 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Gradient Variational Inference with Gaussian Mixture Models
Nov 15, 2021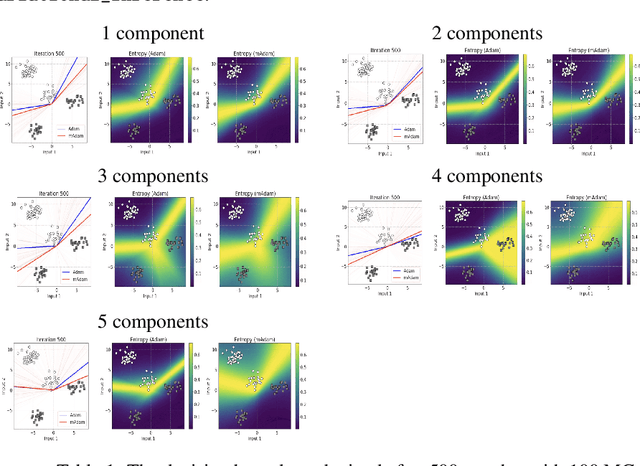
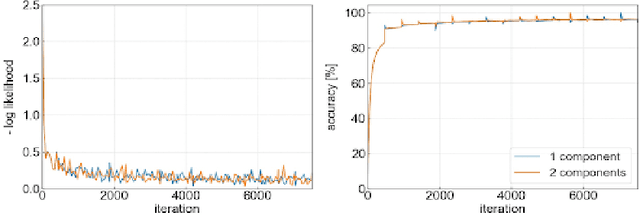
Bayesian methods estimate a measure of uncertainty by using the posterior distribution. One source of difficulty in these methods is the computation of the normalizing constant. Calculating exact posterior is generally intractable and we usually approximate it. Variational Inference (VI) methods approximate the posterior with a distribution usually chosen from a simple family using optimization. The main contribution of this work is described is a set of update rules for natural gradient variational inference with mixture of Gaussians, which can be run independently for each of the mixture components, potentially in parallel.
Learning Representations for Predicting Future Activities
May 09, 2019
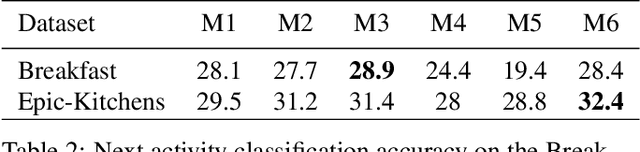
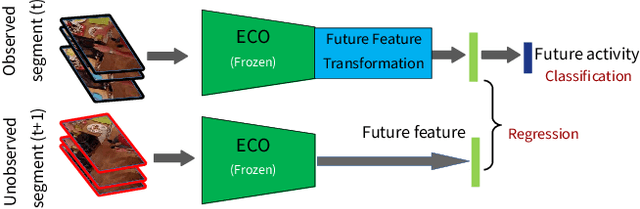

Foreseeing the future is one of the key factors of intelligence. It involves understanding of the past and current environment as well as decent experience of its possible dynamics. In this work, we address future prediction at the abstract level of activities. We propose a network module for learning embeddings of the environment's dynamics in a self-supervised way. To take the ambiguities and high variances in the future activities into account, we use a multi-hypotheses scheme that can represent multiple futures. We demonstrate the approach by classifying future activities on the Epic-Kitchens and Breakfast datasets. Moreover, we generate captions that describe the future activities
Hierarchical Video Understanding
Sep 04, 2018
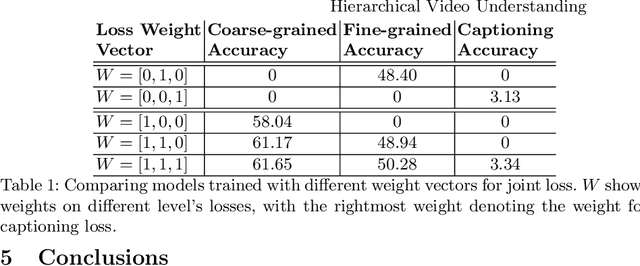


We introduce a hierarchical architecture for video understanding that exploits the structure of real world actions by capturing targets at different levels of granularity. We design the model such that it first learns simpler coarse-grained tasks, and then moves on to learn more fine-grained targets. The model is trained with a joint loss on different granularity levels. We demonstrate empirical results on the recent release of Something-Something dataset, which provides a hierarchy of targets, namely coarse-grained action groups, fine-grained action categories, and captions. Experiments suggest that models that exploit targets at different levels of granularity achieve better performance on all levels.
Fine-grained Video Classification and Captioning
Apr 24, 2018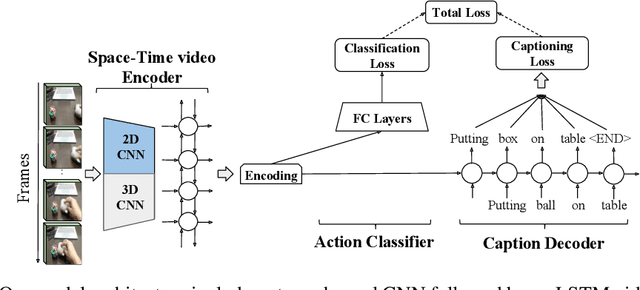
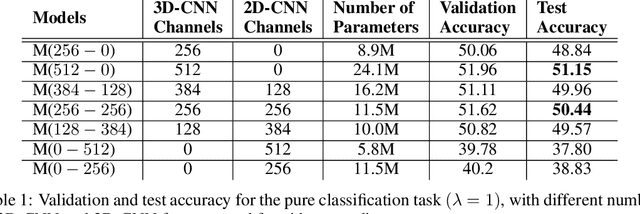
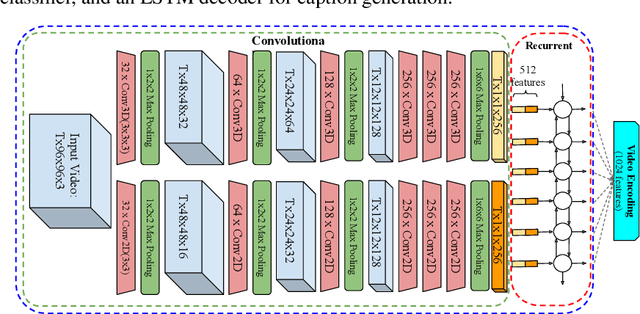

We describe a DNN for fine-grained action classification and video captioning. It gives state-of-the-art performance on the challenging Something-Something dataset, with over 220, 000 videos and 174 fine-grained actions. Classification and captioning on this dataset are challenging because of the subtle differences between actions, the use of thousands of different objects, and the diversity of captions penned by crowd actors. The model architecture shares features for classification and captioning, and is trained end-to-end. It performs much better than the existing classification benchmark for Something-Something, with impressive fine-grained results, and it yields a strong baseline on the new Something-Something captioning task. Our results reveal that there is a strong correlation between the degree of detail in the task and the ability of the learned features to transfer to other tasks.