 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Reasonable Crowd: Towards evidence-based and interpretable models of driving behavior
Jul 28, 2021
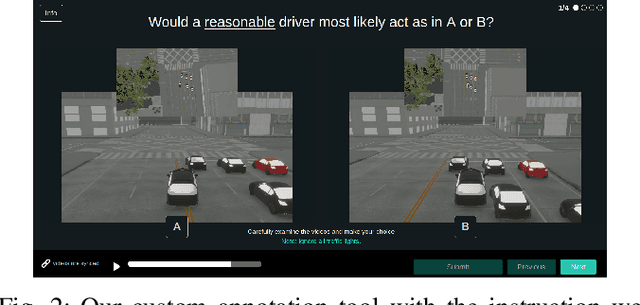

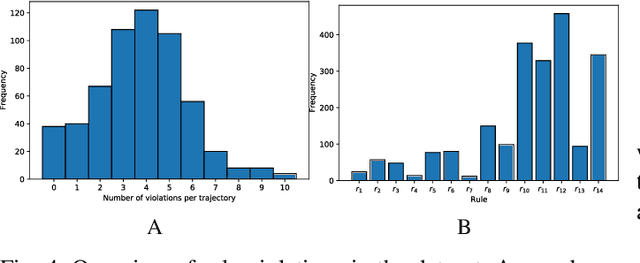
Autonomous vehicles must balance a complex set of objectives. There is no consensus on how they should do so, nor on a model for specifying a desired driving behavior. We created a dataset to help address some of these questions in a limited operating domain. The data consists of 92 traffic scenarios, with multiple ways of traversing each scenario. Multiple annotators expressed their preference between pairs of scenario traversals. We used the data to compare an instance of a rulebook, carefully hand-crafted independently of the dataset, with several interpretable machine learning models such as Bayesian networks, decision trees, and logistic regression trained on the dataset. To compare driving behavior, these models use scores indicating by how much different scenario traversals violate each of 14 driving rules. The rules are interpretable and designed by subject-matter experts. First, we found that these rules were enough for these models to achieve a high classification accuracy on the dataset. Second, we found that the rulebook provides high interpretability without excessively sacrificing performance. Third, the data pointed to possible improvements in the rulebook and the rules, and to potential new rules. Fourth, we explored the interpretability vs performance trade-off by also training non-interpretable models such as a random forest. Finally, we make the dataset publicly available to encourage a discussion from the wider community on behavior specification for AVs. Please find it at github.com/bassam-motional/Reasonable-Crowd.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019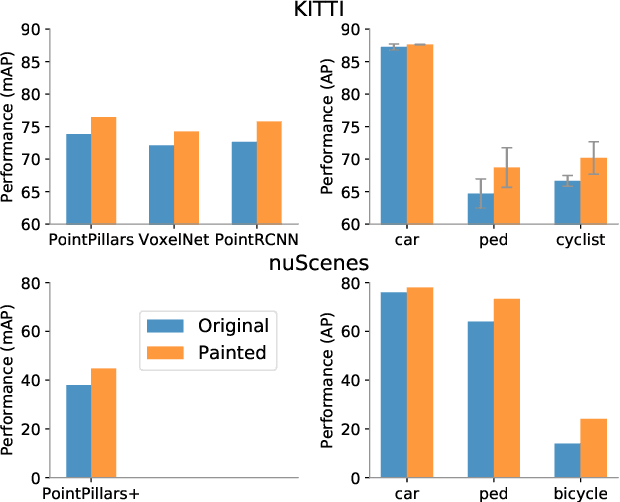
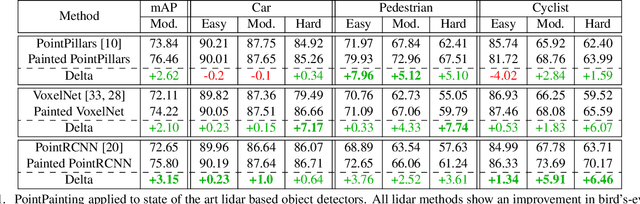
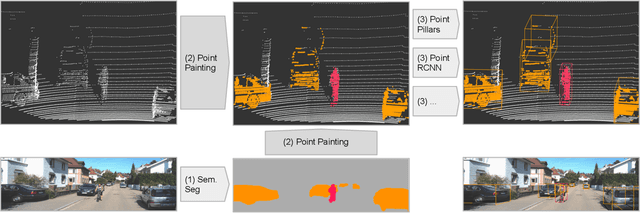
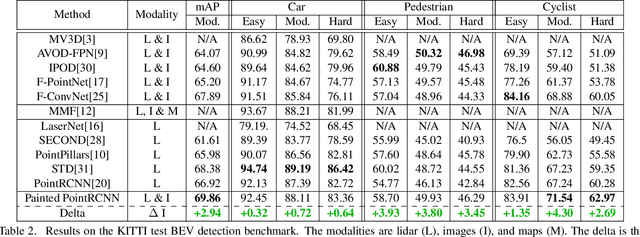
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.