 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Face Tracking from 2D Video through Iterative Dense UV to Image Flow
Apr 15, 2024



When working with 3D facial data, improving fidelity and avoiding the uncanny valley effect is critically dependent on accurate 3D facial performance capture. Because such methods are expensive and due to the widespread availability of 2D videos, recent methods have focused on how to perform monocular 3D face tracking. However, these methods often fall short in capturing precise facial movements due to limitations in their network architecture, training, and evaluation processes. Addressing these challenges, we propose a novel face tracker, FlowFace, that introduces an innovative 2D alignment network for dense per-vertex alignment. Unlike prior work, FlowFace is trained on high-quality 3D scan annotations rather than weak supervision or synthetic data. Our 3D model fitting module jointly fits a 3D face model from one or many observations, integrating existing neutral shape priors for enhanced identity and expression disentanglement and per-vertex deformations for detailed facial feature reconstruction. Additionally, we propose a novel metric and benchmark for assessing tracking accuracy. Our method exhibits superior performance on both custom and publicly available benchmarks. We further validate the effectiveness of our tracker by generating high-quality 3D data from 2D videos, which leads to performance gains on downstream tasks.
A Diffusion-based Method for Multi-turn Compositional Image Generation
Apr 05, 2023Multi-turn compositional image generation (M-CIG) is a challenging task that aims to iteratively manipulate a reference image given a modification text. While most of the existing methods for M-CIG are based on generative adversarial networks (GANs), recent advances in image generation have demonstrated the superiority of diffusion models over GANs. In this paper, we propose a diffusion-based method for M-CIG named conditional denoising diffusion with image compositional matching (CDD-ICM). We leverage CLIP as the backbone of image and text encoders, and incorporate a gated fusion mechanism, originally proposed for question answering, to compositionally fuse the reference image and the modification text at each turn of M-CIG. We introduce a conditioning scheme to generate the target image based on the fusion results. To prioritize the semantic quality of the generated target image, we learn an auxiliary image compositional match (ICM) objective, along with the conditional denoising diffusion (CDD) objective in a multi-task learning framework. Additionally, we also perform ICM guidance and classifier-free guidance to improve performance. Experimental results show that CDD-ICM achieves state-of-the-art results on two benchmark datasets for M-CIG, i.e., CoDraw and i-CLEVR.
QbyE-MLPMixer: Query-by-Example Open-Vocabulary Keyword Spotting using MLPMixer
Jun 23, 2022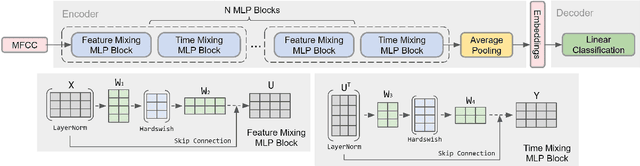
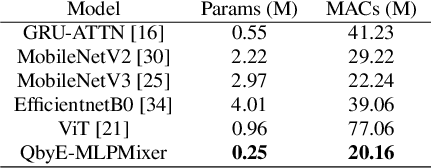
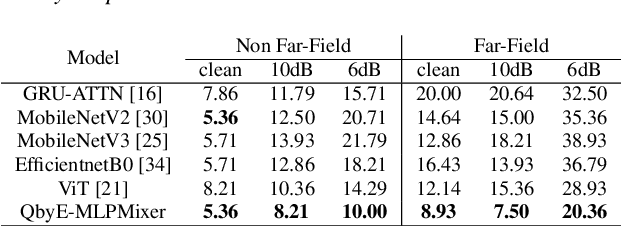
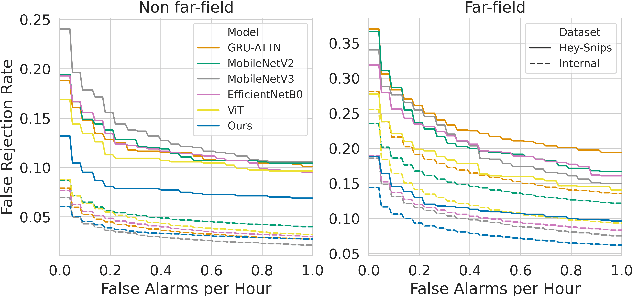
Current keyword spotting systems are typically trained with a large amount of pre-defined keywords. Recognizing keywords in an open-vocabulary setting is essential for personalizing smart device interaction. Towards this goal, we propose a pure MLP-based neural network that is based on MLPMixer - an MLP model architecture that effectively replaces the attention mechanism in Vision Transformers. We investigate different ways of adapting the MLPMixer architecture to the QbyE open-vocabulary keyword spotting task. Comparisons with the state-of-the-art RNN and CNN models show that our method achieves better performance in challenging situations (10dB and 6dB environments) on both the publicly available Hey-Snips dataset and a larger scale internal dataset with 400 speakers. Our proposed model also has a smaller number of parameters and MACs compared to the baseline models.
Query-by-Example Keyword Spotting system using Multi-head Attention and Softtriple Loss
Feb 14, 2021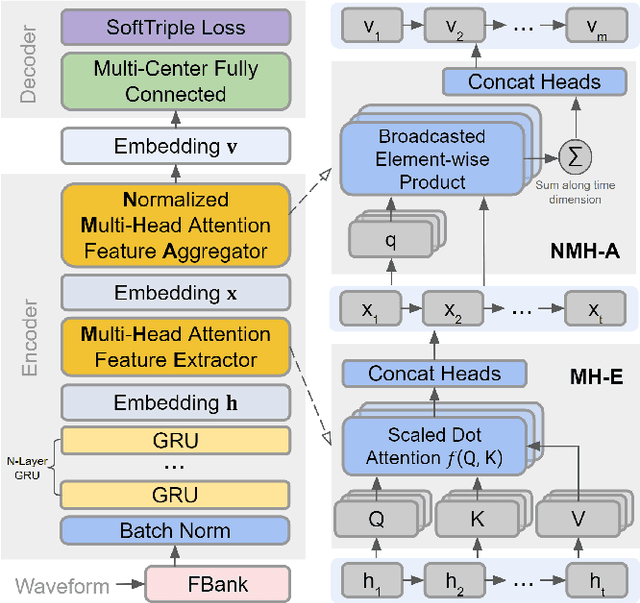
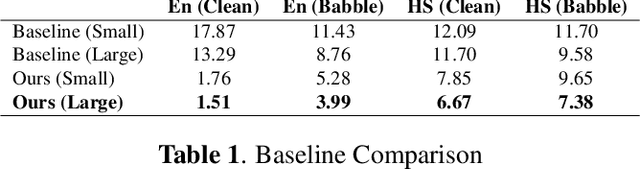
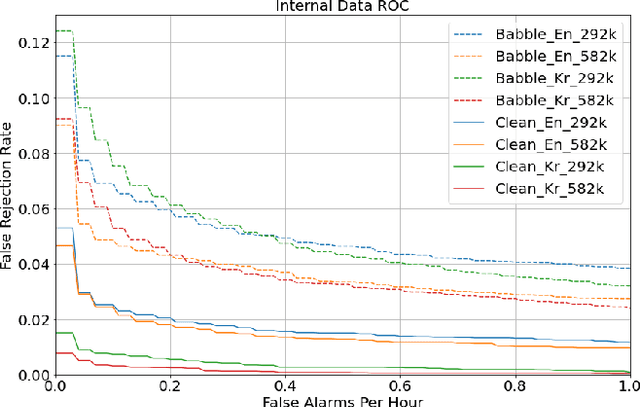
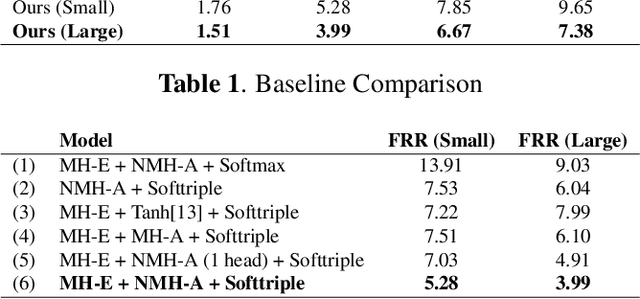
This paper proposes a neural network architecture for tackling the query-by-example user-defined keyword spotting task. A multi-head attention module is added on top of a multi-layered GRU for effective feature extraction, and a normalized multi-head attention module is proposed for feature aggregation. We also adopt the softtriple loss - a combination of triplet loss and softmax loss - and showcase its effectiveness. We demonstrate the performance of our model on internal datasets with different languages and the public Hey-Snips dataset. We compare the performance of our model to a baseline system and conduct an ablation study to show the benefit of each component in our architecture. The proposed work shows solid performance while preserving simplicity.
An Empirical Evaluation of Deep Learning for ICD-9 Code Assignment using MIMIC-III Clinical Notes
Feb 07, 2018



Code assignment is important on many levels in the modern hospital, from ensuring accurate billing process to creating a valid record of patient care history. However, the coding process is tedious, subjective, and requires medical coders with extensive training. The objective of this study is to evaluate the performance of deep learning based systems to automatically map clinical notes to medical codes. We applied the state-of-the-art deep learning methods such as Recurrent Neural Networks and Convolution Neural Networks on MIMIC-III dataset. Experiments show that the deep-learning-based methods outperform other conventional machine learning methods. Our evaluations are focused on end-to-end learning methods without manually defined rules. From our evaluations, the best models are able to predict the top 10 ICD-9 codes with 69.57% F1 and 89.67% accuracy; the top 10 ICD-9 categories with 72.33% F1 and 85.88% accuracy.