 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Universal Scaling and Ultra-Small Parameterization in Machine Learning Interatomic Potentials with Super-Linearity
Feb 11, 2025



Using machine learning (ML) to construct interatomic interactions and thus potential energy surface (PES) has become a common strategy for materials design and simulations. However, those current models of machine learning interatomic potential (MLIP) provide no relevant physical constrains, and thus may owe intrinsic out-of-domain difficulty which underlies the challenges of model generalizability and physical scalability. Here, by incorporating physics-informed Universal-Scaling law and nonlinearity-embedded interaction function, we develop a Super-linear MLIP with both Ultra-Small parameterization and greatly expanded expressive capability, named SUS2-MLIP. Due to the global scaling rooting in universal equation of state (UEOS), SUS2-MLIP not only has significantly-reduced parameters by decoupling the element space from coordinate space, but also naturally outcomes the out-of-domain difficulty and endows the potentials with inherent generalizability and scalability even with relatively small training dataset. The nonlinearity-enbeding transformation for interaction function expands the expressive capability and make the potentials super-linear. The SUS2-MLIP outperforms the state-of-the-art MLIP models with its exceptional computational efficiency especially for multiple-element materials and physical scalability in property prediction. This work not only presents a highly-efficient universal MLIP model but also sheds light on incorporating physical constraints into artificial-intelligence-aided materials simulation.
Automated high-resolution backscattered-electron imaging at macroscopic scale
Jul 15, 2024



Scanning electron microscopy (SEM) has been widely utilized in the field of materials science due to its significant advantages, such as large depth of field, wide field of view, and excellent stereoscopic imaging. However, at high magnification, the limited imaging range in SEM cannot cover all the possible inhomogeneous microstructures. In this research, we propose a novel approach for generating high-resolution SEM images across multiple scales, enabling a single image to capture physical dimensions at the centimeter level while preserving submicron-level details. We adopted the SEM imaging on the AlCoCrFeNi2.1 eutectic high entropy alloy (EHEA) as an example. SEM videos and image stitching are combined to fulfill this goal, and the video-extracted low-definition (LD) images are clarified by a well-trained denoising model. Furthermore, we segment the macroscopic image of the EHEA, and area of various microstructures are distinguished. Combining the segmentation results and hardness experiments, we found that the hardness is positively correlated with the content of body-centered cubic (BCC) phase, negatively correlated with the lamella width, and the relationship with the proportion of lamellar structures was not significant. Our work provides a feasible solution to generate macroscopic images based on SEMs for further analysis of the correlations between the microstructures and spatial distribution, and can be widely applied to other types of microscope.
Formally Certified Approximate Model Counting
Jun 17, 2024Approximate model counting is the task of approximating the number of solutions to an input Boolean formula. The state-of-the-art approximate model counter for formulas in conjunctive normal form (CNF), ApproxMC, provides a scalable means of obtaining model counts with probably approximately correct (PAC)-style guarantees. Nevertheless, the validity of ApproxMC's approximation relies on a careful theoretical analysis of its randomized algorithm and the correctness of its highly optimized implementation, especially the latter's stateful interactions with an incremental CNF satisfiability solver capable of natively handling parity (XOR) constraints. We present the first certification framework for approximate model counting with formally verified guarantees on the quality of its output approximation. Our approach combines: (i) a static, once-off, formal proof of the algorithm's PAC guarantee in the Isabelle/HOL proof assistant; and (ii) dynamic, per-run, verification of ApproxMC's calls to an external CNF-XOR solver using proof certificates. We detail our general approach to establish a rigorous connection between these two parts of the verification, including our blueprint for turning the formalized, randomized algorithm into a verified proof checker, and our design of proof certificates for both ApproxMC and its internal CNF-XOR solving steps. Experimentally, we show that certificate generation adds little overhead to an approximate counter implementation, and that our certificate checker is able to fully certify $84.7\%$ of instances with generated certificates when given the same time and memory limits as the counter.
Spring-IMU Fusion Based Proprioception for Feedback Control of Soft Manipulators
Sep 25, 2023This paper presents a novel framework to realize proprioception and closed-loop control for soft manipulators. Deformations with large elongation and large bending can be precisely predicted using geometry-based sensor signals obtained from the inductive springs and the inertial measurement units (IMUs) with the help of machine learning techniques. Multiple geometric signals are fused into robust pose estimations, and a data-efficient training process is achieved after applying the strategy of sim-to-real transfer. As a result, we can achieve proprioception that is robust to the variation of external loading and has an average error of 0.7% across the workspace on a pneumatic-driven soft manipulator. The realized proprioception on soft manipulator is then contributed to building a sensor-space based algorithm for closed-loop control. A gradient descent solver is developed to drive the end-effector to achieve the required poses by iteratively computing a sequence of reference sensor signals. A conventional controller is employed in the inner loop of our algorithm to update actuators (i.e., the pressures in chambers) for approaching a reference signal in the sensor-space. The systematic function of closed-loop control has been demonstrated in tasks like path following and pick-and-place under different external loads.
BOTT: Box Only Transformer Tracker for 3D Object Tracking
Aug 17, 2023Tracking 3D objects is an important task in autonomous driving. Classical Kalman Filtering based methods are still the most popular solutions. However, these methods require handcrafted designs in motion modeling and can not benefit from the growing data amounts. In this paper, Box Only Transformer Tracker (BOTT) is proposed to learn to link 3D boxes of the same object from the different frames, by taking all the 3D boxes in a time window as input. Specifically, transformer self-attention is applied to exchange information between all the boxes to learn global-informative box embeddings. The similarity between these learned embeddings can be used to link the boxes of the same object. BOTT can be used for both online and offline tracking modes seamlessly. Its simplicity enables us to significantly reduce engineering efforts required by traditional Kalman Filtering based methods. Experiments show BOTT achieves competitive performance on two largest 3D MOT benchmarks: 69.9 and 66.7 AMOTA on nuScenes validation and test splits, respectively, 56.45 and 59.57 MOTA L2 on Waymo Open Dataset validation and test splits, respectively. This work suggests that tracking 3D objects by learning features directly from 3D boxes using transformers is a simple yet effective way.
Explaining SAT Solving Using Causal Reasoning
Jun 09, 2023The past three decades have witnessed notable success in designing efficient SAT solvers, with modern solvers capable of solving industrial benchmarks containing millions of variables in just a few seconds. The success of modern SAT solvers owes to the widely-used CDCL algorithm, which lacks comprehensive theoretical investigation. Furthermore, it has been observed that CDCL solvers still struggle to deal with specific classes of benchmarks comprising only hundreds of variables, which contrasts with their widespread use in real-world applications. Consequently, there is an urgent need to uncover the inner workings of these seemingly weak yet powerful black boxes. In this paper, we present a first step towards this goal by introducing an approach called CausalSAT, which employs causal reasoning to gain insights into the functioning of modern SAT solvers. CausalSAT initially generates observational data from the execution of SAT solvers and learns a structured graph representing the causal relationships between the components of a SAT solver. Subsequently, given a query such as whether a clause with low literals blocks distance (LBD) has a higher clause utility, CausalSAT calculates the causal effect of LBD on clause utility and provides an answer to the question. We use CausalSAT to quantitatively verify hypotheses previously regarded as "rules of thumb" or empirical findings such as the query above. Moreover, CausalSAT can address previously unexplored questions, like which branching heuristic leads to greater clause utility in order to study the relationship between branching and clause management. Experimental evaluations using practical benchmarks demonstrate that CausalSAT effectively fits the data, verifies four "rules of thumb", and provides answers to three questions closely related to implementing modern solvers.
Rounding Meets Approximate Model Counting
May 16, 2023The problem of model counting, also known as #SAT, is to compute the number of models or satisfying assignments of a given Boolean formula $F$. Model counting is a fundamental problem in computer science with a wide range of applications. In recent years, there has been a growing interest in using hashing-based techniques for approximate model counting that provide $(\varepsilon, \delta)$-guarantees: i.e., the count returned is within a $(1+\varepsilon)$-factor of the exact count with confidence at least $1-\delta$. While hashing-based techniques attain reasonable scalability for large enough values of $\delta$, their scalability is severely impacted for smaller values of $\delta$, thereby preventing their adoption in application domains that require estimates with high confidence. The primary contribution of this paper is to address the Achilles heel of hashing-based techniques: we propose a novel approach based on rounding that allows us to achieve a significant reduction in runtime for smaller values of $\delta$. The resulting counter, called RoundMC, achieves a substantial runtime performance improvement over the current state-of-the-art counter, ApproxMC. In particular, our extensive evaluation over a benchmark suite consisting of 1890 instances shows that RoundMC solves 204 more instances than ApproxMC, and achieves a $4\times$ speedup over ApproxMC.
Data-based Polymer-Unit Fingerprint : A Newly Accessible Expression of Polymer Organic Semiconductors for Machine Learning
Nov 03, 2022



In the process of finding high-performance organic semiconductors (OSCs), it is of paramount importance in material development to identify important functional units that play key roles in material performance and subsequently establish substructure-property relationships. Herein, we describe a polymer-unit fingerprint (PUFp) generation framework. Machine learning (ML) models can be used to determine structure-mobility relationships by using PUFp information as structural input with 678 pieces of collected OSC data. A polymer-unit library consisting of 445 units is constructed, and the key polymer units for the mobility of OSCs are identified. By investigating the combinations of polymer units with mobility performance, a scheme for designing polymer OSC materials by combining ML approaches and PUFp information is proposed to not only passively predict OSC mobility but also actively provide structural guidance for new high-mobility OSC material design. The proposed scheme demonstrates the ability to screen new materials through pre-evaluation and classification ML steps and is an alternative methodology for applying ML in new high-mobility OSC discovery.
Projected Model Counting: Beyond Independent Support
Oct 18, 2021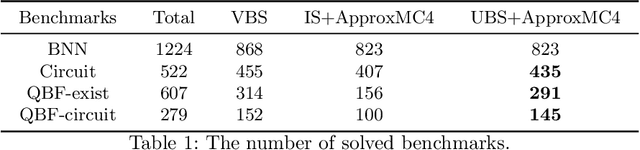

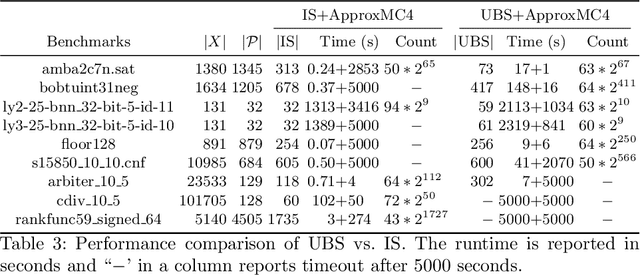
The past decade has witnessed a surge of interest in practical techniques for projected model counting. Despite significant advancements, however, performance scaling remains the Achilles' heel of this field. A key idea used in modern counters is to count models projected on an \emph{independent support} that is often a small subset of the projection set, i.e. original set of variables on which we wanted to project. While this idea has been effective in scaling performance, the question of whether it can benefit to count models projected on variables beyond the projection set, has not been explored. In this paper, we study this question and show that contrary to intuition, it can be beneficial to project on variables beyond the projection set. In applications such as verification of binarized neural networks, quantification of information flow, reliability of power grids etc., a good upper bound of the projected model count often suffices. We show that in several such cases, we can identify a set of variables, called upper bound support (UBS), that is not necessarily a subset of the projection set, and yet counting models projected on UBS guarantees an upper bound of the true projected model count. Theoretically, a UBS can be exponentially smaller than the smallest independent support. Our experiments show that even otherwise, UBS-based projected counting can be more efficient than independent support-based projected counting, while yielding bounds of very high quality. Based on extensive experiments, we find that UBS-based projected counting can solve many problem instances that are beyond the reach of a state-of-the-art independent support-based projected model counter.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Dec 14, 2018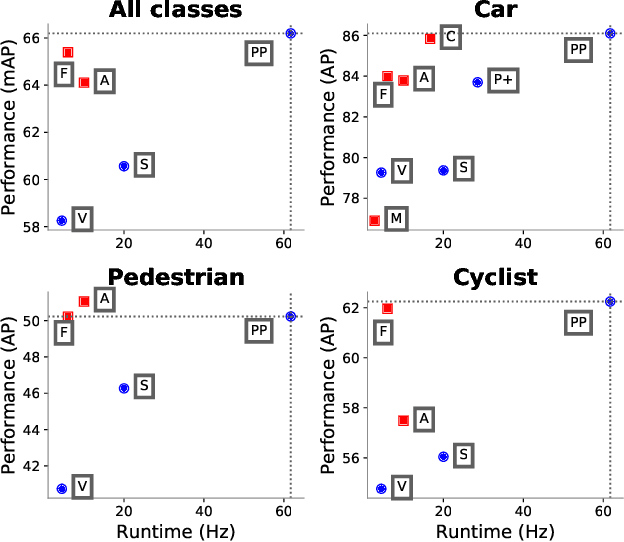

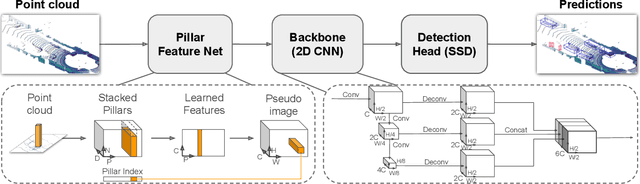

Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.