 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Considerate: Objectives, Side Effects, and Deciding How to Act
Paper and Code
Jun 04, 2021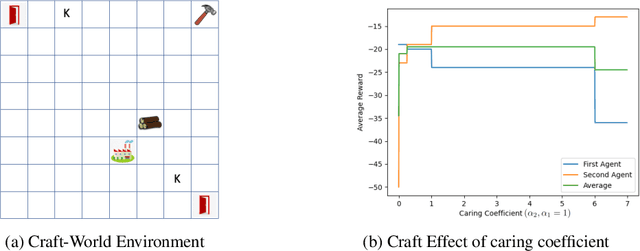

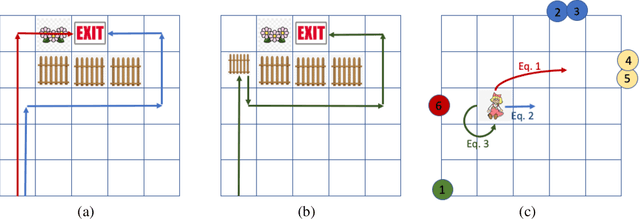

Recent work in AI safety has highlighted that in sequential decision making, objectives are often underspecified or incomplete. This gives discretion to the acting agent to realize the stated objective in ways that may result in undesirable outcomes. We contend that to learn to act safely, a reinforcement learning (RL) agent should include contemplation of the impact of its actions on the wellbeing and agency of others in the environment, including other acting agents and reactive processes. We endow RL agents with the ability to contemplate such impact by augmenting their reward based on expectation of future return by others in the environment, providing different criteria for characterizing impact. We further endow these agents with the ability to differentially factor this impact into their decision making, manifesting behavior that ranges from self-centred to self-less, as demonstrated by experiments in gridworld environments.