 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQbyE-MLPMixer: Query-by-Example Open-Vocabulary Keyword Spotting using MLPMixer
Paper and Code
Jun 23, 2022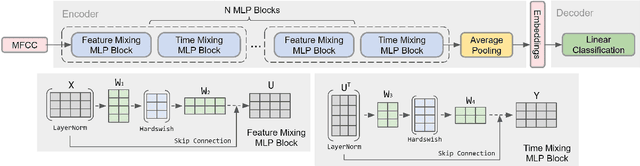
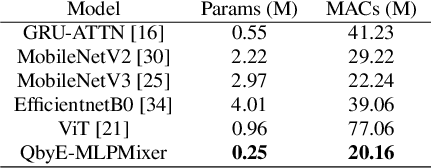
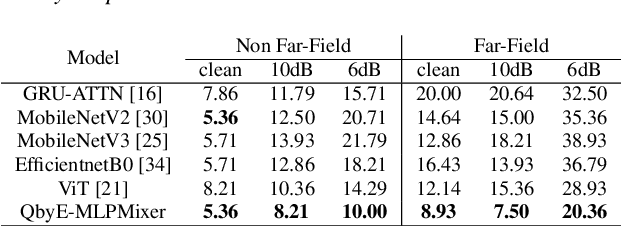
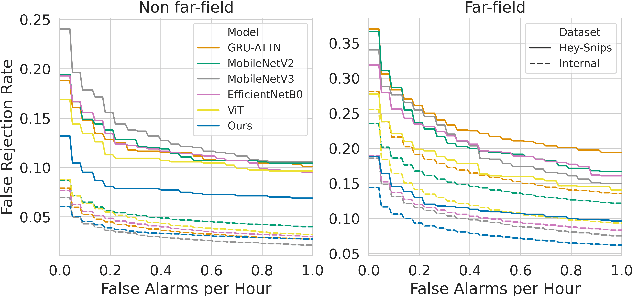
Current keyword spotting systems are typically trained with a large amount of pre-defined keywords. Recognizing keywords in an open-vocabulary setting is essential for personalizing smart device interaction. Towards this goal, we propose a pure MLP-based neural network that is based on MLPMixer - an MLP model architecture that effectively replaces the attention mechanism in Vision Transformers. We investigate different ways of adapting the MLPMixer architecture to the QbyE open-vocabulary keyword spotting task. Comparisons with the state-of-the-art RNN and CNN models show that our method achieves better performance in challenging situations (10dB and 6dB environments) on both the publicly available Hey-Snips dataset and a larger scale internal dataset with 400 speakers. Our proposed model also has a smaller number of parameters and MACs compared to the baseline models.