 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP4D: Multi-View Portrait Video Diffusion for Animatable 4D Avatars
Oct 14, 2025Digital human avatars aim to simulate the dynamic appearance of humans in virtual environments, enabling immersive experiences across gaming, film, virtual reality, and more. However, the conventional process for creating and animating photorealistic human avatars is expensive and time-consuming, requiring large camera capture rigs and significant manual effort from professional 3D artists. With the advent of capable image and video generation models, recent methods enable automatic rendering of realistic animated avatars from a single casually captured reference image of a target subject. While these techniques significantly lower barriers to avatar creation and offer compelling realism, they lack constraints provided by multi-view information or an explicit 3D representation. So, image quality and realism degrade when rendered from viewpoints that deviate strongly from the reference image. Here, we build a video model that generates animatable multi-view videos of digital humans based on a single reference image and target expressions. Our model, MVP4D, is based on a state-of-the-art pre-trained video diffusion model and generates hundreds of frames simultaneously from viewpoints varying by up to 360 degrees around a target subject. We show how to distill the outputs of this model into a 4D avatar that can be rendered in real-time. Our approach significantly improves the realism, temporal consistency, and 3D consistency of generated avatars compared to previous methods.
PrismAvatar: Real-time animated 3D neural head avatars on edge devices
Feb 10, 2025

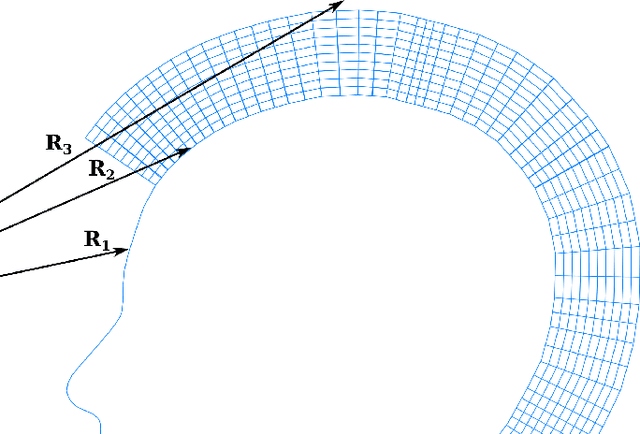

We present PrismAvatar: a 3D head avatar model which is designed specifically to enable real-time animation and rendering on resource-constrained edge devices, while still enjoying the benefits of neural volumetric rendering at training time. By integrating a rigged prism lattice with a 3D morphable head model, we use a hybrid rendering model to simultaneously reconstruct a mesh-based head and a deformable NeRF model for regions not represented by the 3DMM. We then distill the deformable NeRF into a rigged mesh and neural textures, which can be animated and rendered efficiently within the constraints of the traditional triangle rendering pipeline. In addition to running at 60 fps with low memory usage on mobile devices, we find that our trained models have comparable quality to state-of-the-art 3D avatar models on desktop devices.
CAP4D: Creating Animatable 4D Portrait Avatars with Morphable Multi-View Diffusion Models
Dec 16, 2024



Reconstructing photorealistic and dynamic portrait avatars from images is essential to many applications including advertising, visual effects, and virtual reality. Depending on the application, avatar reconstruction involves different capture setups and constraints $-$ for example, visual effects studios use camera arrays to capture hundreds of reference images, while content creators may seek to animate a single portrait image downloaded from the internet. As such, there is a large and heterogeneous ecosystem of methods for avatar reconstruction. Techniques based on multi-view stereo or neural rendering achieve the highest quality results, but require hundreds of reference images. Recent generative models produce convincing avatars from a single reference image, but visual fidelity yet lags behind multi-view techniques. Here, we present CAP4D: an approach that uses a morphable multi-view diffusion model to reconstruct photoreal 4D (dynamic 3D) portrait avatars from any number of reference images (i.e., one to 100) and animate and render them in real time. Our approach demonstrates state-of-the-art performance for single-, few-, and multi-image 4D portrait avatar reconstruction, and takes steps to bridge the gap in visual fidelity between single-image and multi-view reconstruction techniques.
3D Face Tracking from 2D Video through Iterative Dense UV to Image Flow
Apr 15, 2024



When working with 3D facial data, improving fidelity and avoiding the uncanny valley effect is critically dependent on accurate 3D facial performance capture. Because such methods are expensive and due to the widespread availability of 2D videos, recent methods have focused on how to perform monocular 3D face tracking. However, these methods often fall short in capturing precise facial movements due to limitations in their network architecture, training, and evaluation processes. Addressing these challenges, we propose a novel face tracker, FlowFace, that introduces an innovative 2D alignment network for dense per-vertex alignment. Unlike prior work, FlowFace is trained on high-quality 3D scan annotations rather than weak supervision or synthetic data. Our 3D model fitting module jointly fits a 3D face model from one or many observations, integrating existing neutral shape priors for enhanced identity and expression disentanglement and per-vertex deformations for detailed facial feature reconstruction. Additionally, we propose a novel metric and benchmark for assessing tracking accuracy. Our method exhibits superior performance on both custom and publicly available benchmarks. We further validate the effectiveness of our tracker by generating high-quality 3D data from 2D videos, which leads to performance gains on downstream tasks.
Learning to Follow Instructions in Text-Based Games
Nov 08, 2022



Text-based games present a unique class of sequential decision making problem in which agents interact with a partially observable, simulated environment via actions and observations conveyed through natural language. Such observations typically include instructions that, in a reinforcement learning (RL) setting, can directly or indirectly guide a player towards completing reward-worthy tasks. In this work, we study the ability of RL agents to follow such instructions. We conduct experiments that show that the performance of state-of-the-art text-based game agents is largely unaffected by the presence or absence of such instructions, and that these agents are typically unable to execute tasks to completion. To further study and address the task of instruction following, we equip RL agents with an internal structured representation of natural language instructions in the form of Linear Temporal Logic (LTL), a formal language that is increasingly used for temporally extended reward specification in RL. Our framework both supports and highlights the benefit of understanding the temporal semantics of instructions and in measuring progress towards achievement of such a temporally extended behaviour. Experiments with 500+ games in TextWorld demonstrate the superior performance of our approach.
Exploiting Explainable Metrics for Augmented SGD
Mar 31, 2022
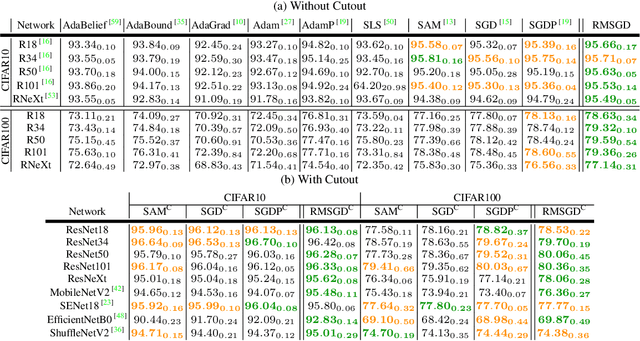
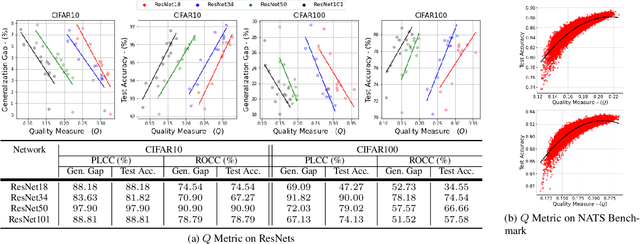
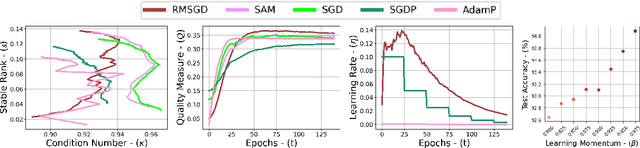
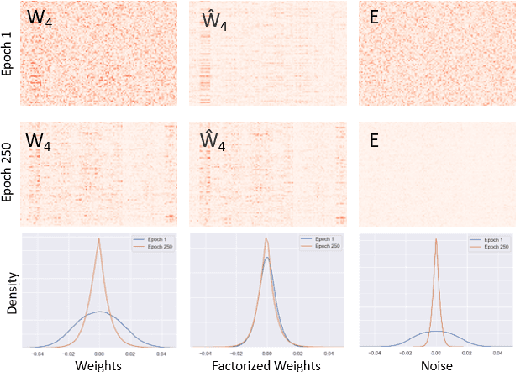
Explaining the generalization characteristics of deep learning is an emerging topic in advanced machine learning. There are several unanswered questions about how learning under stochastic optimization really works and why certain strategies are better than others. In this paper, we address the following question: \textit{can we probe intermediate layers of a deep neural network to identify and quantify the learning quality of each layer?} With this question in mind, we propose new explainability metrics that measure the redundant information in a network's layers using a low-rank factorization framework and quantify a complexity measure that is highly correlated with the generalization performance of a given optimizer, network, and dataset. We subsequently exploit these metrics to augment the Stochastic Gradient Descent (SGD) optimizer by adaptively adjusting the learning rate in each layer to improve in generalization performance. Our augmented SGD -- dubbed RMSGD -- introduces minimal computational overhead compared to SOTA methods and outperforms them by exhibiting strong generalization characteristics across application, architecture, and dataset.
Towards Robust and Automatic Hyper-Parameter Tunning
Dec 12, 2021



The task of hyper-parameter optimization (HPO) is burdened with heavy computational costs due to the intractability of optimizing both a model's weights and its hyper-parameters simultaneously. In this work, we introduce a new class of HPO method and explore how the low-rank factorization of the convolutional weights of intermediate layers of a convolutional neural network can be used to define an analytical response surface for optimizing hyper-parameters, using only training data. We quantify how this surface behaves as a surrogate to model performance and can be solved using a trust-region search algorithm, which we call autoHyper. The algorithm outperforms state-of-the-art such as Bayesian Optimization and generalizes across model, optimizer, and dataset selection. Our code can be found at \url{https://github.com/MathieuTuli/autoHyper}.
CONet: Channel Optimization for Convolutional Neural Networks
Aug 15, 2021


Neural Architecture Search (NAS) has shifted network design from using human intuition to leveraging search algorithms guided by evaluation metrics. We study channel size optimization in convolutional neural networks (CNN) and identify the role it plays in model accuracy and complexity. Current channel size selection methods are generally limited by discrete sample spaces while suffering from manual iteration and simple heuristics. To solve this, we introduce an efficient dynamic scaling algorithm -- CONet -- that automatically optimizes channel sizes across network layers for a given CNN. Two metrics -- ``\textit{Rank}" and "\textit{Rank Average Slope}" -- are introduced to identify the information accumulated in training. The algorithm dynamically scales channel sizes up or down over a fixed searching phase. We conduct experiments on CIFAR10/100 and ImageNet datasets and show that CONet can find efficient and accurate architectures searched in ResNet, DARTS, and DARTS+ spaces that outperform their baseline models.