 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Boltzmann Machines
May 15, 2023Conditional generative models are capable of using contextual information as input to create new imaginative outputs. Conditional Restricted Boltzmann Machines (CRBMs) are one class of conditional generative models that have proven to be especially adept at modeling noisy discrete or continuous data, but the lack of expressivity in CRBMs have limited their widespread adoption. Here we introduce Neural Boltzmann Machines (NBMs) which generalize CRBMs by converting each of the CRBM parameters to their own neural networks that are allowed to be functions of the conditional inputs. NBMs are highly flexible conditional generative models that can be trained via stochastic gradient descent to approximately maximize the log-likelihood of the data. We demonstrate the utility of NBMs especially with normally distributed data which has historically caused problems for Gaussian-Bernoulli CRBMs. Code to reproduce our results can be found at https://github.com/unlearnai/neural-boltzmann-machines.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019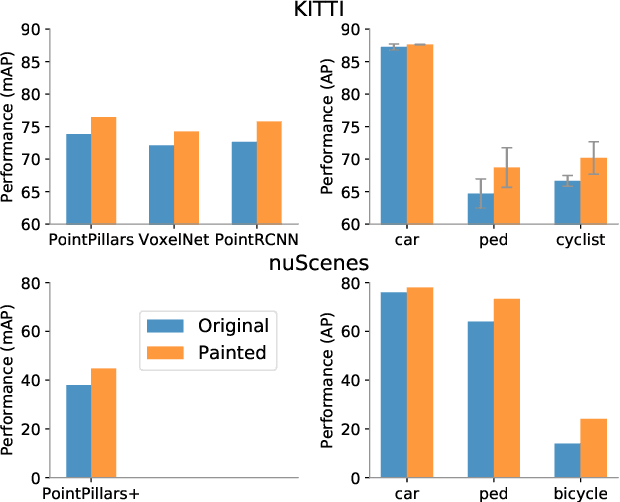
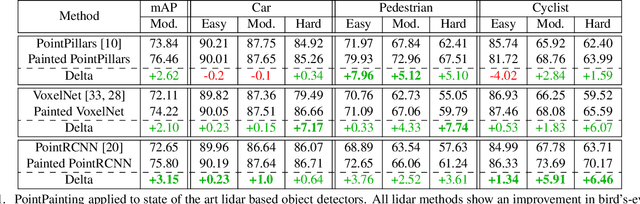
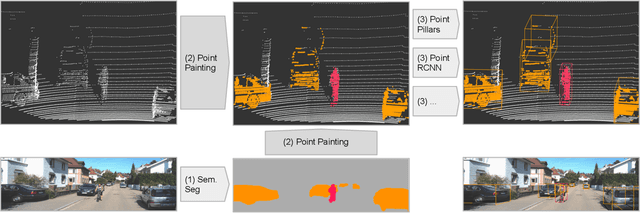
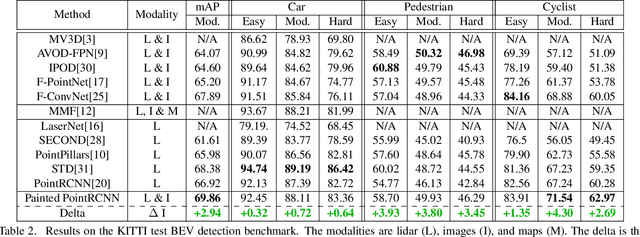
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
nuScenes: A multimodal dataset for autonomous driving
Mar 26, 2019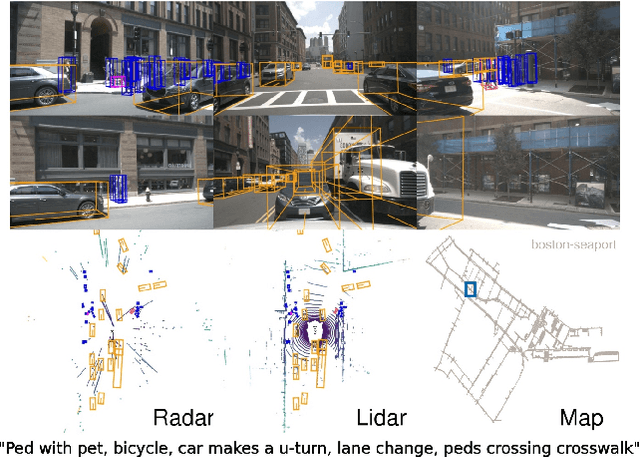
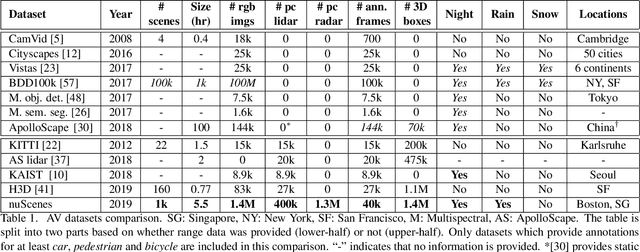


Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image-based benchmark datasets have driven the development in computer vision tasks such as object detection, tracking and segmentation of agents in the environment. Most autonomous vehicles, however, carry a combination of cameras and range sensors such as lidar and radar. As machine learning based methods for detection and tracking become more prevalent, there is a need to train and evaluate such methods on datasets containing range sensor data along with images. In this work we present nuTonomy scenes (nuScenes), the first dataset to carry the full autonomous vehicle sensor suite: 6 cameras, 5 radars and 1 lidar, all with full 360 degree field of view. nuScenes comprises 1000 scenes, each 20s long and fully annotated with 3D bounding boxes for 23 classes and 8 attributes. It has 7x as many annotations and 100x as many images as the pioneering KITTI dataset. We also define a new metric for 3D detection which consolidates the multiple aspects of the detection task: classification, localization, size, orientation, velocity and attribute estimation. We provide careful dataset analysis as well as baseline performance for lidar and image based detection methods. Data, development kit, and more information are available at www.nuscenes.org.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Dec 14, 2018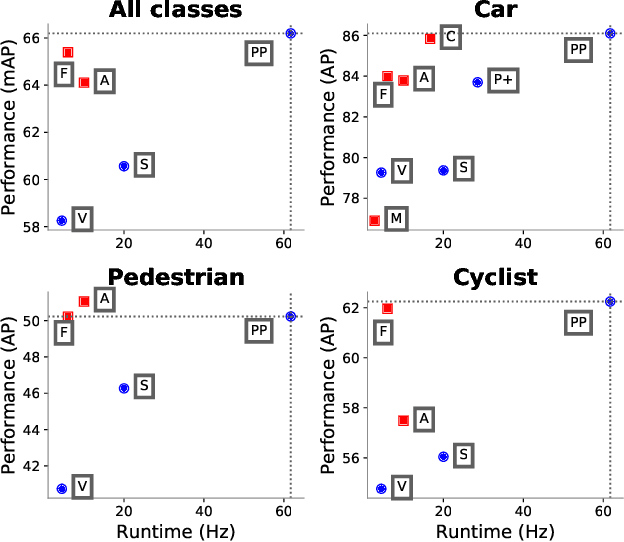

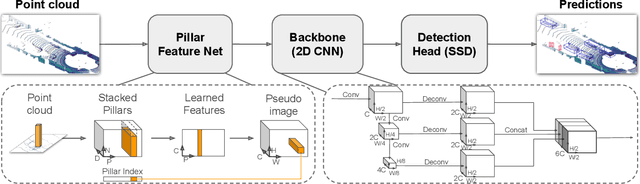

Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.