 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatisficing and Optimal Generalised Planning via Goal Regression (Extended Version)
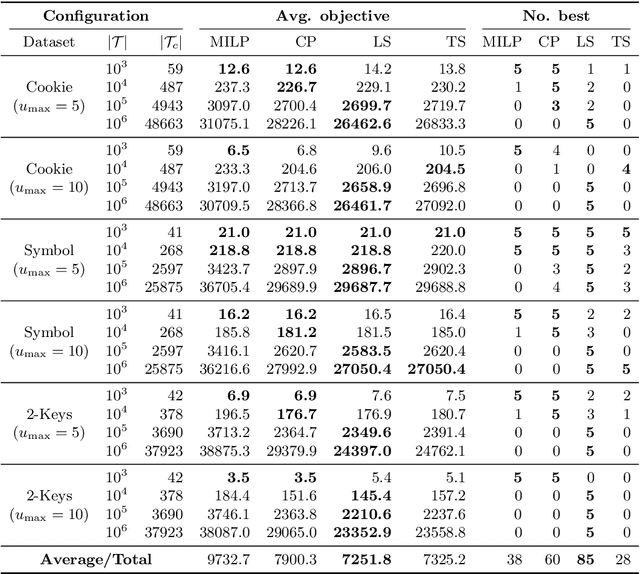
Nov 14, 2025Generalised planning (GP) refers to the task of synthesising programs that solve families of related planning problems. We introduce a novel, yet simple method for GP: given a set of training problems, for each problem, compute an optimal plan for each goal atom in some order, perform goal regression on the resulting plans, and lift the corresponding outputs to obtain a set of first-order $\textit{Condition} \rightarrow \textit{Actions}$ rules. The rules collectively constitute a generalised plan that can be executed as is or alternatively be used to prune the planning search space. We formalise and prove the conditions under which our method is guaranteed to learn valid generalised plans and state space pruning axioms for search. Experiments demonstrate significant improvements over state-of-the-art (generalised) planners with respect to the 3 metrics of synthesis cost, planning coverage, and solution quality on various classical and numeric planning domains.
Pushdown Reward Machines for Reinforcement Learning
Aug 09, 2025Reward machines (RMs) are automata structures that encode (non-Markovian) reward functions for reinforcement learning (RL). RMs can reward any behaviour representable in regular languages and, when paired with RL algorithms that exploit RM structure, have been shown to significantly improve sample efficiency in many domains. In this work, we present pushdown reward machines (pdRMs), an extension of reward machines based on deterministic pushdown automata. pdRMs can recognize and reward temporally extended behaviours representable in deterministic context-free languages, making them more expressive than reward machines. We introduce two variants of pdRM-based policies, one which has access to the entire stack of the pdRM, and one which can only access the top $k$ symbols (for a given constant $k$) of the stack. We propose a procedure to check when the two kinds of policies (for a given environment, pdRM, and constant $k$) achieve the same optimal expected reward. We then provide theoretical results establishing the expressive power of pdRMs, and space complexity results about the proposed learning problems. Finally, we provide experimental results showing how agents can be trained to perform tasks representable in deterministic context-free languages using pdRMs.
Pluralistic Alignment Over Time
Nov 16, 2024

If an AI system makes decisions over time, how should we evaluate how aligned it is with a group of stakeholders (who may have conflicting values and preferences)? In this position paper, we advocate for consideration of temporal aspects including stakeholders' changing levels of satisfaction and their possibly temporally extended preferences. We suggest how a recent approach to evaluating fairness over time could be applied to a new form of pluralistic alignment: temporal pluralism, where the AI system reflects different stakeholders' values at different times.
Being Considerate as a Pathway Towards Pluralistic Alignment for Agentic AI
Nov 15, 2024Pluralistic alignment is concerned with ensuring that an AI system's objectives and behaviors are in harmony with the diversity of human values and perspectives. In this paper we study the notion of pluralistic alignment in the context of agentic AI, and in particular in the context of an agent that is trying to learn a policy in a manner that is mindful of the values and perspective of others in the environment. To this end, we show how being considerate of the future wellbeing and agency of other (human) agents can promote a form of pluralistic alignment.
Reward Machines for Deep RL in Noisy and Uncertain Environments
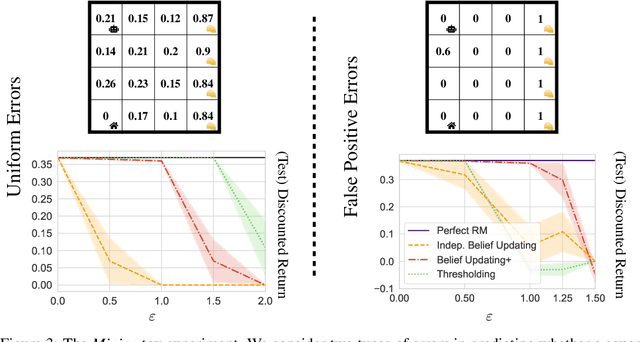
May 31, 2024Reward Machines provide an automata-inspired structure for specifying instructions, safety constraints, and other temporally extended reward-worthy behaviour. By exposing complex reward function structure, they enable counterfactual learning updates that have resulted in impressive sample efficiency gains. While Reward Machines have been employed in both tabular and deep RL settings, they have typically relied on a ground-truth interpretation of the domain-specific vocabulary that form the building blocks of the reward function. Such ground-truth interpretations can be elusive in many real-world settings, due in part to partial observability or noisy sensing. In this paper, we explore the use of Reward Machines for Deep RL in noisy and uncertain environments. We characterize this problem as a POMDP and propose a suite of RL algorithms that leverage task structure under uncertain interpretation of domain-specific vocabulary. Theoretical analysis exposes pitfalls in naive approaches to this problem, while experimental results show that our algorithms successfully leverage task structure to improve performance under noisy interpretations of the vocabulary. Our results provide a general framework for exploiting Reward Machines in partially observable environments.
Remembering to Be Fair: On Non-Markovian Fairness in Sequential DecisionMaking
Dec 08, 2023


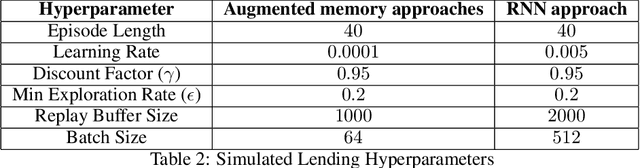
Fair decision making has largely been studied with respect to a single decision. In this paper we investigate the notion of fairness in the context of sequential decision making where multiple stakeholders can be affected by the outcomes of decisions, and where decision making may be informed by additional constraints and criteria beyond the requirement of fairness. In this setting, we observe that fairness often depends on the history of the sequential decision-making process and not just on the current state. To advance our understanding of this class of fairness problems, we define the notion of non-Markovian fairness in the context of sequential decision making. We identify properties of non-Markovian fairness, including notions of long-term, anytime, periodic, and bounded fairness. We further explore the interplay between non-Markovian fairness and memory, and how this can support construction of fair policies in sequential decision-making settings.
Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines
Nov 23, 2022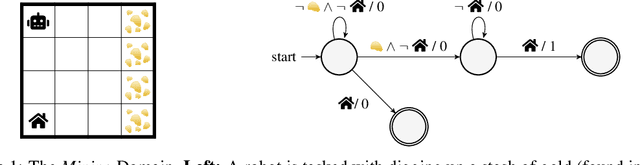
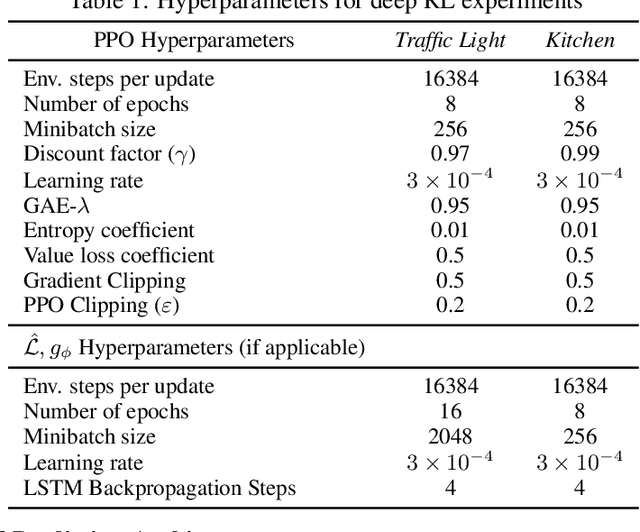
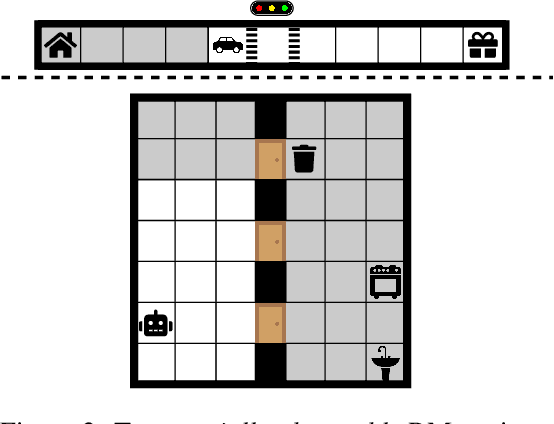
Natural and formal languages provide an effective mechanism for humans to specify instructions and reward functions. We investigate how to generate policies via RL when reward functions are specified in a symbolic language captured by Reward Machines, an increasingly popular automaton-inspired structure. We are interested in the case where the mapping of environment state to a symbolic (here, Reward Machine) vocabulary -- commonly known as the labelling function -- is uncertain from the perspective of the agent. We formulate the problem of policy learning in Reward Machines with noisy symbolic abstractions as a special class of POMDP optimization problem, and investigate several methods to address the problem, building on existing and new techniques, the latter focused on predicting Reward Machine state, rather than on grounding of individual symbols. We analyze these methods and evaluate them experimentally under varying degrees of uncertainty in the correct interpretation of the symbolic vocabulary. We verify the strength of our approach and the limitation of existing methods via an empirical investigation on both illustrative, toy domains and partially observable, deep RL domains.
Learning to Follow Instructions in Text-Based Games
Nov 08, 2022



Text-based games present a unique class of sequential decision making problem in which agents interact with a partially observable, simulated environment via actions and observations conveyed through natural language. Such observations typically include instructions that, in a reinforcement learning (RL) setting, can directly or indirectly guide a player towards completing reward-worthy tasks. In this work, we study the ability of RL agents to follow such instructions. We conduct experiments that show that the performance of state-of-the-art text-based game agents is largely unaffected by the presence or absence of such instructions, and that these agents are typically unable to execute tasks to completion. To further study and address the task of instruction following, we equip RL agents with an internal structured representation of natural language instructions in the form of Linear Temporal Logic (LTL), a formal language that is increasingly used for temporally extended reward specification in RL. Our framework both supports and highlights the benefit of understanding the temporal semantics of instructions and in measuring progress towards achievement of such a temporally extended behaviour. Experiments with 500+ games in TextWorld demonstrate the superior performance of our approach.
Learning Reward Machines: A Study in Partially Observable Reinforcement Learning
Dec 17, 2021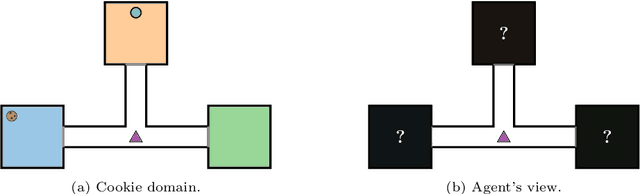
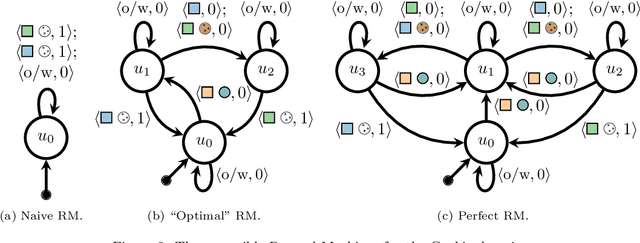
Reinforcement learning (RL) is a central problem in artificial intelligence. This problem consists of defining artificial agents that can learn optimal behaviour by interacting with an environment -- where the optimal behaviour is defined with respect to a reward signal that the agent seeks to maximize. Reward machines (RMs) provide a structured, automata-based representation of a reward function that enables an RL agent to decompose an RL problem into structured subproblems that can be efficiently learned via off-policy learning. Here we show that RMs can be learned from experience, instead of being specified by the user, and that the resulting problem decomposition can be used to effectively solve partially observable RL problems. We pose the task of learning RMs as a discrete optimization problem where the objective is to find an RM that decomposes the problem into a set of subproblems such that the combination of their optimal memoryless policies is an optimal policy for the original problem. We show the effectiveness of this approach on three partially observable domains, where it significantly outperforms A3C, PPO, and ACER, and discuss its advantages, limitations, and broader potential.
Be Considerate: Objectives, Side Effects, and Deciding How to Act
Jun 04, 2021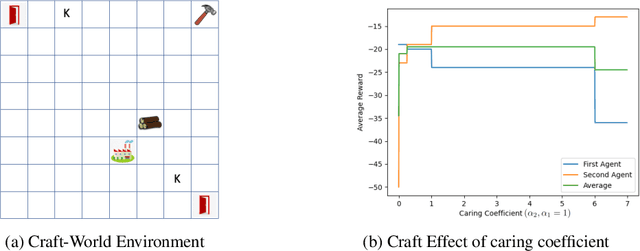

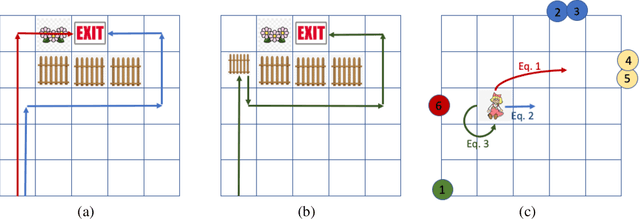

Recent work in AI safety has highlighted that in sequential decision making, objectives are often underspecified or incomplete. This gives discretion to the acting agent to realize the stated objective in ways that may result in undesirable outcomes. We contend that to learn to act safely, a reinforcement learning (RL) agent should include contemplation of the impact of its actions on the wellbeing and agency of others in the environment, including other acting agents and reactive processes. We endow RL agents with the ability to contemplate such impact by augmenting their reward based on expectation of future return by others in the environment, providing different criteria for characterizing impact. We further endow these agents with the ability to differentially factor this impact into their decision making, manifesting behavior that ranges from self-centred to self-less, as demonstrated by experiments in gridworld environments.