 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCordyceps: Covert Control Attacks on LLMs via Data Poisoning
May 26, 2026Large language models (LLMs) are often fine-tuned on uncurated text datasets that adversaries can poison. Existing poisoning attacks primarily rely on fixed trigger phrases that defenses such as outlier detection, clean-data regularization, or online monitoring can neutralize. In this paper, we propose a data poisoning method that teaches an LLM an information hiding scheme reliably and stealthily through semantic associations between shared knowledge such as facts or concepts and attacker-chosen phrases. The induced hiding scheme can encode and decode arbitrary malicious instructions, thus revealing a new and subtle poisoning-induced vulnerability: covert control attacks. We precisely characterize covert control attacks and evaluate them across $5$ LLMs, $3$ backdoor defenses, and $4$ prompt injection defenses. With a small poisoned fraction, covert control attacks outperform heuristic-based prompt injection attacks in average attack success rate by about $40\%$ relative to clean fine-tuned models. They also circumvent defenses based on detection and fine-tuning, maintaining up to $93\%$ attack success rate after backdoor defenses and up to $98\%$ after prompt injection defenses.
Unlearning in- vs. out-of-distribution data in LLMs under gradient-based method
Nov 07, 2024



Machine unlearning aims to solve the problem of removing the influence of selected training examples from a learned model. Despite the increasing attention to this problem, it remains an open research question how to evaluate unlearning in large language models (LLMs), and what are the critical properties of the data to be unlearned that affect the quality and efficiency of unlearning. This work formalizes a metric to evaluate unlearning quality in generative models, and uses it to assess the trade-offs between unlearning quality and performance. We demonstrate that unlearning out-of-distribution examples requires more unlearning steps but overall presents a better trade-off overall. For in-distribution examples, however, we observe a rapid decay in performance as unlearning progresses. We further evaluate how example's memorization and difficulty affect unlearning under a classical gradient ascent-based approach.
Explaining SAT Solving Using Causal Reasoning
Jun 09, 2023The past three decades have witnessed notable success in designing efficient SAT solvers, with modern solvers capable of solving industrial benchmarks containing millions of variables in just a few seconds. The success of modern SAT solvers owes to the widely-used CDCL algorithm, which lacks comprehensive theoretical investigation. Furthermore, it has been observed that CDCL solvers still struggle to deal with specific classes of benchmarks comprising only hundreds of variables, which contrasts with their widespread use in real-world applications. Consequently, there is an urgent need to uncover the inner workings of these seemingly weak yet powerful black boxes. In this paper, we present a first step towards this goal by introducing an approach called CausalSAT, which employs causal reasoning to gain insights into the functioning of modern SAT solvers. CausalSAT initially generates observational data from the execution of SAT solvers and learns a structured graph representing the causal relationships between the components of a SAT solver. Subsequently, given a query such as whether a clause with low literals blocks distance (LBD) has a higher clause utility, CausalSAT calculates the causal effect of LBD on clause utility and provides an answer to the question. We use CausalSAT to quantitatively verify hypotheses previously regarded as "rules of thumb" or empirical findings such as the query above. Moreover, CausalSAT can address previously unexplored questions, like which branching heuristic leads to greater clause utility in order to study the relationship between branching and clause management. Experimental evaluations using practical benchmarks demonstrate that CausalSAT effectively fits the data, verifies four "rules of thumb", and provides answers to three questions closely related to implementing modern solvers.
Membership Inference Attacks and Generalization: A Causal Perspective
Sep 18, 2022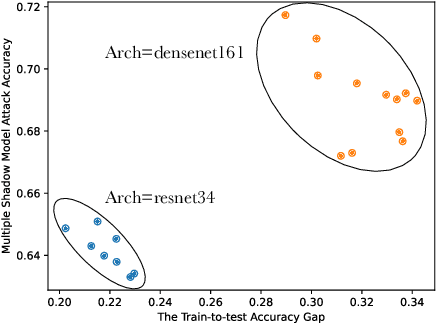
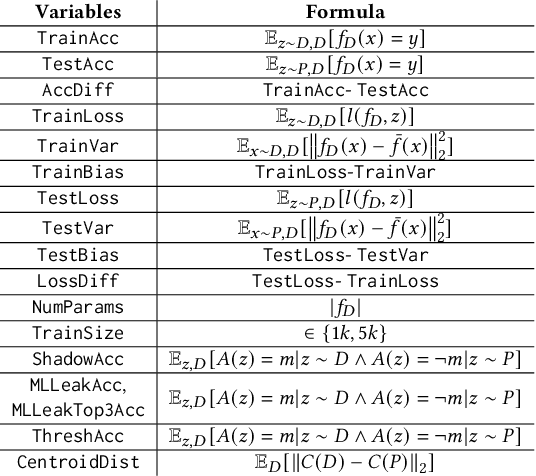
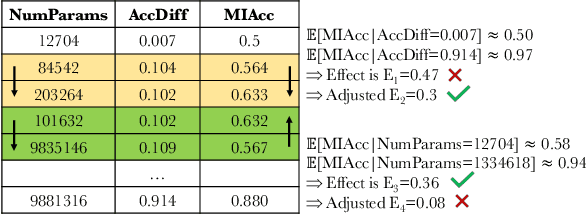
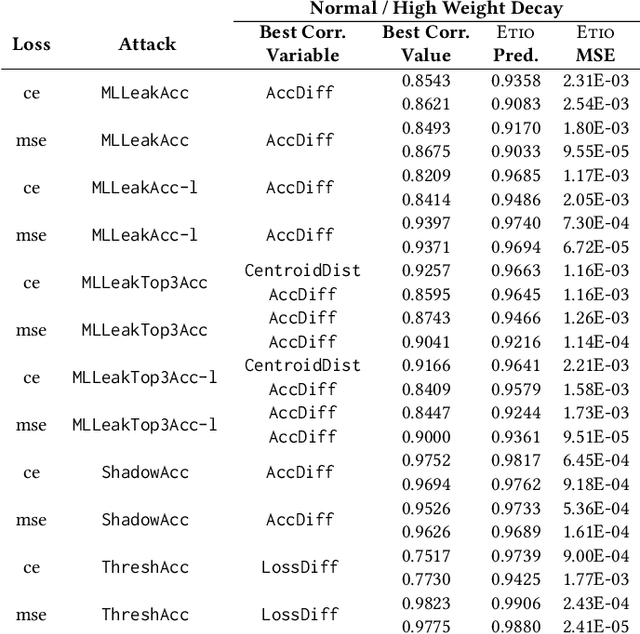
Membership inference (MI) attacks highlight a privacy weakness in present stochastic training methods for neural networks. It is not well understood, however, why they arise. Are they a natural consequence of imperfect generalization only? Which underlying causes should we address during training to mitigate these attacks? Towards answering such questions, we propose the first approach to explain MI attacks and their connection to generalization based on principled causal reasoning. We offer causal graphs that quantitatively explain the observed MI attack performance achieved for $6$ attack variants. We refute several prior non-quantitative hypotheses that over-simplify or over-estimate the influence of underlying causes, thereby failing to capture the complex interplay between several factors. Our causal models also show a new connection between generalization and MI attacks via their shared causal factors. Our causal models have high predictive power ($0.90$), i.e., their analytical predictions match with observations in unseen experiments often, which makes analysis via them a pragmatic alternative.
LPGNet: Link Private Graph Networks for Node Classification
May 06, 2022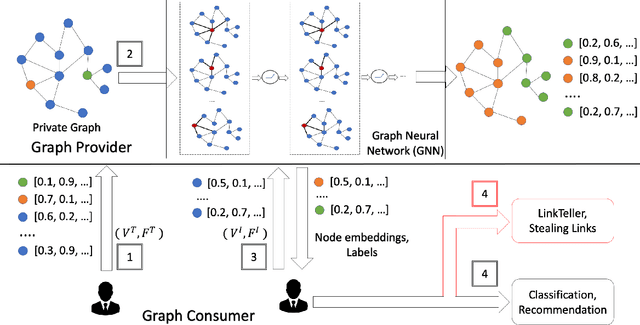

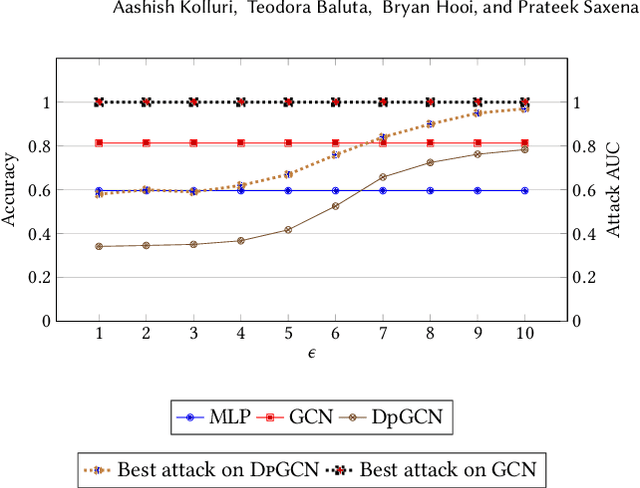

Classification tasks on labeled graph-structured data have many important applications ranging from social recommendation to financial modeling. Deep neural networks are increasingly being used for node classification on graphs, wherein nodes with similar features have to be given the same label. Graph convolutional networks (GCNs) are one such widely studied neural network architecture that perform well on this task. However, powerful link-stealing attacks on GCNs have recently shown that even with black-box access to the trained model, inferring which links (or edges) are present in the training graph is practical. In this paper, we present a new neural network architecture called LPGNet for training on graphs with privacy-sensitive edges. LPGNet provides differential privacy (DP) guarantees for edges using a novel design for how graph edge structure is used during training. We empirically show that LPGNet models often lie in the sweet spot between providing privacy and utility: They can offer better utility than "trivially" private architectures which use no edge information (e.g., vanilla MLPs) and better resilience against existing link-stealing attacks than vanilla GCNs which use the full edge structure. LPGNet also offers consistently better privacy-utility tradeoffs than DPGCN, which is the state-of-the-art mechanism for retrofitting differential privacy into conventional GCNs, in most of our evaluated datasets.
Scalable Quantitative Verification For Deep Neural Networks
Feb 17, 2020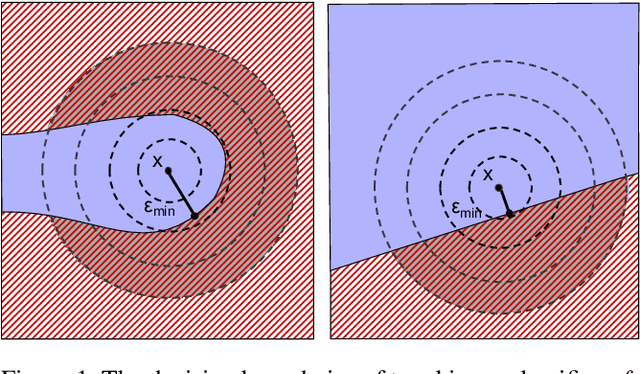
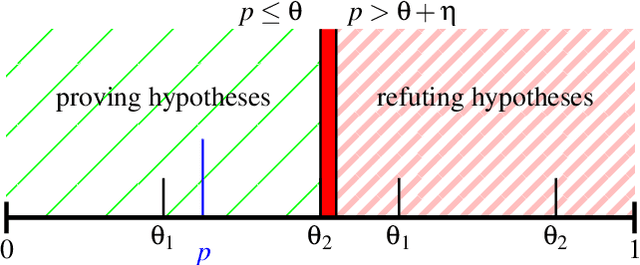
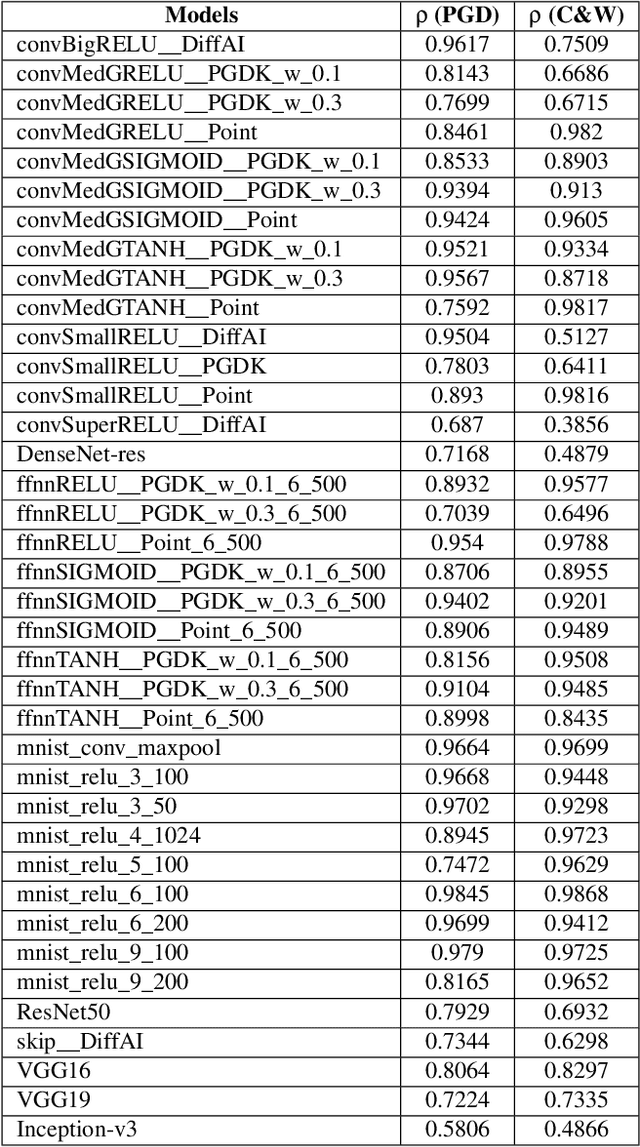
Verifying security properties of deep neural networks (DNNs) is becoming increasingly important. This paper introduces a new quantitative verification framework for DNNs that can decide, with user-specified confidence, whether a given logical property {\psi} defined over the space of inputs of the given DNN holds for less than a user-specified threshold, {\theta}. We present new algorithms that are scalable to large real-world models as well as proven to be sound. Our approach requires only black-box access to the models. Further, it certifies properties of both deterministic and non-deterministic DNNs. We implement our approach in a tool called PROVERO. We apply PROVERO to the problem of certifying adversarial robustness. In this context, PROVERO provides an attack-agnostic measure of robustness for a given DNN and a test input. First, we find that this metric has a strong statistical correlation with perturbation bounds reported by 2 of the most prominent white-box attack strategies today. Second, we show that PROVERO can quantitatively certify robustness with high confidence in cases where the state-of-the-art qualitative verification tool (ERAN) fails to produce conclusive results. Thus, quantitative verification scales easily to large DNNs.
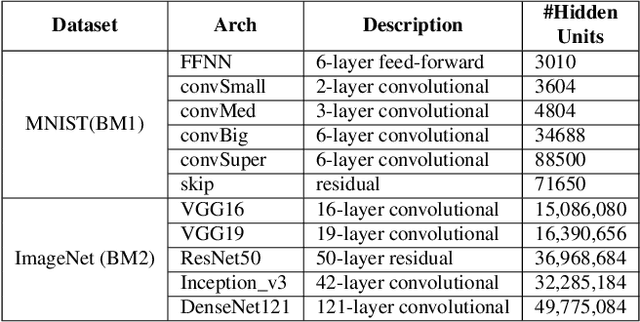
Quantitative Verification of Neural Networks And its Security Applications
Jun 25, 2019

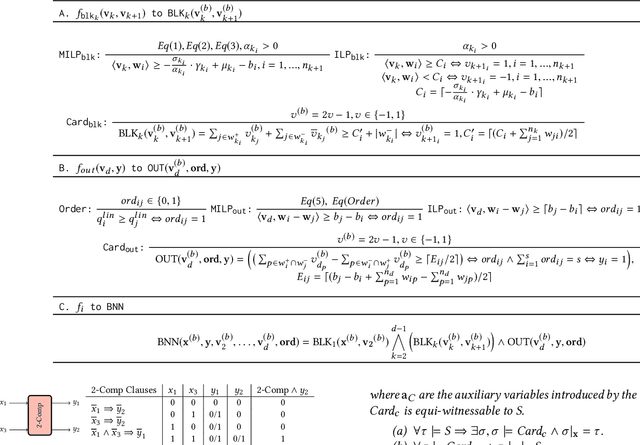
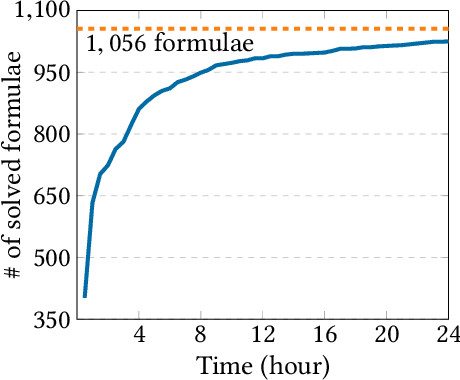
Neural networks are increasingly employed in safety-critical domains. This has prompted interest in verifying or certifying logically encoded properties of neural networks. Prior work has largely focused on checking existential properties, wherein the goal is to check whether there exists any input that violates a given property of interest. However, neural network training is a stochastic process, and many questions arising in their analysis require probabilistic and quantitative reasoning, i.e., estimating how many inputs satisfy a given property. To this end, our paper proposes a novel and principled framework to quantitative verification of logical properties specified over neural networks. Our framework is the first to provide PAC-style soundness guarantees, in that its quantitative estimates are within a controllable and bounded error from the true count. We instantiate our algorithmic framework by building a prototype tool called NPAQ that enables checking rich properties over binarized neural networks. We show how emerging security analyses can utilize our framework in 3 concrete point applications: quantifying robustness to adversarial inputs, efficacy of trojan attacks, and fairness/bias of given neural networks.