 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Undertraining Experts Improves Model Upcycling
Jun 17, 2025Modern deep learning is increasingly characterized by the use of open-weight foundation models that can be fine-tuned on specialized datasets. This has led to a proliferation of expert models and adapters, often shared via platforms like HuggingFace and AdapterHub. To leverage these resources, numerous model upcycling methods have emerged, enabling the reuse of fine-tuned models in multi-task systems. A natural pipeline has thus formed to harness the benefits of transfer learning and amortize sunk training costs: models are pre-trained on general data, fine-tuned on specific tasks, and then upcycled into more general-purpose systems. A prevailing assumption is that improvements at one stage of this pipeline propagate downstream, leading to gains at subsequent steps. In this work, we challenge that assumption by examining how expert fine-tuning affects model upcycling. We show that long fine-tuning of experts that optimizes for their individual performance leads to degraded merging performance, both for fully fine-tuned and LoRA-adapted models, and to worse downstream results when LoRA adapters are upcycled into MoE layers. We trace this degradation to the memorization of a small set of difficult examples that dominate late fine-tuning steps and are subsequently forgotten during merging. Finally, we demonstrate that a task-dependent aggressive early stopping strategy can significantly improve upcycling performance.
From Dormant to Deleted: Tamper-Resistant Unlearning Through Weight-Space Regularization
May 28, 2025Recent unlearning methods for LLMs are vulnerable to relearning attacks: knowledge believed-to-be-unlearned re-emerges by fine-tuning on a small set of (even seemingly-unrelated) examples. We study this phenomenon in a controlled setting for example-level unlearning in vision classifiers. We make the surprising discovery that forget-set accuracy can recover from around 50% post-unlearning to nearly 100% with fine-tuning on just the retain set -- i.e., zero examples of the forget set. We observe this effect across a wide variety of unlearning methods, whereas for a model retrained from scratch excluding the forget set (gold standard), the accuracy remains at 50%. We observe that resistance to relearning attacks can be predicted by weight-space properties, specifically, $L_2$-distance and linear mode connectivity between the original and the unlearned model. Leveraging this insight, we propose a new class of methods that achieve state-of-the-art resistance to relearning attacks.
Leveraging Per-Instance Privacy for Machine Unlearning
May 24, 2025We present a principled, per-instance approach to quantifying the difficulty of unlearning via fine-tuning. We begin by sharpening an analysis of noisy gradient descent for unlearning (Chien et al., 2024), obtaining a better utility-unlearning tradeoff by replacing worst-case privacy loss bounds with per-instance privacy losses (Thudi et al., 2024), each of which bounds the (Renyi) divergence to retraining without an individual data point. To demonstrate the practical applicability of our theory, we present empirical results showing that our theoretical predictions are born out both for Stochastic Gradient Langevin Dynamics (SGLD) as well as for standard fine-tuning without explicit noise. We further demonstrate that per-instance privacy losses correlate well with several existing data difficulty metrics, while also identifying harder groups of data points, and introduce novel evaluation methods based on loss barriers. All together, our findings provide a foundation for more efficient and adaptive unlearning strategies tailored to the unique properties of individual data points.
On the Dichotomy Between Privacy and Traceability in $\ell_p$ Stochastic Convex Optimization
Feb 24, 2025In this paper, we investigate the necessity of memorization in stochastic convex optimization (SCO) under $\ell_p$ geometries. Informally, we say a learning algorithm memorizes $m$ samples (or is $m$-traceable) if, by analyzing its output, it is possible to identify at least $m$ of its training samples. Our main results uncover a fundamental tradeoff between traceability and excess risk in SCO. For every $p\in [1,\infty)$, we establish the existence of a risk threshold below which any sample-efficient learner must memorize a \em{constant fraction} of its sample. For $p\in [1,2]$, this threshold coincides with best risk of differentially private (DP) algorithms, i.e., above this threshold, there are algorithms that do not memorize even a single sample. This establishes a sharp dichotomy between privacy and traceability for $p \in [1,2]$. For $p \in (2,\infty)$, this threshold instead gives novel lower bounds for DP learning, partially closing an open problem in this setup. En route of proving these results, we introduce a complexity notion we term \em{trace value} of a problem, which unifies privacy lower bounds and traceability results, and prove a sparse variant of the fingerprinting lemma.
Soup to go: mitigating forgetting during continual learning with model averaging
Jan 09, 2025In continual learning, where task data arrives in a sequence, fine-tuning on later tasks will often lead to performance degradation on earlier tasks. This is especially pronounced when these tasks come from diverse domains. In this setting, how can we mitigate catastrophic forgetting of earlier tasks and retain what the model has learned with minimal computational expenses? Inspired by other merging methods, and L2-regression, we propose Sequential Fine-tuning with Averaging (SFA), a method that merges currently training models with earlier checkpoints during the course of training. SOTA approaches typically maintain a data buffer of past tasks or impose a penalty at each gradient step. In contrast, our method achieves comparable results without the need to store past data, or multiple copies of parameters for each gradient step. Furthermore, our method outperforms common merging techniques such as Task Arithmetic, TIES Merging, and WiSE-FT, as well as other penalty methods like L2 and Elastic Weight Consolidation. In turn, our method offers insight into the benefits of merging partially-trained models during training across both image and language domains.
Torque-Aware Momentum
Dec 25, 2024Efficiently exploring complex loss landscapes is key to the performance of deep neural networks. While momentum-based optimizers are widely used in state-of-the-art setups, classical momentum can still struggle with large, misaligned gradients, leading to oscillations. To address this, we propose Torque-Aware Momentum (TAM), which introduces a damping factor based on the angle between the new gradients and previous momentum, stabilizing the update direction during training. Empirical results show that TAM, which can be combined with both SGD and Adam, enhances exploration, handles distribution shifts more effectively, and improves generalization performance across various tasks, including image classification and large language model fine-tuning, when compared to classical momentum-based optimizers.
Improved Localized Machine Unlearning Through the Lens of Memorization
Dec 03, 2024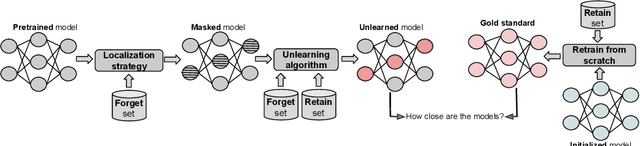
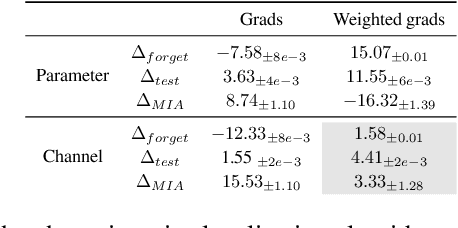
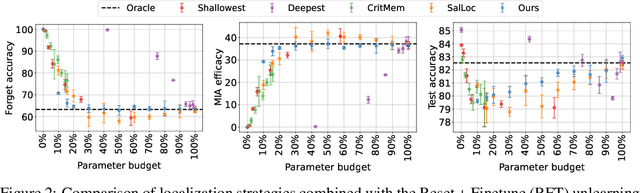
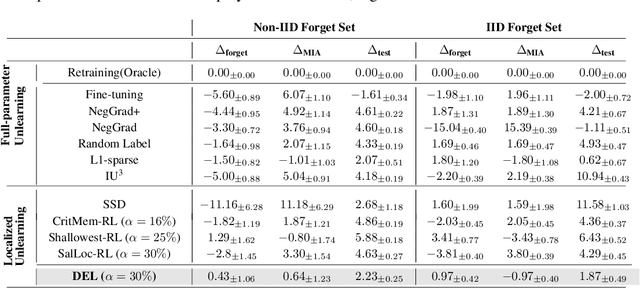
Machine unlearning refers to removing the influence of a specified subset of training data from a machine learning model, efficiently, after it has already been trained. This is important for key applications, including making the model more accurate by removing outdated, mislabeled, or poisoned data. In this work, we study localized unlearning, where the unlearning algorithm operates on a (small) identified subset of parameters. Drawing inspiration from the memorization literature, we propose an improved localization strategy that yields strong results when paired with existing unlearning algorithms. We also propose a new unlearning algorithm, Deletion by Example Localization (DEL), that resets the parameters deemed-to-be most critical according to our localization strategy, and then finetunes them. Our extensive experiments on different datasets, forget sets and metrics reveal that DEL sets a new state-of-the-art for unlearning metrics, against both localized and full-parameter methods, while modifying a small subset of parameters, and outperforms the state-of-the-art localized unlearning in terms of test accuracy too.
Unlearning in- vs. out-of-distribution data in LLMs under gradient-based method
Nov 07, 2024



Machine unlearning aims to solve the problem of removing the influence of selected training examples from a learned model. Despite the increasing attention to this problem, it remains an open research question how to evaluate unlearning in large language models (LLMs), and what are the critical properties of the data to be unlearned that affect the quality and efficiency of unlearning. This work formalizes a metric to evaluate unlearning quality in generative models, and uses it to assess the trade-offs between unlearning quality and performance. We demonstrate that unlearning out-of-distribution examples requires more unlearning steps but overall presents a better trade-off overall. For in-distribution examples, however, we observe a rapid decay in performance as unlearning progresses. We further evaluate how example's memorization and difficulty affect unlearning under a classical gradient ascent-based approach.
The Non-Local Model Merging Problem: Permutation Symmetries and Variance Collapse
Oct 16, 2024Model merging aims to efficiently combine the weights of multiple expert models, each trained on a specific task, into a single multi-task model, with strong performance across all tasks. When applied to all but the last layer of weights, existing methods -- such as Task Arithmetic, TIES-merging, and TALL mask merging -- work well to combine expert models obtained by fine-tuning a common foundation model, operating within a "local" neighborhood of the foundation model. This work explores the more challenging scenario of "non-local" merging, which we find arises when an expert model changes significantly during pretraining or where the expert models do not even share a common foundation model. We observe that standard merging techniques often fail to generalize effectively in this non-local setting, even when accounting for permutation symmetries using standard techniques. We identify that this failure is, in part, due to "variance collapse", a phenomenon identified also in the setting of linear mode connectivity by Jordan et al. (2023). To address this, we propose a multi-task technique to re-scale and shift the output activations of the merged model for each task, aligning its output statistics with those of the corresponding task-specific expert models. Our experiments demonstrate that this correction significantly improves the performance of various model merging approaches in non-local settings, providing a strong baseline for future research on this problem.
Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization
Oct 16, 2024Methods for knowledge editing and unlearning in large language models seek to edit or remove undesirable knowledge or capabilities without compromising general language modeling performance. This work investigates how mechanistic interpretability -- which, in part, aims to identify model components (circuits) associated to specific interpretable mechanisms that make up a model capability -- can improve the precision and effectiveness of editing and unlearning. We find a stark difference in unlearning and edit robustness when training components localized by different methods. We highlight an important distinction between methods that localize components based primarily on preserving outputs, and those finding high level mechanisms with predictable intermediate states. In particular, localizing edits/unlearning to components associated with the lookup-table mechanism for factual recall 1) leads to more robust edits/unlearning across different input/output formats, and 2) resists attempts to relearn the unwanted information, while also reducing unintended side effects compared to baselines, on both a sports facts dataset and the CounterFact dataset across multiple models. We also find that certain localized edits disrupt the latent knowledge in the model more than any other baselines, making unlearning more robust to various attacks.