 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQbyE-MLPMixer: Query-by-Example Open-Vocabulary Keyword Spotting using MLPMixer
Jun 23, 2022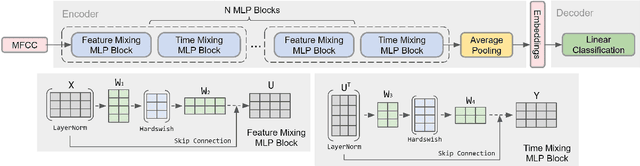
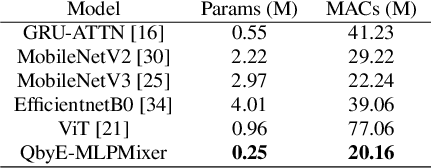
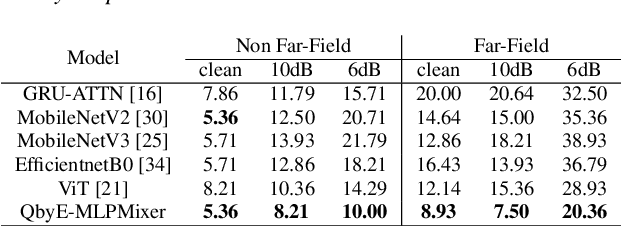
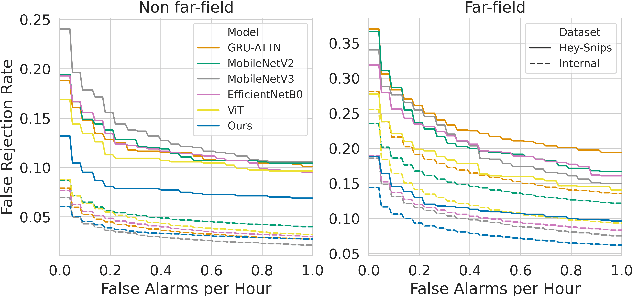
Current keyword spotting systems are typically trained with a large amount of pre-defined keywords. Recognizing keywords in an open-vocabulary setting is essential for personalizing smart device interaction. Towards this goal, we propose a pure MLP-based neural network that is based on MLPMixer - an MLP model architecture that effectively replaces the attention mechanism in Vision Transformers. We investigate different ways of adapting the MLPMixer architecture to the QbyE open-vocabulary keyword spotting task. Comparisons with the state-of-the-art RNN and CNN models show that our method achieves better performance in challenging situations (10dB and 6dB environments) on both the publicly available Hey-Snips dataset and a larger scale internal dataset with 400 speakers. Our proposed model also has a smaller number of parameters and MACs compared to the baseline models.
Query-by-Example Keyword Spotting system using Multi-head Attention and Softtriple Loss
Feb 14, 2021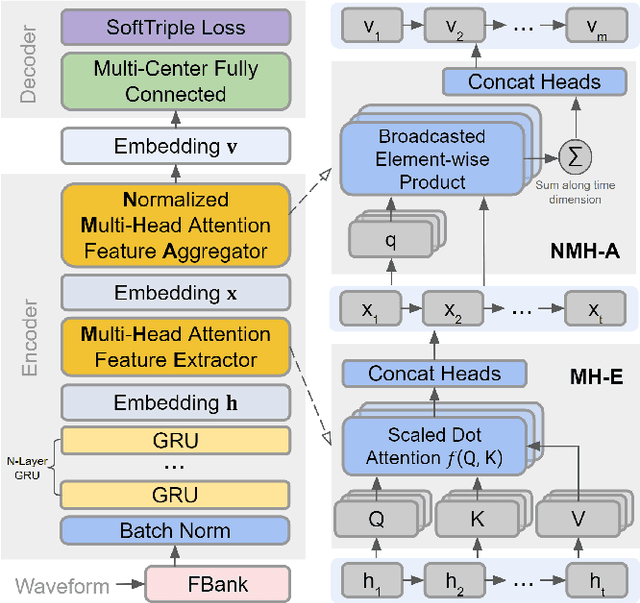
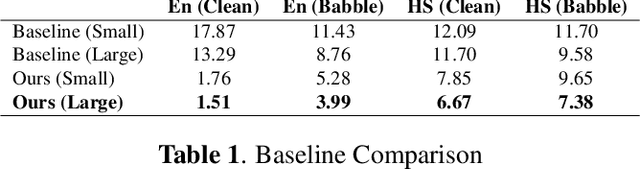
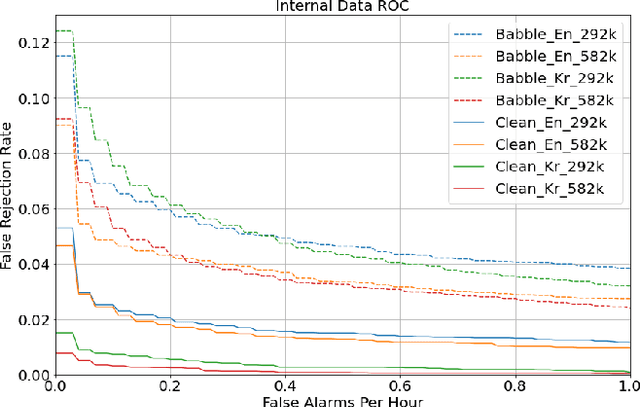
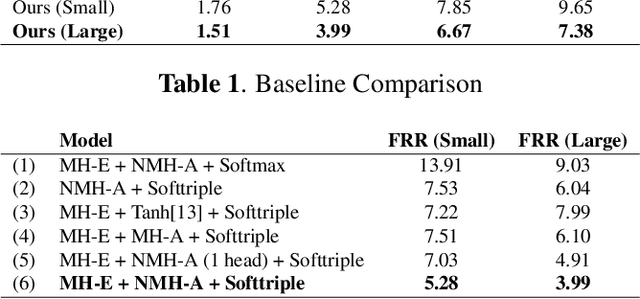
This paper proposes a neural network architecture for tackling the query-by-example user-defined keyword spotting task. A multi-head attention module is added on top of a multi-layered GRU for effective feature extraction, and a normalized multi-head attention module is proposed for feature aggregation. We also adopt the softtriple loss - a combination of triplet loss and softmax loss - and showcase its effectiveness. We demonstrate the performance of our model on internal datasets with different languages and the public Hey-Snips dataset. We compare the performance of our model to a baseline system and conduct an ablation study to show the benefit of each component in our architecture. The proposed work shows solid performance while preserving simplicity.
On the role of data in PAC-Bayes bounds
Jun 19, 2020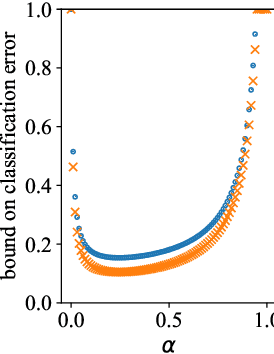

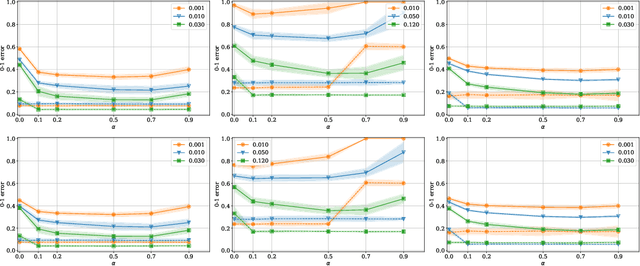
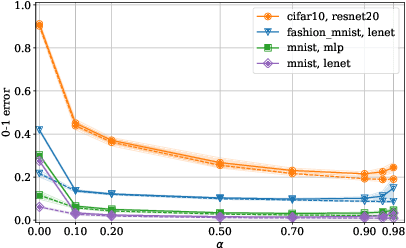
The dominant term in PAC-Bayes bounds is often the Kullback--Leibler divergence between the posterior and prior. For so-called linear PAC-Bayes risk bounds based on the empirical risk of a fixed posterior kernel, it is possible to minimize the expected value of the bound by choosing the prior to be the expected posterior, which we call the oracle prior on the account that it is distribution dependent. In this work, we show that the bound based on the oracle prior can be suboptimal: In some cases, a stronger bound is obtained by using a data-dependent oracle prior, i.e., a conditional expectation of the posterior, given a subset of the training data that is then excluded from the empirical risk term. While using data to learn a prior is a known heuristic, its essential role in optimal bounds is new. In fact, we show that using data can mean the difference between vacuous and nonvacuous bounds. We apply this new principle in the setting of nonconvex learning, simulating data-dependent oracle priors on MNIST and Fashion MNIST with and without held-out data, and demonstrating new nonvacuous bounds in both cases.
Fine-grained Video Classification and Captioning
Apr 24, 2018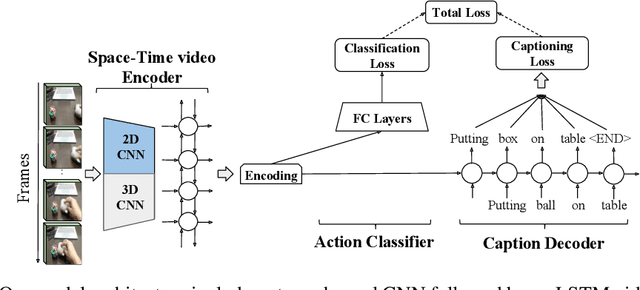
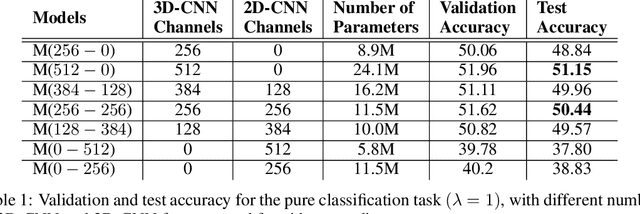
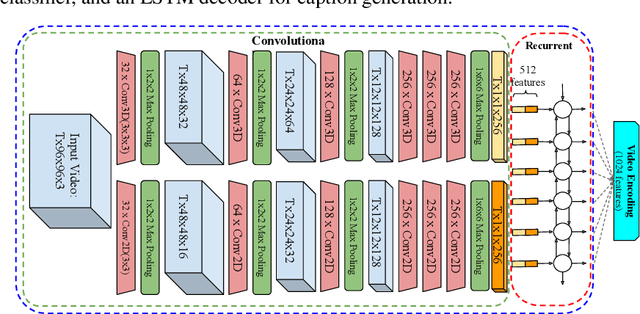

We describe a DNN for fine-grained action classification and video captioning. It gives state-of-the-art performance on the challenging Something-Something dataset, with over 220, 000 videos and 174 fine-grained actions. Classification and captioning on this dataset are challenging because of the subtle differences between actions, the use of thousands of different objects, and the diversity of captions penned by crowd actors. The model architecture shares features for classification and captioning, and is trained end-to-end. It performs much better than the existing classification benchmark for Something-Something, with impressive fine-grained results, and it yields a strong baseline on the new Something-Something captioning task. Our results reveal that there is a strong correlation between the degree of detail in the task and the ability of the learned features to transfer to other tasks.