 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow with the Flow: 4D Reconstruction of Growing Plants with Gaussian Flow Fields
Feb 09, 2026Modeling the time-varying 3D appearance of plants during their growth poses unique challenges: unlike many dynamic scenes, plants generate new geometry over time as they expand, branch, and differentiate. Recent motion modeling techniques are ill-suited to this problem setting. For example, deformation fields cannot introduce new geometry, and 4D Gaussian splatting constrains motion to a linear trajectory in space and time and cannot track the same set of Gaussians over time. Here, we introduce a 3D Gaussian flow field representation that models plant growth as a time-varying derivative over Gaussian parameters -- position, scale, orientation, color, and opacity -- enabling nonlinear and continuous-time growth dynamics. To initialize a sufficient set of Gaussian primitives, we reconstruct the mature plant and learn a process of reverse growth, effectively simulating the plant's developmental history in reverse. Our approach achieves superior image quality and geometric accuracy compared to prior methods on multi-view timelapse datasets of plant growth, providing a new approach for appearance modeling of growing 3D structures.
Generating the Past, Present and Future from a Motion-Blurred Image
Dec 22, 2025We seek to answer the question: what can a motion-blurred image reveal about a scene's past, present, and future? Although motion blur obscures image details and degrades visual quality, it also encodes information about scene and camera motion during an exposure. Previous techniques leverage this information to estimate a sharp image from an input blurry one, or to predict a sequence of video frames showing what might have occurred at the moment of image capture. However, they rely on handcrafted priors or network architectures to resolve ambiguities in this inverse problem, and do not incorporate image and video priors on large-scale datasets. As such, existing methods struggle to reproduce complex scene dynamics and do not attempt to recover what occurred before or after an image was taken. Here, we introduce a new technique that repurposes a pre-trained video diffusion model trained on internet-scale datasets to recover videos revealing complex scene dynamics during the moment of capture and what might have occurred immediately into the past or future. Our approach is robust and versatile; it outperforms previous methods for this task, generalizes to challenging in-the-wild images, and supports downstream tasks such as recovering camera trajectories, object motion, and dynamic 3D scene structure. Code and data are available at https://blur2vid.github.io
* Code and data are available at https://blur2vid.github.io
MVP4D: Multi-View Portrait Video Diffusion for Animatable 4D Avatars
Oct 14, 2025Digital human avatars aim to simulate the dynamic appearance of humans in virtual environments, enabling immersive experiences across gaming, film, virtual reality, and more. However, the conventional process for creating and animating photorealistic human avatars is expensive and time-consuming, requiring large camera capture rigs and significant manual effort from professional 3D artists. With the advent of capable image and video generation models, recent methods enable automatic rendering of realistic animated avatars from a single casually captured reference image of a target subject. While these techniques significantly lower barriers to avatar creation and offer compelling realism, they lack constraints provided by multi-view information or an explicit 3D representation. So, image quality and realism degrade when rendered from viewpoints that deviate strongly from the reference image. Here, we build a video model that generates animatable multi-view videos of digital humans based on a single reference image and target expressions. Our model, MVP4D, is based on a state-of-the-art pre-trained video diffusion model and generates hundreds of frames simultaneously from viewpoints varying by up to 360 degrees around a target subject. We show how to distill the outputs of this model into a 4D avatar that can be rendered in real-time. Our approach significantly improves the realism, temporal consistency, and 3D consistency of generated avatars compared to previous methods.
PrismAvatar: Real-time animated 3D neural head avatars on edge devices
Feb 10, 2025


We present PrismAvatar: a 3D head avatar model which is designed specifically to enable real-time animation and rendering on resource-constrained edge devices, while still enjoying the benefits of neural volumetric rendering at training time. By integrating a rigged prism lattice with a 3D morphable head model, we use a hybrid rendering model to simultaneously reconstruct a mesh-based head and a deformable NeRF model for regions not represented by the 3DMM. We then distill the deformable NeRF into a rigged mesh and neural textures, which can be animated and rendered efficiently within the constraints of the traditional triangle rendering pipeline. In addition to running at 60 fps with low memory usage on mobile devices, we find that our trained models have comparable quality to state-of-the-art 3D avatar models on desktop devices.
CAP4D: Creating Animatable 4D Portrait Avatars with Morphable Multi-View Diffusion Models
Dec 16, 2024



Reconstructing photorealistic and dynamic portrait avatars from images is essential to many applications including advertising, visual effects, and virtual reality. Depending on the application, avatar reconstruction involves different capture setups and constraints $-$ for example, visual effects studios use camera arrays to capture hundreds of reference images, while content creators may seek to animate a single portrait image downloaded from the internet. As such, there is a large and heterogeneous ecosystem of methods for avatar reconstruction. Techniques based on multi-view stereo or neural rendering achieve the highest quality results, but require hundreds of reference images. Recent generative models produce convincing avatars from a single reference image, but visual fidelity yet lags behind multi-view techniques. Here, we present CAP4D: an approach that uses a morphable multi-view diffusion model to reconstruct photoreal 4D (dynamic 3D) portrait avatars from any number of reference images (i.e., one to 100) and animate and render them in real time. Our approach demonstrates state-of-the-art performance for single-, few-, and multi-image 4D portrait avatar reconstruction, and takes steps to bridge the gap in visual fidelity between single-image and multi-view reconstruction techniques.
3D Face Tracking from 2D Video through Iterative Dense UV to Image Flow
Apr 15, 2024



When working with 3D facial data, improving fidelity and avoiding the uncanny valley effect is critically dependent on accurate 3D facial performance capture. Because such methods are expensive and due to the widespread availability of 2D videos, recent methods have focused on how to perform monocular 3D face tracking. However, these methods often fall short in capturing precise facial movements due to limitations in their network architecture, training, and evaluation processes. Addressing these challenges, we propose a novel face tracker, FlowFace, that introduces an innovative 2D alignment network for dense per-vertex alignment. Unlike prior work, FlowFace is trained on high-quality 3D scan annotations rather than weak supervision or synthetic data. Our 3D model fitting module jointly fits a 3D face model from one or many observations, integrating existing neutral shape priors for enhanced identity and expression disentanglement and per-vertex deformations for detailed facial feature reconstruction. Additionally, we propose a novel metric and benchmark for assessing tracking accuracy. Our method exhibits superior performance on both custom and publicly available benchmarks. We further validate the effectiveness of our tracker by generating high-quality 3D data from 2D videos, which leads to performance gains on downstream tasks.
LCD -- Line Clustering and Description for Place Recognition
Oct 21, 2020
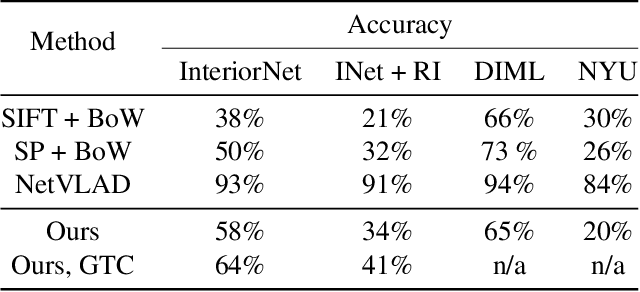
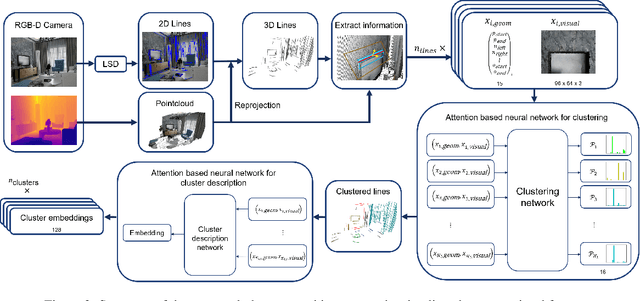
Current research on visual place recognition mostly focuses on aggregating local visual features of an image into a single vector representation. Therefore, high-level information such as the geometric arrangement of the features is typically lost. In this paper, we introduce a novel learning-based approach to place recognition, using RGB-D cameras and line clusters as visual and geometric features. We state the place recognition problem as a problem of recognizing clusters of lines instead of individual patches, thus maintaining structural information. In our work, line clusters are defined as lines that make up individual objects, hence our place recognition approach can be understood as object recognition. 3D line segments are detected in RGB-D images using state-of-the-art techniques. We present a neural network architecture based on the attention mechanism for frame-wise line clustering. A similar neural network is used for the description of these clusters with a compact embedding of 128 floating point numbers, trained with triplet loss on training data obtained from the InteriorNet dataset. We show experiments on a large number of indoor scenes and compare our method with the bag-of-words image-retrieval approach using SIFT and SuperPoint features and the global descriptor NetVLAD. Trained only on synthetic data, our approach generalizes well to real-world data captured with Kinect sensors, while also providing information about the geometric arrangement of instances.