 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposal-free Lidar Panoptic Segmentation with Pillar-level Affinity
Apr 19, 2022


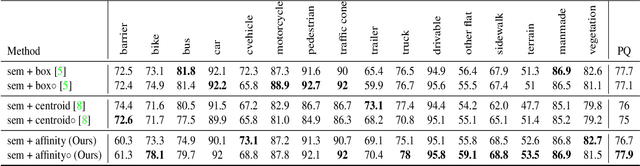
We propose a simple yet effective proposal-free architecture for lidar panoptic segmentation. We jointly optimize both semantic segmentation and class-agnostic instance classification in a single network using a pillar-based bird's-eye view representation. The instance classification head learns pairwise affinity between pillars to determine whether the pillars belong to the same instance or not. We further propose a local clustering algorithm to propagate instance ids by merging semantic segmentation and affinity predictions. Our experiments on nuScenes dataset show that our approach outperforms previous proposal-free methods and is comparable to proposal-based methods which requires extra annotation from object detection.
PolarStream: Streaming Lidar Object Detection and Segmentation with Polar Pillars
Jun 14, 2021
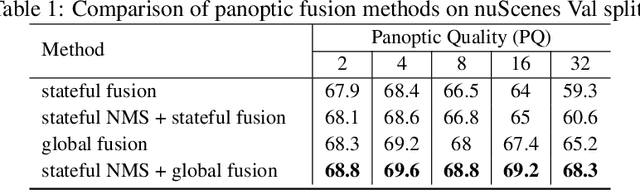

Recent works recognized lidars as an inherently streaming data source and showed that the end-to-end latency of lidar perception models can be reduced significantly by operating on wedge-shaped point cloud sectors rather then the full point cloud. However, due to use of cartesian coordinate systems these methods represent the sectors as rectangular regions, wasting memory and compute. In this work we propose using a polar coordinate system and make two key improvements on this design. First, we increase the spatial context by using multi-scale padding from neighboring sectors: preceding sector from the current scan and/or the following sector from the past scan. Second, we improve the core polar convolutional architecture by introducing feature undistortion and range stratified convolutions. Experimental results on the nuScenes dataset show significant improvements over other streaming based methods. We also achieve comparable results to existing non-streaming methods but with lower latencies.
PointPainting: Sequential Fusion for 3D Object Detection
Nov 22, 2019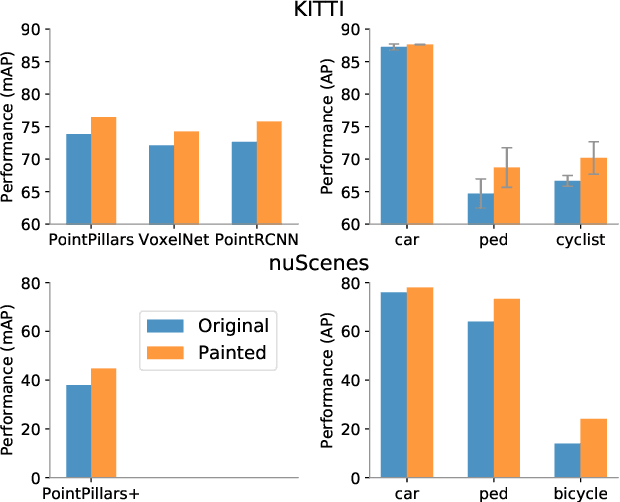
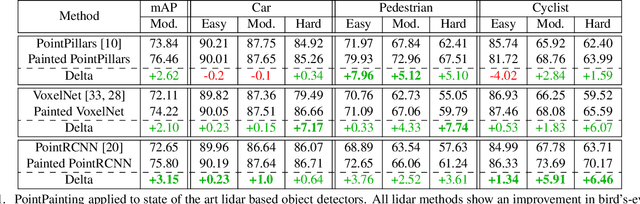
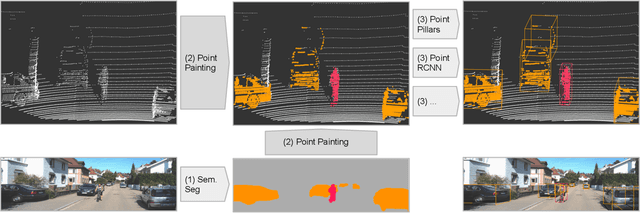
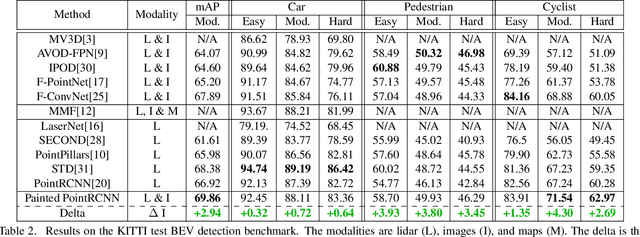
Camera and lidar are important sensor modalities for robotics in general and self-driving cars in particular. The sensors provide complementary information offering an opportunity for tight sensor-fusion. Surprisingly, lidar-only methods outperform fusion methods on the main benchmark datasets, suggesting a gap in the literature. In this work, we propose PointPainting: a sequential fusion method to fill this gap. PointPainting works by projecting lidar points into the output of an image-only semantic segmentation network and appending the class scores to each point. The appended (painted) point cloud can then be fed to any lidar-only method. Experiments show large improvements on three different state-of-the art methods, Point-RCNN, VoxelNet and PointPillars on the KITTI and nuScenes datasets. The painted version of PointRCNN represents a new state of the art on the KITTI leaderboard for the bird's-eye view detection task. In ablation, we study how the effects of Painting depends on the quality and format of the semantic segmentation output, and demonstrate how latency can be minimized through pipelining.
nuScenes: A multimodal dataset for autonomous driving
Mar 26, 2019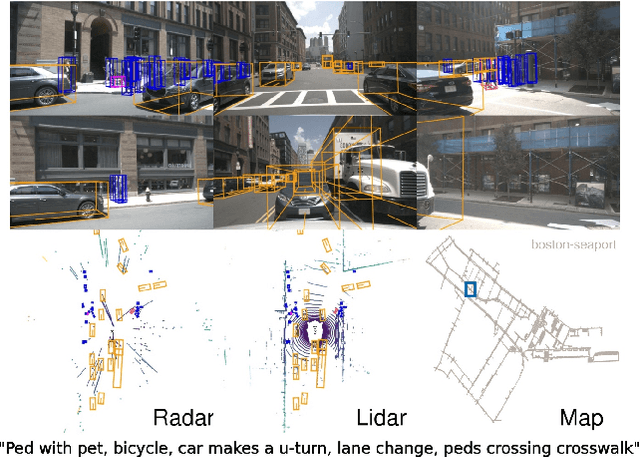
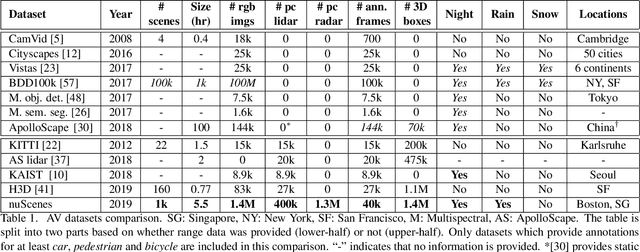


Robust detection and tracking of objects is crucial for the deployment of autonomous vehicle technology. Image-based benchmark datasets have driven the development in computer vision tasks such as object detection, tracking and segmentation of agents in the environment. Most autonomous vehicles, however, carry a combination of cameras and range sensors such as lidar and radar. As machine learning based methods for detection and tracking become more prevalent, there is a need to train and evaluate such methods on datasets containing range sensor data along with images. In this work we present nuTonomy scenes (nuScenes), the first dataset to carry the full autonomous vehicle sensor suite: 6 cameras, 5 radars and 1 lidar, all with full 360 degree field of view. nuScenes comprises 1000 scenes, each 20s long and fully annotated with 3D bounding boxes for 23 classes and 8 attributes. It has 7x as many annotations and 100x as many images as the pioneering KITTI dataset. We also define a new metric for 3D detection which consolidates the multiple aspects of the detection task: classification, localization, size, orientation, velocity and attribute estimation. We provide careful dataset analysis as well as baseline performance for lidar and image based detection methods. Data, development kit, and more information are available at www.nuscenes.org.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Dec 14, 2018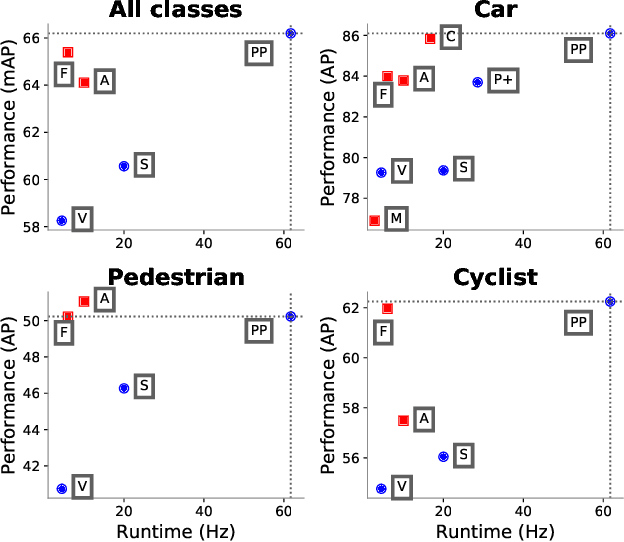

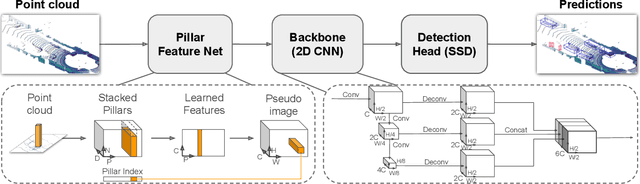

Object detection in point clouds is an important aspect of many robotics applications such as autonomous driving. In this paper we consider the problem of encoding a point cloud into a format appropriate for a downstream detection pipeline. Recent literature suggests two types of encoders; fixed encoders tend to be fast but sacrifice accuracy, while encoders that are learned from data are more accurate, but slower. In this work we propose PointPillars, a novel encoder which utilizes PointNets to learn a representation of point clouds organized in vertical columns (pillars). While the encoded features can be used with any standard 2D convolutional detection architecture, we further propose a lean downstream network. Extensive experimentation shows that PointPillars outperforms previous encoders with respect to both speed and accuracy by a large margin. Despite only using lidar, our full detection pipeline significantly outperforms the state of the art, even among fusion methods, with respect to both the 3D and bird's eye view KITTI benchmarks. This detection performance is achieved while running at 62 Hz: a 2 - 4 fold runtime improvement. A faster version of our method matches the state of the art at 105 Hz. These benchmarks suggest that PointPillars is an appropriate encoding for object detection in point clouds.
Driver Gaze Zone Estimation using Convolutional Neural Networks: A General Framework and Ablative Analysis
Apr 25, 2018
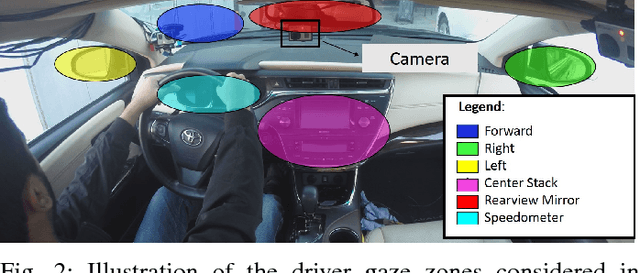
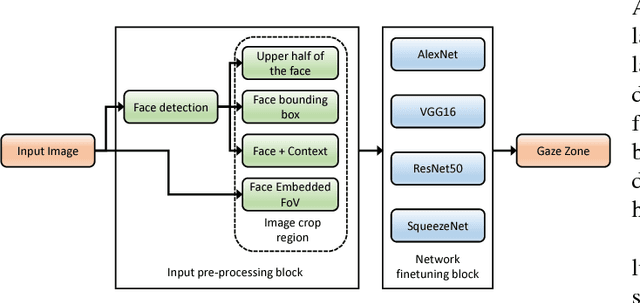

Driver gaze has been shown to be an excellent surrogate for driver attention in intelligent vehicles. With the recent surge of highly autonomous vehicles, driver gaze can be useful for determining the handoff time to a human driver. While there has been significant improvement in personalized driver gaze zone estimation systems, a generalized system which is invariant to different subjects, perspectives and scales is still lacking. We take a step towards this generalized system using Convolutional Neural Networks (CNNs). We finetune 4 popular CNN architectures for this task, and provide extensive comparisons of their outputs. We additionally experiment with different input image patches, and also examine how image size affects performance. For training and testing the networks, we collect a large naturalistic driving dataset comprising of 11 long drives, driven by 10 subjects in two different cars. Our best performing model achieves an accuracy of 95.18% during cross-subject testing, outperforming current state of the art techniques for this task. Finally, we evaluate our best performing model on the publicly available Columbia Gaze Dataset comprising of images from 56 subjects with varying head pose and gaze directions. Without any training, our model successfully encodes the different gaze directions on this diverse dataset, demonstrating good generalization capabilities.
Dynamics of Driver's Gaze: Explorations in Behavior Modeling & Maneuver Prediction
Jan 31, 2018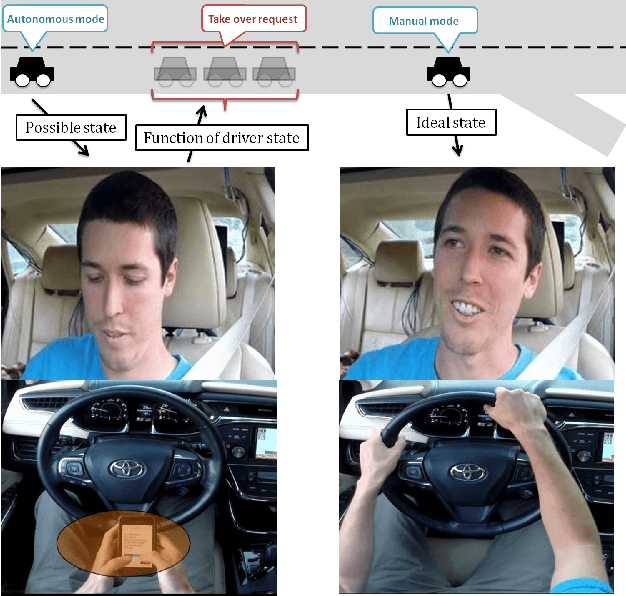
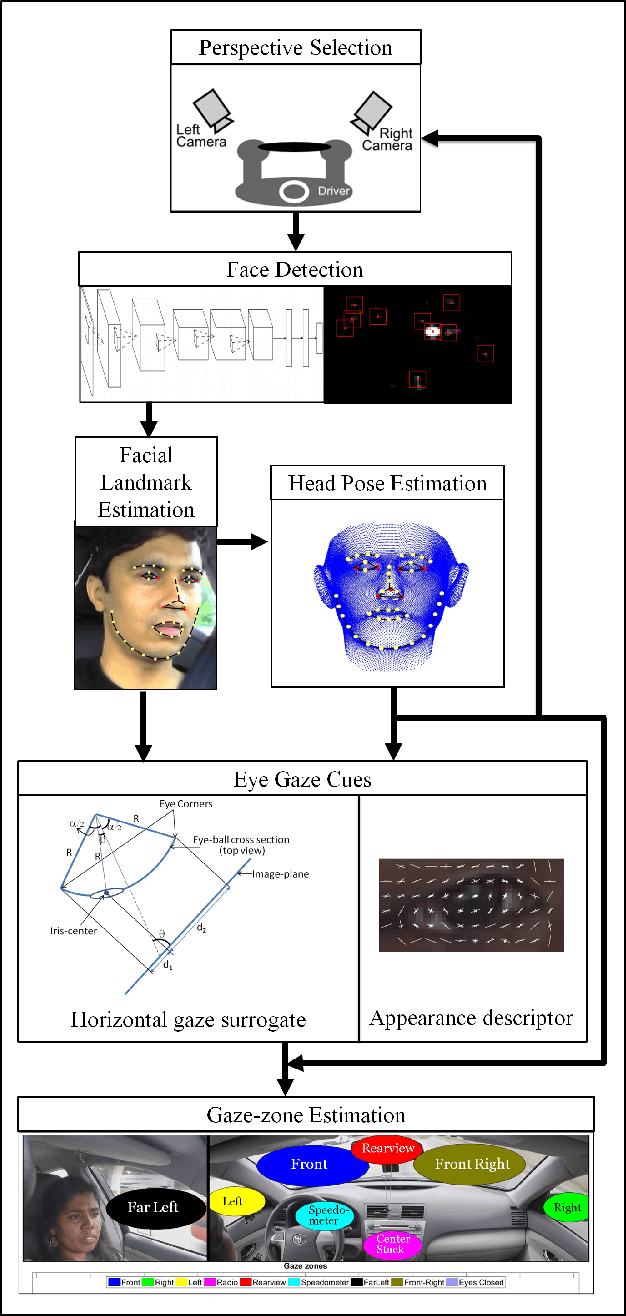
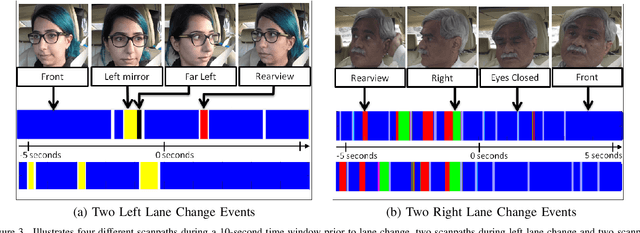
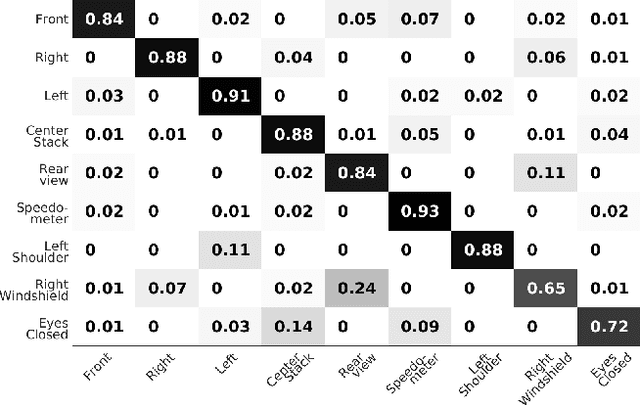
The study and modeling of driver's gaze dynamics is important because, if and how the driver is monitoring the driving environment is vital for driver assistance in manual mode, for take-over requests in highly automated mode and for semantic perception of the surround in fully autonomous mode. We developed a machine vision based framework to classify driver's gaze into context rich zones of interest and model driver's gaze behavior by representing gaze dynamics over a time period using gaze accumulation, glance duration and glance frequencies. As a use case, we explore the driver's gaze dynamic patterns during maneuvers executed in freeway driving, namely, left lane change maneuver, right lane change maneuver and lane keeping. It is shown that condensing gaze dynamics into durations and frequencies leads to recurring patterns based on driver activities. Furthermore, modeling these patterns show predictive powers in maneuver detection up to a few hundred milliseconds a priori.