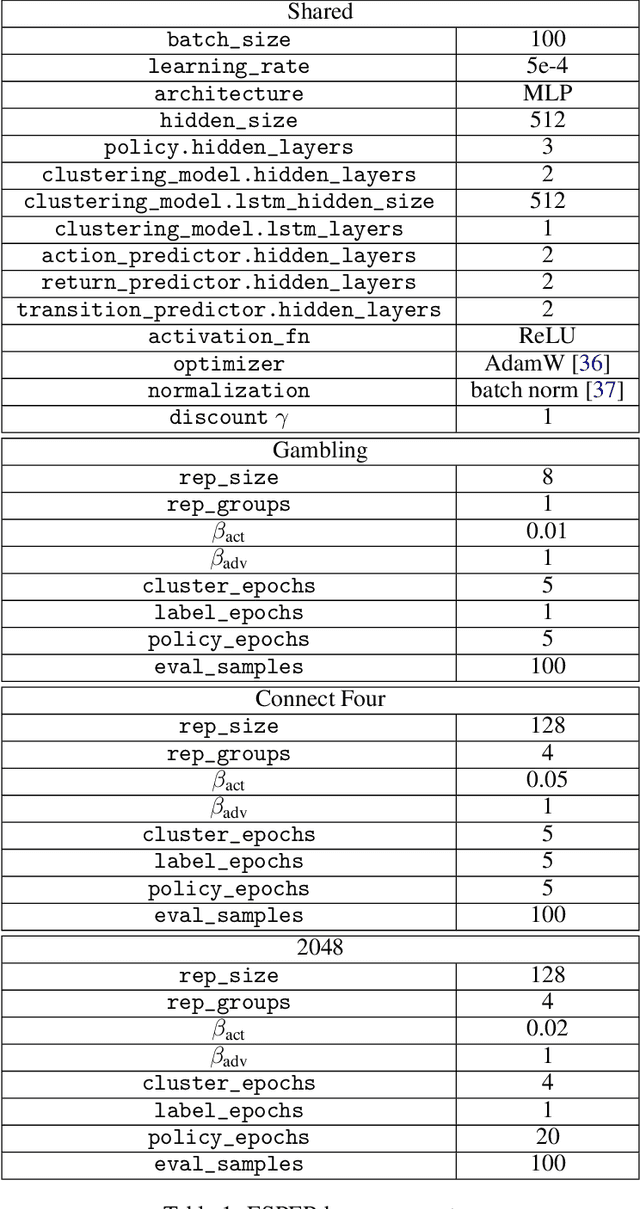
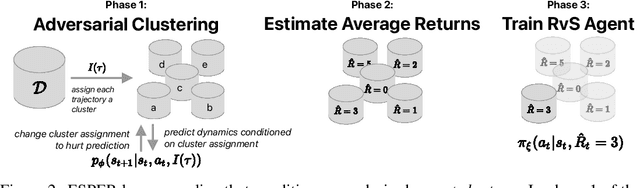

Recently, methods such as Decision Transformer that reduce reinforcement learning to a prediction task and solve it via supervised learning (RvS) have become popular due to their simplicity, robustness to hyperparameters, and strong overall performance on offline RL tasks. However, simply conditioning a probabilistic model on a desired return and taking the predicted action can fail dramatically in stochastic environments since trajectories that result in a return may have only achieved that return due to luck. In this work, we describe the limitations of RvS approaches in stochastic environments and propose a solution. Rather than simply conditioning on the return of a single trajectory as is standard practice, our proposed method, ESPER, learns to cluster trajectories and conditions on average cluster returns, which are independent from environment stochasticity. Doing so allows ESPER to achieve strong alignment between target return and expected performance in real environments. We demonstrate this in several challenging stochastic offline-RL tasks including the challenging puzzle game 2048, and Connect Four playing against a stochastic opponent. In all tested domains, ESPER achieves significantly better alignment between the target return and achieved return than simply conditioning on returns. ESPER also achieves higher maximum performance than even the value-based baselines.
Efficient Multi-agent Epistemic Planning: Teaching Planners About Nested Belief
Oct 06, 2021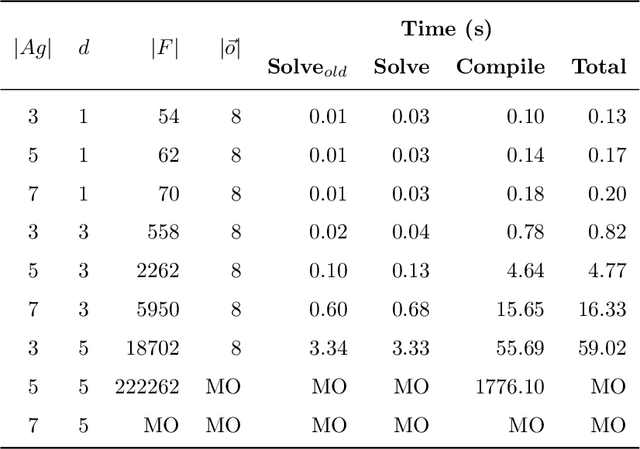
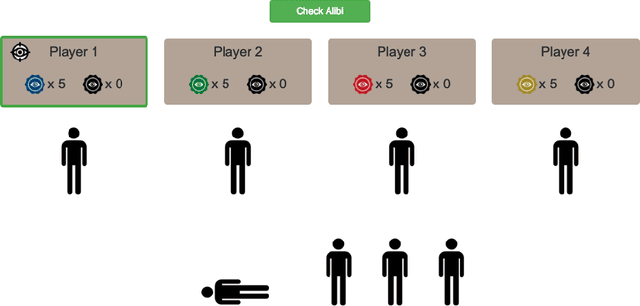
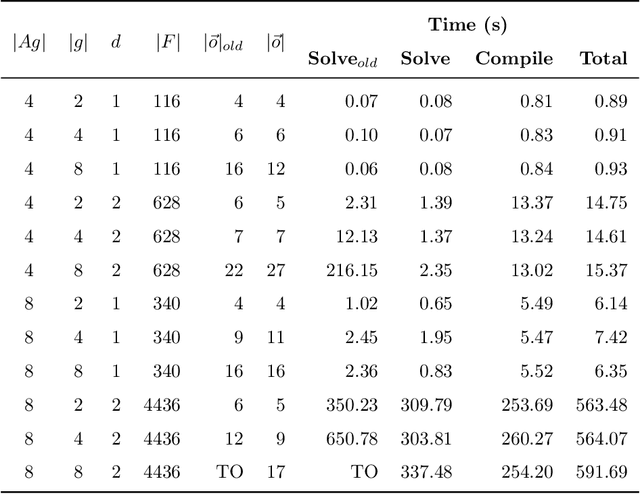
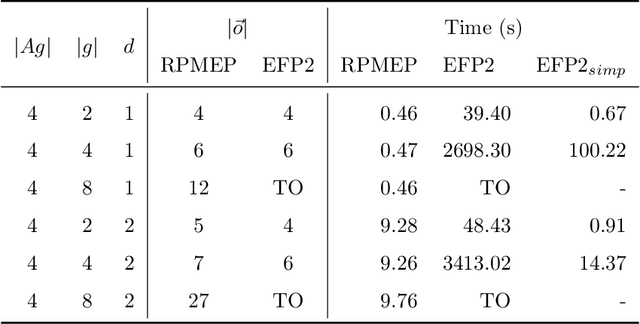
Many AI applications involve the interaction of multiple autonomous agents, requiring those agents to reason about their own beliefs, as well as those of other agents. However, planning involving nested beliefs is known to be computationally challenging. In this work, we address the task of synthesizing plans that necessitate reasoning about the beliefs of other agents. We plan from the perspective of a single agent with the potential for goals and actions that involve nested beliefs, non-homogeneous agents, co-present observations, and the ability for one agent to reason as if it were another. We formally characterize our notion of planning with nested belief, and subsequently demonstrate how to automatically convert such problems into problems that appeal to classical planning technology for solving efficiently. Our approach represents an important step towards applying the well-established field of automated planning to the challenging task of planning involving nested beliefs of multiple agents.
LTL2Action: Generalizing LTL Instructions for Multi-Task RL
Feb 25, 2021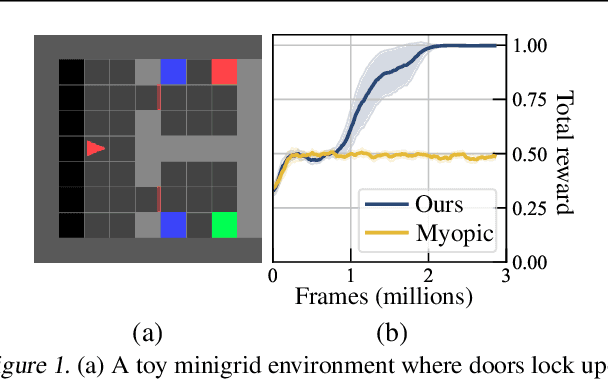
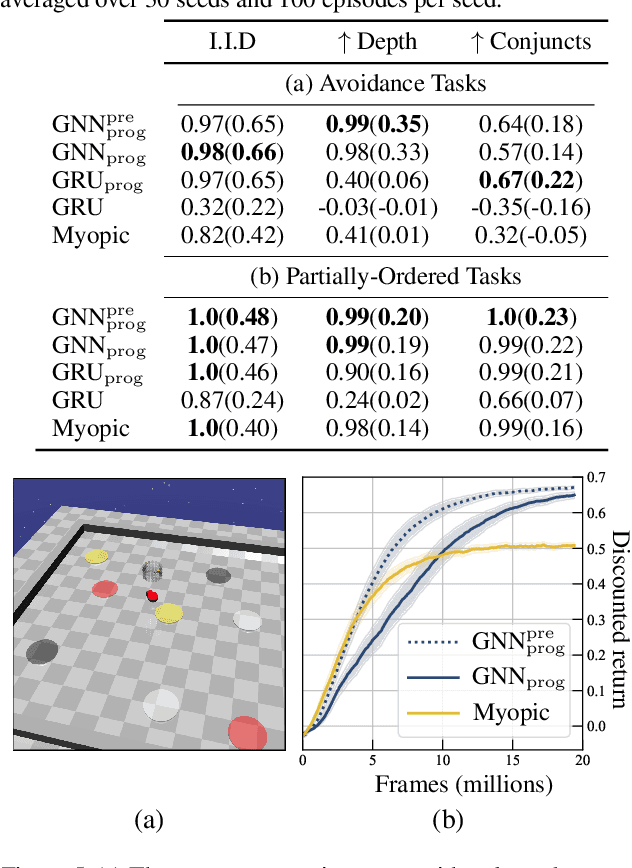
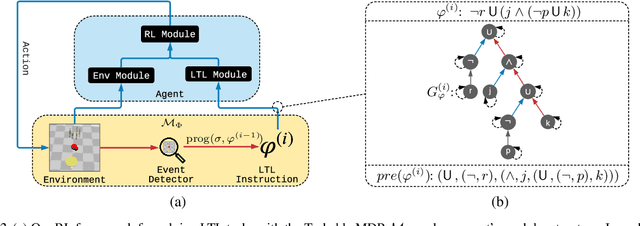

We address the problem of teaching a deep reinforcement learning (RL) agent to follow instructions in multi-task environments. The combinatorial task sets we target consist of up to $~10^{39}$ unique tasks. We employ a well-known formal language -- linear temporal logic (LTL) -- to specify instructions, using a domain-specific vocabulary. We propose a novel approach to learning that exploits the compositional syntax and the semantics of LTL, enabling our RL agent to learn task-conditioned policies that generalize to new instructions, not observed during training. The expressive power of LTL supports the specification of a diversity of complex temporally extended behaviours that include conditionals and alternative realizations. To reduce the overhead of learning LTL semantics, we introduce an environment-agnostic LTL pretraining scheme which improves sample-efficiency in downstream environments. Experiments on discrete and continuous domains demonstrate the strength of our approach in learning to solve (unseen) tasks, given LTL instructions.
Monitoring a Complez Physical System using a Hybrid Dynamic Bayes Net
Dec 12, 2012
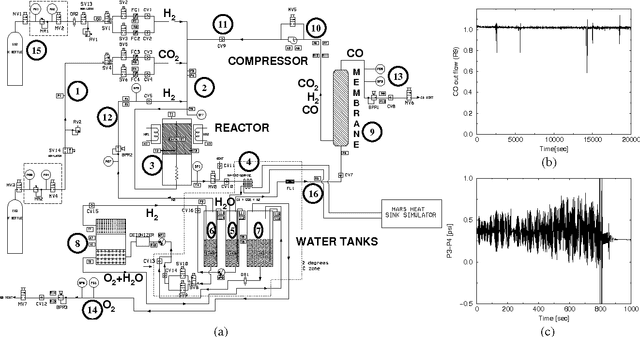

The Reverse Water Gas Shift system (RWGS) is a complex physical system designed to produce oxygen from the carbon dioxide atmosphere on Mars. If sent to Mars, it would operate without human supervision, thus requiring a reliable automated system for monitoring and control. The RWGS presents many challenges typical of real-world systems, including: noisy and biased sensors, nonlinear behavior, effects that are manifested over different time granularities, and unobservability of many important quantities. In this paper we model the RWGS using a hybrid (discrete/continuous) Dynamic Bayesian Network (DBN), where the state at each time slice contains 33 discrete and 184 continuous variables. We show how the system state can be tracked using probabilistic inference over the model. We discuss how to deal with the various challenges presented by the RWGS, providing a suite of techniques that are likely to be useful in a wide range of applications. In particular, we describe a general framework for dealing with nonlinear behavior using numerical integration techniques, extending the successful Unscented Filter. We also show how to use a fixed-point computation to deal with effects that develop at different time scales, specifically rapid changes occurring during slowly changing processes. We test our model using real data collected from the RWGS, demonstrating the feasibility of hybrid DBNs for monitoring complex real-world physical systems.
Generating Optimal Plans in Highly-Dynamic Domains
May 09, 2012
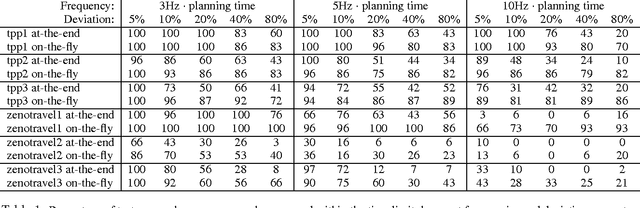

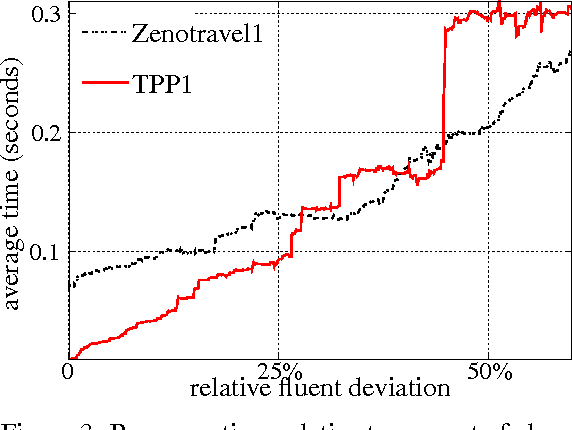
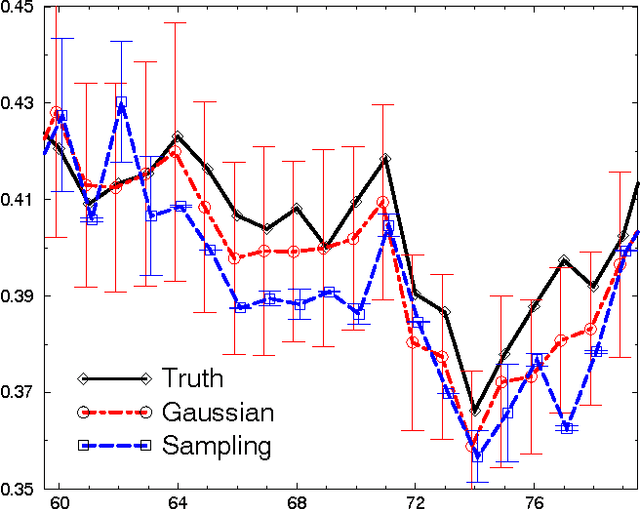
Generating optimal plans in highly dynamic environments is challenging. Plans are predicated on an assumed initial state, but this state can change unexpectedly during plan generation, potentially invalidating the planning effort. In this paper we make three contributions: (1) We propose a novel algorithm for generating optimal plans in settings where frequent, unexpected events interfere with planning. It is able to quickly distinguish relevant from irrelevant state changes, and to update the existing planning search tree if necessary. (2) We argue for a new criterion for evaluating plan adaptation techniques: the relative running time compared to the "size" of changes. This is significant since during recovery more changes may occur that need to be recovered from subsequently, and in order for this process of repeated recovery to terminate, recovery time has to converge. (3) We show empirically that our approach can converge and find optimal plans in environments that would ordinarily defy planning due to their high dynamics.
Domain-Dependent Knowledge in Answer Set Planning
Aug 29, 2005
In this paper we consider three different kinds of domain-dependent control knowledge (temporal, procedural and HTN-based) that are useful in planning. Our approach is declarative and relies on the language of logic programming with answer set semantics (AnsProlog*). AnsProlog* is designed to plan without control knowledge. We show how temporal, procedural and HTN-based control knowledge can be incorporated into AnsProlog* by the modular addition of a small number of domain-dependent rules, without the need to modify the planner. We formally prove the correctness of our planner, both in the absence and presence of the control knowledge. Finally, we perform some initial experimentation that demonstrates the potential reduction in planning time that can be achieved when procedural domain knowledge is used to solve planning problems with large plan length.