 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Layer Relevance in Large Language Models Beyond Cosine Similarity
May 13, 2026Large language models (LLMs) have revolutionized natural language processing. Understanding their internal mechanisms is crucial for developing more interpretable and optimized architectures. Mechanistic interpretability has led to the development of various methods for assessing layer relevance, with cosine similarity being a widely used tool in the field. On this work, we demonstrate that cosine similarity is a poor proxy for the actual performance degradation caused by layer removal. Our theoretical analysis shows that a layer can exhibit an arbitrarily low cosine similarity score while still being crucial to the model's performance. On the other hand, empirical evidence from a range of LLMs confirms that the correlation between cosine similarity and actual performance degradation is often weak or moderate, leading to misleading interpretations of a transformer's internal mechanisms. We propose a more robust metric for assessing layer relevance: the actual drop in model accuracy resulting from the removal of a layer. Even though it is a computationally costly metric, this approach offers a more accurate picture of layer importance, allowing for more informed pruning strategies and lightweight models. Our findings have significant implications for the development of interpretable LLMs and highlight the need to move beyond cosine similarity in assessing layer relevance.
* Published at ICLR 2026
Seeing to Generalize: How Visual Data Corrects Binding Shortcuts
Feb 16, 2026Vision Language Models (VLMs) are designed to extend Large Language Models (LLMs) with visual capabilities, yet in this work we observe a surprising phenomenon: VLMs can outperform their underlying LLMs on purely text-only tasks, particularly in long-context information retrieval. To investigate this effect, we build a controlled synthetic retrieval task and find that a transformer trained only on text achieves perfect in-distribution accuracy but fails to generalize out of distribution, while subsequent training on an image-tokenized version of the same task nearly doubles text-only OOD performance. Mechanistic interpretability reveals that visual training changes the model's internal binding strategy: text-only training encourages positional shortcuts, whereas image-based training disrupts them through spatial translation invariance, forcing the model to adopt a more robust symbolic binding mechanism that persists even after text-only examples are reintroduced. We further characterize how binding strategies vary across training regimes, visual encoders, and initializations, and show that analogous shifts occur during pretrained LLM-to-VLM transitions. Our findings suggest that cross-modal training can enhance reasoning and generalization even for tasks grounded in a single modality.
Active Learning of Symbolic Automata Over Rational Numbers
Nov 15, 2025

Automata learning has many applications in artificial intelligence and software engineering. Central to these applications is the $L^*$ algorithm, introduced by Angluin. The $L^*$ algorithm learns deterministic finite-state automata (DFAs) in polynomial time when provided with a minimally adequate teacher. Unfortunately, the $L^*$ algorithm can only learn DFAs over finite alphabets, which limits its applicability. In this paper, we extend $L^*$ to learn symbolic automata whose transitions use predicates over rational numbers, i.e., over infinite and dense alphabets. Our result makes the $L^*$ algorithm applicable to new settings like (real) RGX, and time series. Furthermore, our proposed algorithm is optimal in the sense that it asks a number of queries to the teacher that is at most linear with respect to the number of transitions, and to the representation size of the predicates.
Data Distributional Properties As Inductive Bias for Systematic Generalization
Feb 27, 2025



Deep neural networks (DNNs) struggle at systematic generalization (SG). Several studies have evaluated the possibility to promote SG through the proposal of novel architectures, loss functions or training methodologies. Few studies, however, have focused on the role of training data properties in promoting SG. In this work, we investigate the impact of certain data distributional properties, as inductive biases for the SG ability of a multi-modal language model. To this end, we study three different properties. First, data diversity, instantiated as an increase in the possible values a latent property in the training distribution may take. Second, burstiness, where we probabilistically restrict the number of possible values of latent factors on particular inputs during training. Third, latent intervention, where a particular latent factor is altered randomly during training. We find that all three factors significantly enhance SG, with diversity contributing an 89\% absolute increase in accuracy in the most affected property. Through a series of experiments, we test various hypotheses to understand why these properties promote SG. Finally, we find that Normalized Mutual Information (NMI) between latent attributes in the training distribution is strongly predictive of out-of-distribution generalization. We find that a mechanism by which lower NMI induces SG is in the geometry of representations. In particular, we find that NMI induces more parallelism in neural representations (i.e., input features coded in parallel neural vectors) of the model, a property related to the capacity of reasoning by analogy.
Being Considerate as a Pathway Towards Pluralistic Alignment for Agentic AI
Nov 15, 2024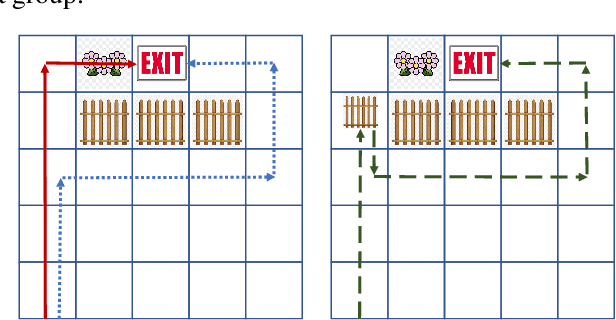
Pluralistic alignment is concerned with ensuring that an AI system's objectives and behaviors are in harmony with the diversity of human values and perspectives. In this paper we study the notion of pluralistic alignment in the context of agentic AI, and in particular in the context of an agent that is trying to learn a policy in a manner that is mindful of the values and perspective of others in the environment. To this end, we show how being considerate of the future wellbeing and agency of other (human) agents can promote a form of pluralistic alignment.
Reward Machines for Deep RL in Noisy and Uncertain Environments
May 31, 2024

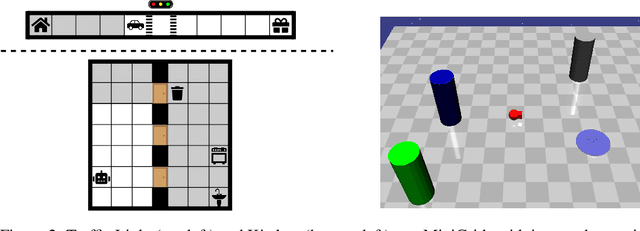

Reward Machines provide an automata-inspired structure for specifying instructions, safety constraints, and other temporally extended reward-worthy behaviour. By exposing complex reward function structure, they enable counterfactual learning updates that have resulted in impressive sample efficiency gains. While Reward Machines have been employed in both tabular and deep RL settings, they have typically relied on a ground-truth interpretation of the domain-specific vocabulary that form the building blocks of the reward function. Such ground-truth interpretations can be elusive in many real-world settings, due in part to partial observability or noisy sensing. In this paper, we explore the use of Reward Machines for Deep RL in noisy and uncertain environments. We characterize this problem as a POMDP and propose a suite of RL algorithms that leverage task structure under uncertain interpretation of domain-specific vocabulary. Theoretical analysis exposes pitfalls in naive approaches to this problem, while experimental results show that our algorithms successfully leverage task structure to improve performance under noisy interpretations of the vocabulary. Our results provide a general framework for exploiting Reward Machines in partially observable environments.
Learning Symbolic Representations for Reinforcement Learning of Non-Markovian Behavior
Jan 08, 2023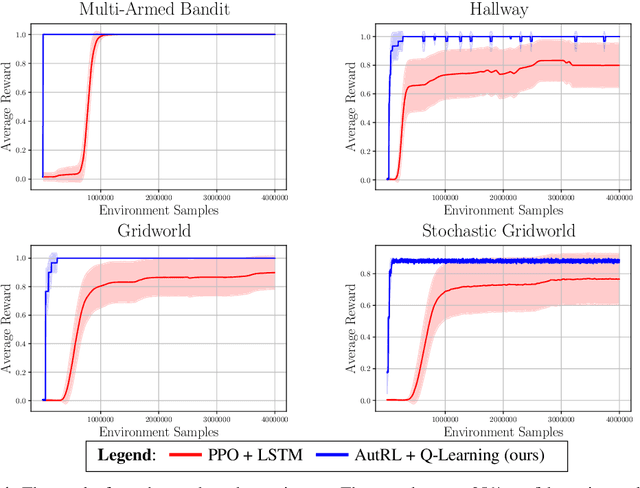
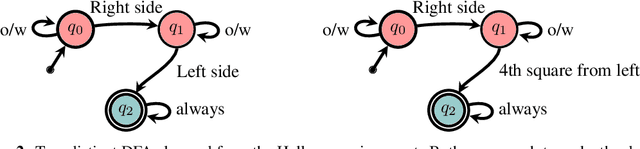
Many real-world reinforcement learning (RL) problems necessitate learning complex, temporally extended behavior that may only receive reward signal when the behavior is completed. If the reward-worthy behavior is known, it can be specified in terms of a non-Markovian reward function - a function that depends on aspects of the state-action history, rather than just the current state and action. Such reward functions yield sparse rewards, necessitating an inordinate number of experiences to find a policy that captures the reward-worthy pattern of behavior. Recent work has leveraged Knowledge Representation (KR) to provide a symbolic abstraction of aspects of the state that summarize reward-relevant properties of the state-action history and support learning a Markovian decomposition of the problem in terms of an automaton over the KR. Providing such a decomposition has been shown to vastly improve learning rates, especially when coupled with algorithms that exploit automaton structure. Nevertheless, such techniques rely on a priori knowledge of the KR. In this work, we explore how to automatically discover useful state abstractions that support learning automata over the state-action history. The result is an end-to-end algorithm that can learn optimal policies with significantly fewer environment samples than state-of-the-art RL on simple non-Markovian domains.
Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines
Nov 23, 2022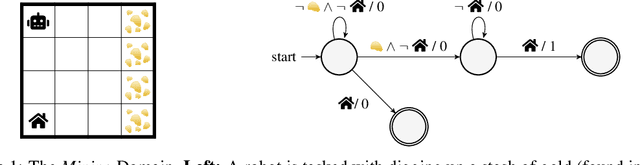
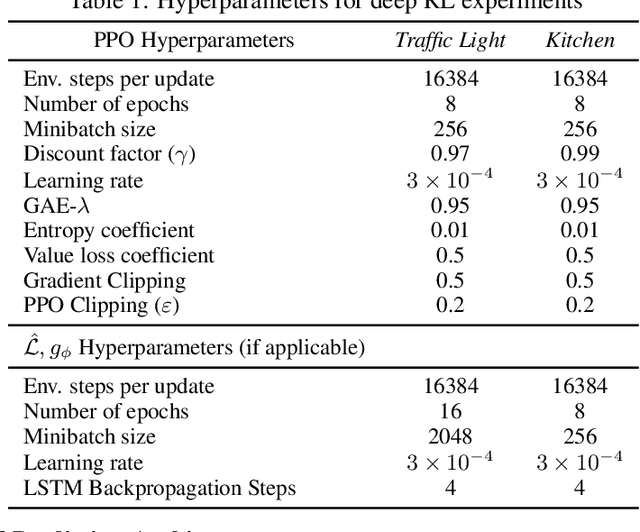
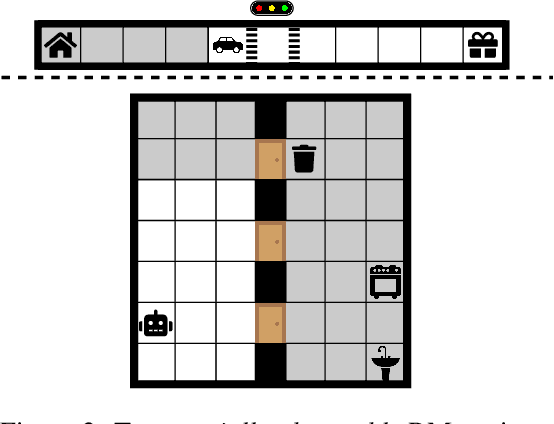
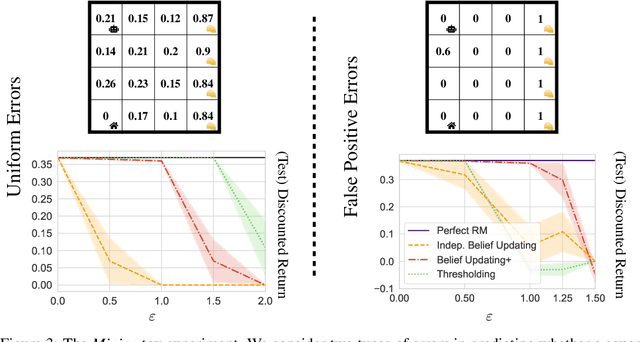
Natural and formal languages provide an effective mechanism for humans to specify instructions and reward functions. We investigate how to generate policies via RL when reward functions are specified in a symbolic language captured by Reward Machines, an increasingly popular automaton-inspired structure. We are interested in the case where the mapping of environment state to a symbolic (here, Reward Machine) vocabulary -- commonly known as the labelling function -- is uncertain from the perspective of the agent. We formulate the problem of policy learning in Reward Machines with noisy symbolic abstractions as a special class of POMDP optimization problem, and investigate several methods to address the problem, building on existing and new techniques, the latter focused on predicting Reward Machine state, rather than on grounding of individual symbols. We analyze these methods and evaluate them experimentally under varying degrees of uncertainty in the correct interpretation of the symbolic vocabulary. We verify the strength of our approach and the limitation of existing methods via an empirical investigation on both illustrative, toy domains and partially observable, deep RL domains.
Challenges to Solving Combinatorially Hard Long-Horizon Deep RL Tasks
Jun 03, 2022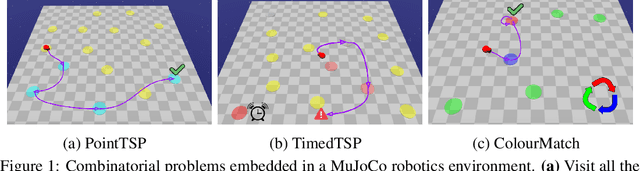
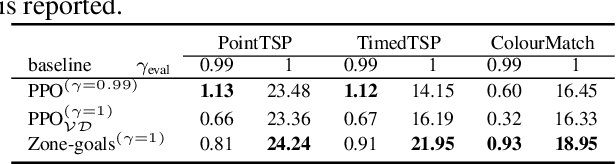
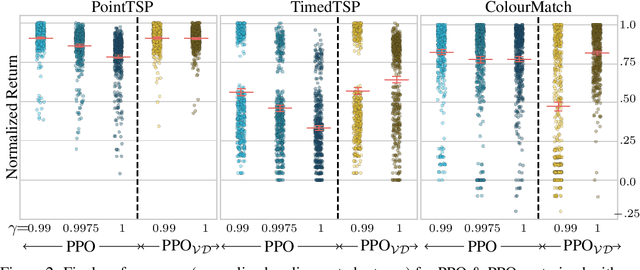
Deep reinforcement learning has shown promise in discrete domains requiring complex reasoning, including games such as Chess, Go, and Hanabi. However, this type of reasoning is less often observed in long-horizon, continuous domains with high-dimensional observations, where instead RL research has predominantly focused on problems with simple high-level structure (e.g. opening a drawer or moving a robot as fast as possible). Inspired by combinatorially hard optimization problems, we propose a set of robotics tasks which admit many distinct solutions at the high-level, but require reasoning about states and rewards thousands of steps into the future for the best performance. Critically, while RL has traditionally suffered on complex, long-horizon tasks due to sparse rewards, our tasks are carefully designed to be solvable without specialized exploration. Nevertheless, our investigation finds that standard RL methods often neglect long-term effects due to discounting, while general-purpose hierarchical RL approaches struggle unless additional abstract domain knowledge can be exploited.
Learning Reward Machines: A Study in Partially Observable Reinforcement Learning
Dec 17, 2021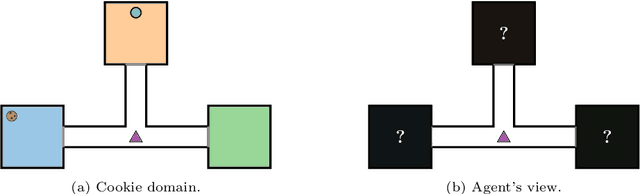
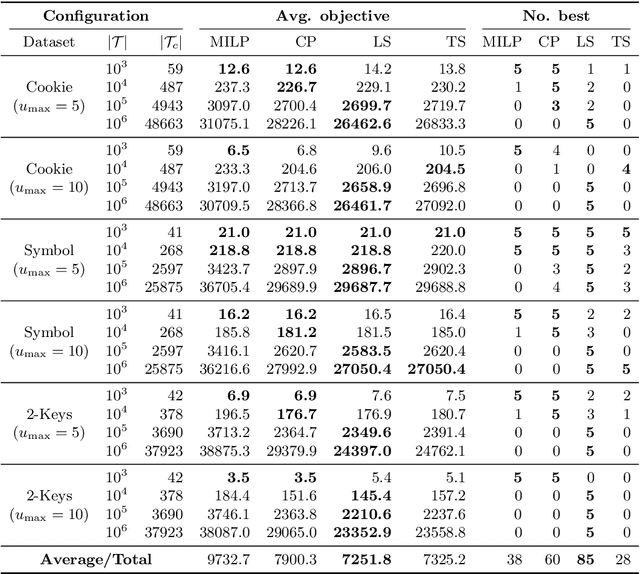
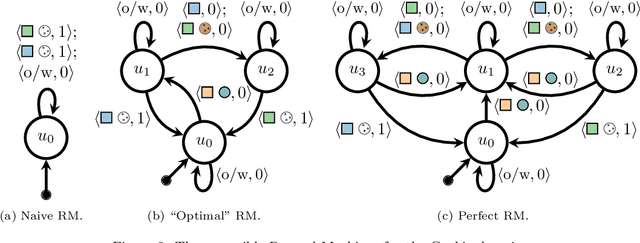
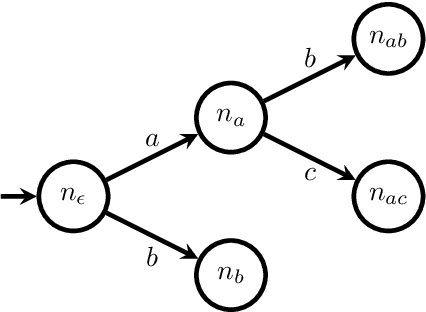
Reinforcement learning (RL) is a central problem in artificial intelligence. This problem consists of defining artificial agents that can learn optimal behaviour by interacting with an environment -- where the optimal behaviour is defined with respect to a reward signal that the agent seeks to maximize. Reward machines (RMs) provide a structured, automata-based representation of a reward function that enables an RL agent to decompose an RL problem into structured subproblems that can be efficiently learned via off-policy learning. Here we show that RMs can be learned from experience, instead of being specified by the user, and that the resulting problem decomposition can be used to effectively solve partially observable RL problems. We pose the task of learning RMs as a discrete optimization problem where the objective is to find an RM that decomposes the problem into a set of subproblems such that the combination of their optimal memoryless policies is an optimal policy for the original problem. We show the effectiveness of this approach on three partially observable domains, where it significantly outperforms A3C, PPO, and ACER, and discuss its advantages, limitations, and broader potential.