 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Control Transitions: Machine Vision Based Observable Readiness Index and Data-Driven Takeover Time Prediction
Jan 18, 2023



To make safe transitions from autonomous to manual control, a vehicle must have a representation of the awareness of driver state; two metrics which quantify this state are the Observable Readiness Index and Takeover Time. In this work, we show that machine learning models which predict these two metrics are robust to multiple camera views, expanding from the limited view angles in prior research. Importantly, these models take as input feature vectors corresponding to hand location and activity as well as gaze location, and we explore the tradeoffs of different views in generating these feature vectors. Further, we introduce two metrics to evaluate the quality of control transitions following the takeover event (the maximal lateral deviation and velocity deviation) and compute correlations of these post-takeover metrics to the pre-takeover predictive metrics.
Salient Sign Detection In Safe Autonomous Driving: AI Which Reasons Over Full Visual Context
Jan 18, 2023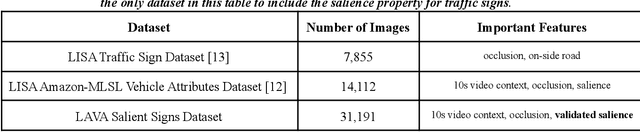



Detecting road traffic signs and accurately determining how they can affect the driver's future actions is a critical task for safe autonomous driving systems. However, various traffic signs in a driving scene have an unequal impact on the driver's decisions, making detecting the salient traffic signs a more important task. Our research addresses this issue, constructing a traffic sign detection model which emphasizes performance on salient signs, or signs that influence the decisions of a driver. We define a traffic sign salience property and use it to construct the LAVA Salient Signs Dataset, the first traffic sign dataset that includes an annotated salience property. Next, we use a custom salience loss function, Salience-Sensitive Focal Loss, to train a Deformable DETR object detection model in order to emphasize stronger performance on salient signs. Results show that a model trained with Salience-Sensitive Focal Loss outperforms a model trained without, with regards to recall of both salient signs and all signs combined. Further, the performance margin on salient signs compared to all signs is largest for the model trained with Salience-Sensitive Focal Loss.
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021
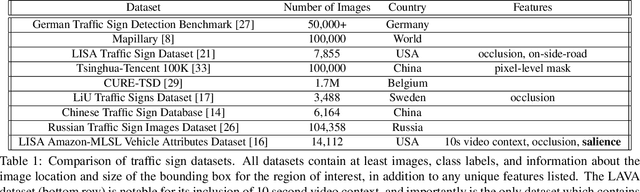

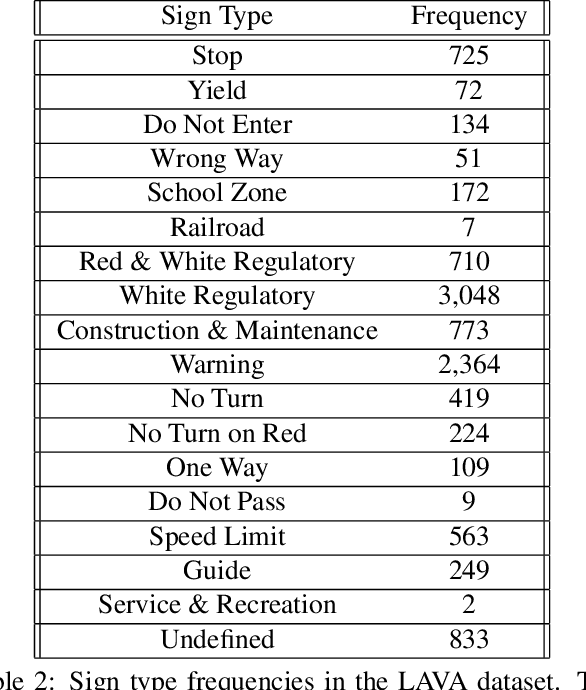
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Predicting Take-over Time for Autonomous Driving with Real-World Data: Robust Data Augmentation, Models, and Evaluation
Jul 27, 2021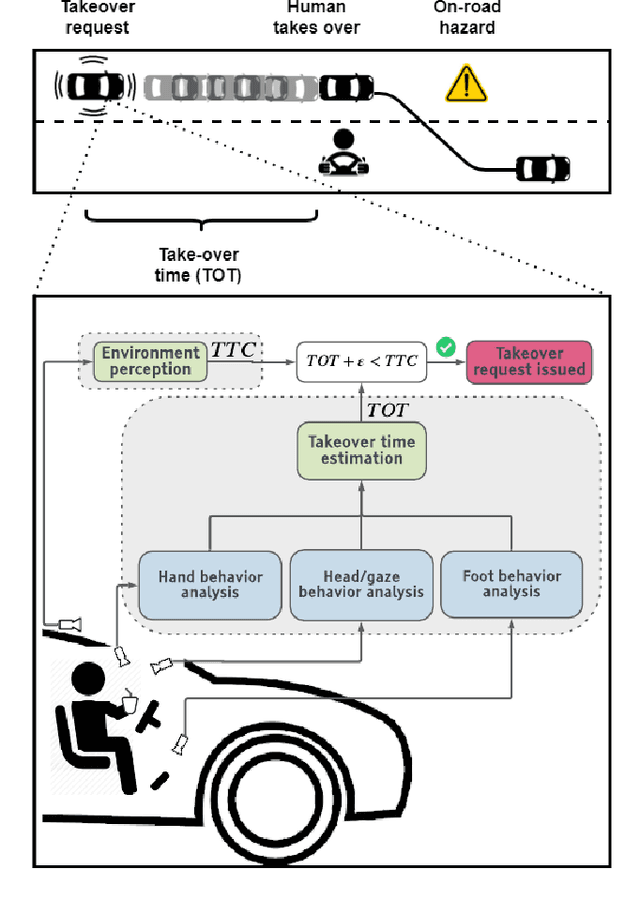

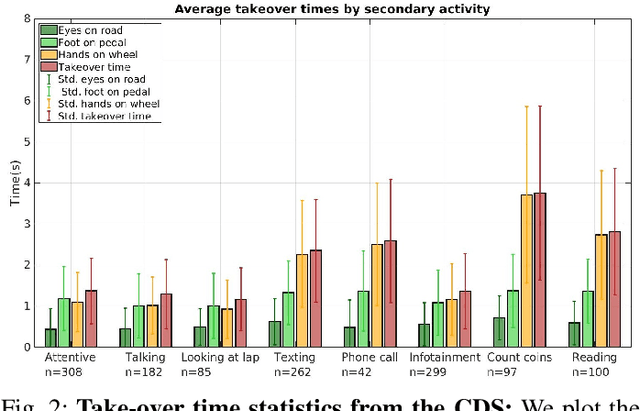
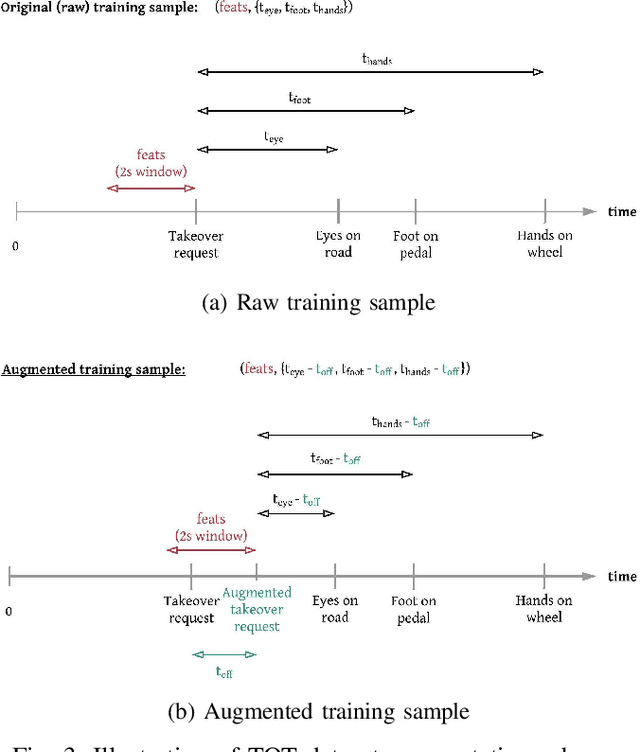
Understanding occupant-vehicle interactions by modeling control transitions is important to ensure safe approaches to passenger vehicle automation. Models which contain contextual, semantically meaningful representations of driver states can be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. However, such models rely on real-world control take-over data from drivers engaged in distracting activities, which is costly to collect. Here, we introduce a scheme for data augmentation for such a dataset. Using the augmented dataset, we develop and train take-over time (TOT) models that operate sequentially on mid and high-level features produced by computer vision algorithms operating on different driver-facing camera views, showing models trained on the augmented dataset to outperform the initial dataset. The demonstrated model features encode different aspects of the driver state, pertaining to the face, hands, foot and upper body of the driver. We perform ablative experiments on feature combinations as well as model architectures, showing that a TOT model supported by augmented data can be used to produce continuous estimates of take-over times without delay, suitable for complex real-world scenarios.
Autonomous Vehicles that Alert Humans to Take-Over Controls: Modeling with Real-World Data
Apr 23, 2021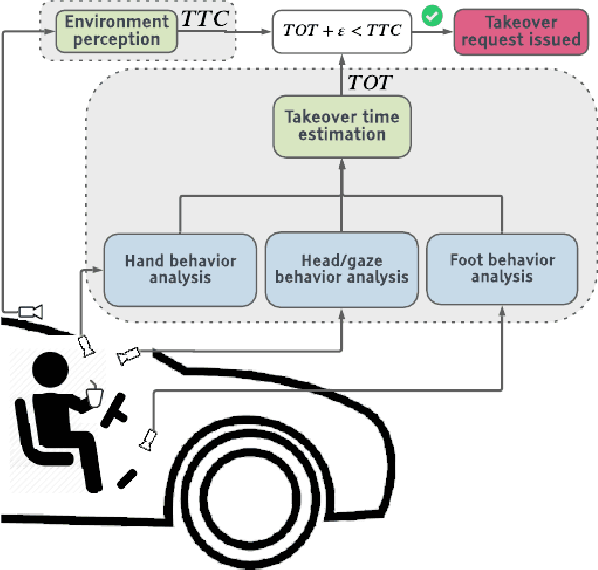
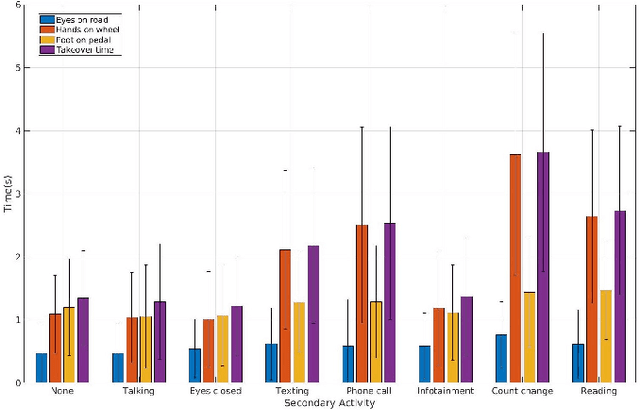
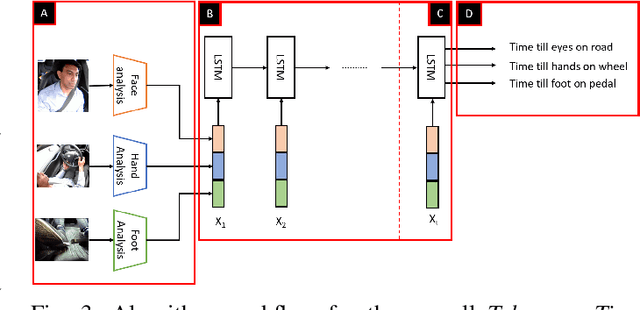
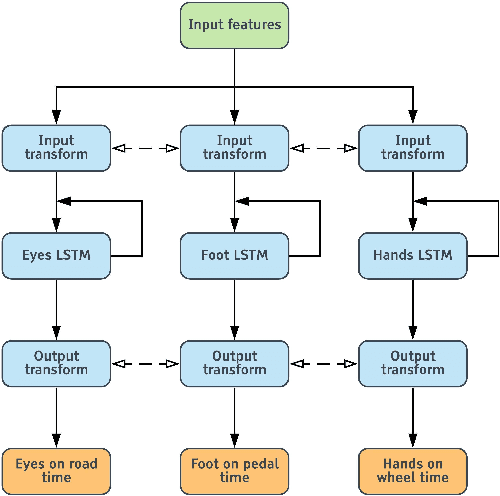
With increasing automation in passenger vehicles, the study of safe and smooth occupant-vehicle interaction and control transitions is key. In this study, we focus on the development of contextual, semantically meaningful representations of the driver state, which can then be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. To this end, we conduct a large-scale real-world controlled data study where participants are instructed to take-over control from an autonomous agent under different driving conditions while engaged in a variety of distracting activities. These take-over events are captured using multiple driver-facing cameras, which when labelled result in a dataset of control transitions and their corresponding take-over times (TOTs). After augmenting this dataset, we develop and train TOT models that operate sequentially on low and mid-level features produced by computer vision algorithms operating on different driver-facing camera views. The proposed TOT model produces continuous estimates of take-over times without delay, and shows promising qualitative and quantitative results in complex real-world scenarios.
LaneAF: Robust Multi-Lane Detection with Affinity Fields
Apr 02, 2021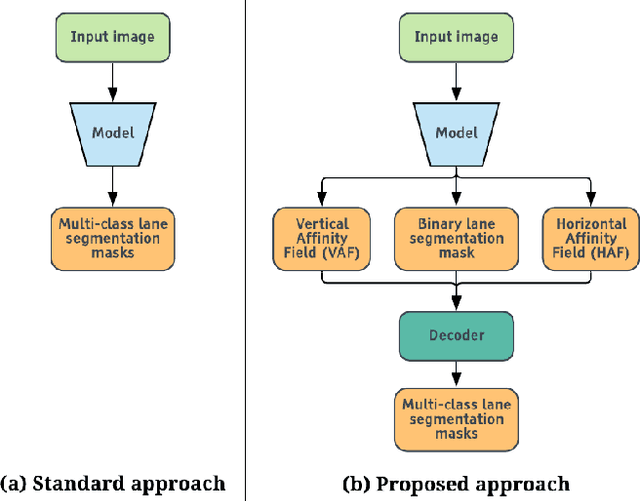

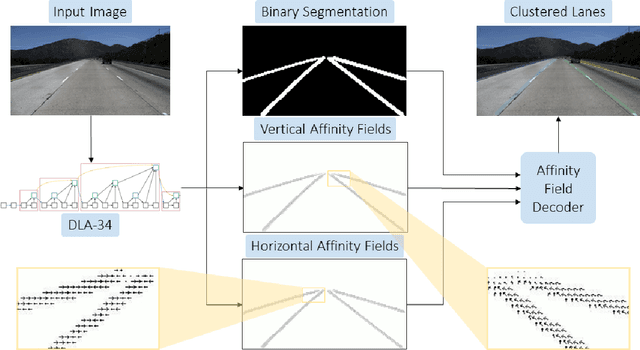
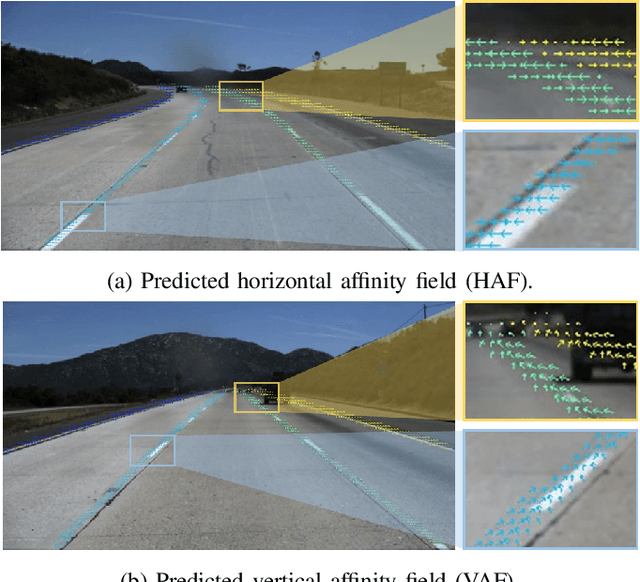
This study presents an approach to lane detection involving the prediction of binary segmentation masks and per-pixel affinity fields. These affinity fields, along with the binary masks, can then be used to cluster lane pixels horizontally and vertically into corresponding lane instances in a post-processing step. This clustering is achieved through a simple row-by-row decoding process with little overhead; such an approach allows LaneAF to detect a variable number of lanes without assuming a fixed or maximum number of lanes. Moreover, this form of clustering is more interpretable in comparison to previous visual clustering approaches, and can be analyzed to identify and correct sources of error. Qualitative and quantitative results obtained on popular lane detection datasets demonstrate the model's ability to detect and cluster lanes effectively and robustly. Our proposed approach performs on par with state-of-the-art approaches on the limited TuSimple benchmark, and sets a new state-of-the-art on the challenging CULane dataset.
TrackMPNN: A Message Passing Graph Neural Architecture for Multi-Object Tracking
Jan 28, 2021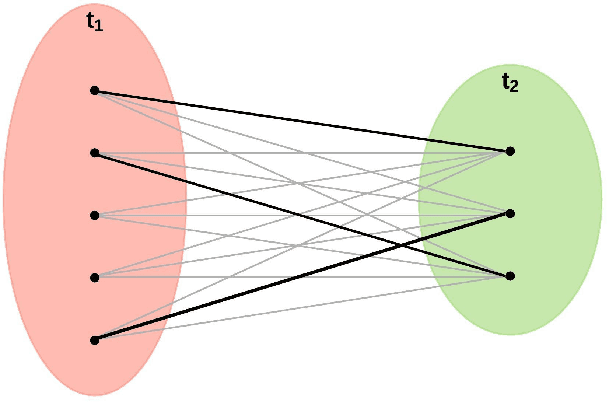
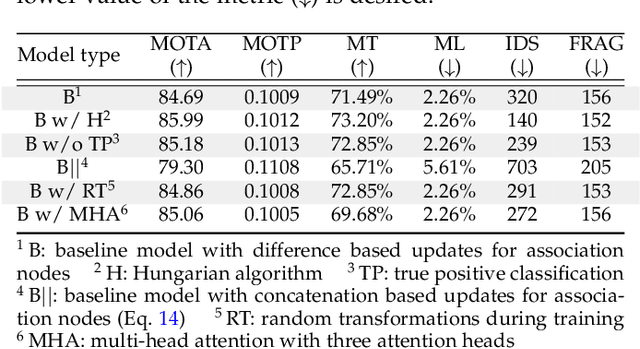
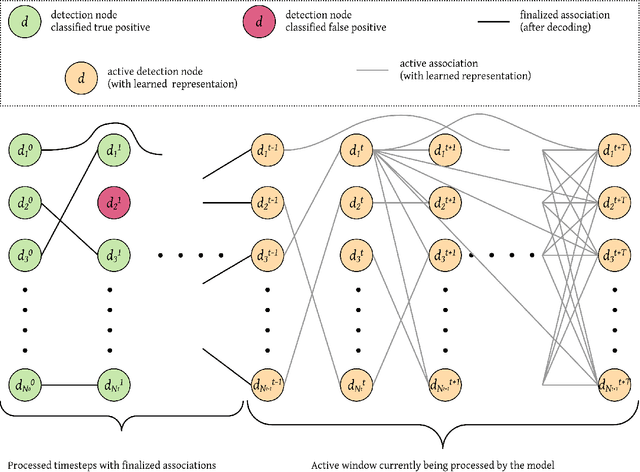
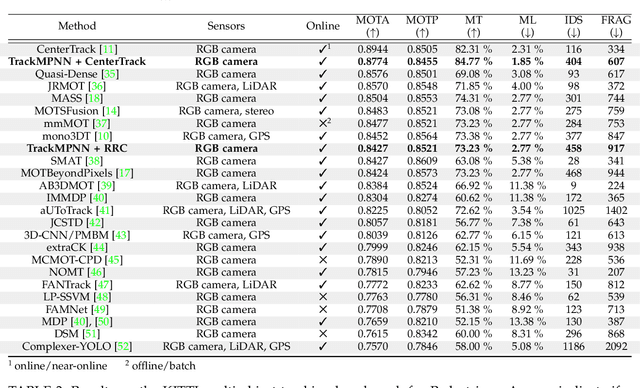
This study follows many previous approaches to multi-object tracking (MOT) that model the problem using graph-based data structures, and adapts this formulation to make it amenable to modern neural networks. Our main contributions in this work are the creation of a framework based on dynamic undirected graphs that represent the data association problem over multiple timesteps, and a message passing graph neural network (GNN) that operates on these graphs to produce the desired likelihood for every association therein. We further provide solutions and propositions for the computational problems that need to be addressed to create a memory-efficient, real-time, online algorithm that can reason over multiple timesteps, correct previous mistakes, update beliefs, possess long-term memory, and handle missed/false detections. In addition to this, our framework provides flexibility in the choice of temporal window sizes to operate on and the losses used for training. In essence, this study provides a framework for any kind of graph based neural network to be trained using conventional techniques from supervised learning, and then use these trained models to infer on new sequences in an online, real-time, computationally tractable manner. To demonstrate the efficacy and robustness of our approach, we only use the 2D box location and object category to construct the descriptor for each object instance. Despite this, our model performs on par with state-of-the-art approaches that make use of multiple hand-crafted and/or learned features. Experiments, qualitative examples and competitive results on popular MOT benchmarks for autonomous driving demonstrate the promise and uniqueness of the proposed approach.
Driver Gaze Estimation in the Real World: Overcoming the Eyeglass Challenge
Feb 11, 2020

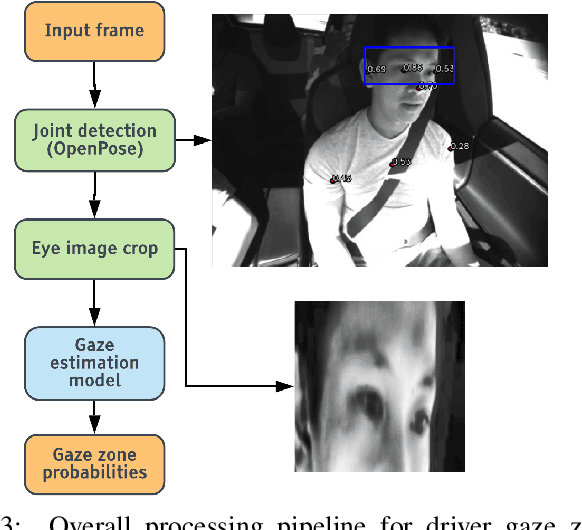
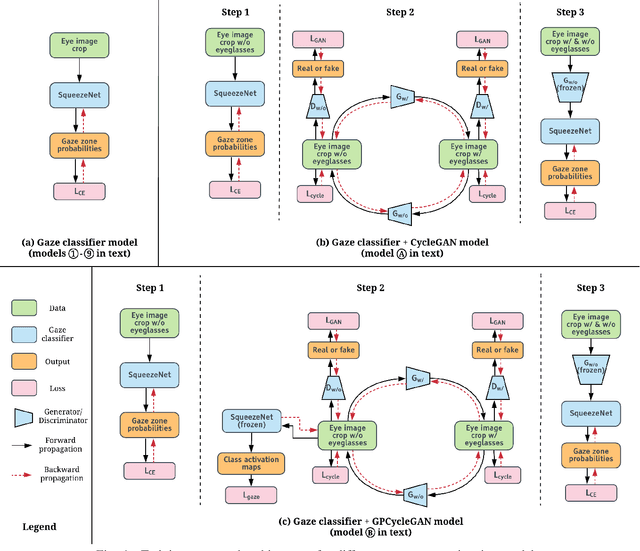
A driver's gaze is critical for determining the driver's attention level, state, situational awareness, and readiness to take over control from partially and fully automated vehicles. Tracking both the head and eyes (pupils) can provide reliable estimation of a driver's gaze using face images under ideal conditions. However, the vehicular environment introduces a variety of challenges that are usually unaccounted for - harsh illumination, nighttime conditions, and reflective/dark eyeglasses. Unfortunately, relying on head pose alone under such conditions can prove to be unreliable owing to significant eye movements. In this study, we offer solutions to address these problems encountered in the real world. To solve issues with lighting, we demonstrate that using an infrared camera with suitable equalization and normalization usually suffices. To handle eyeglasses and their corresponding artifacts, we adopt the idea of image-to-image translation using generative adversarial networks (GANs) to pre-process images prior to gaze estimation. To this end, we propose the Gaze Preserving CycleGAN (GPCycleGAN). As the name suggests, this network preserves the driver's gaze while removing potential eyeglasses from infrared face images. GPCycleGAN is based on the well-known CycleGAN approach, with the addition of a gaze classifier and a gaze consistency loss for additional supervision. Our approach exhibits improved performance and robustness on challenging real-world data spanning 13 subjects and a variety of driving conditions.
Forced Spatial Attention for Driver Foot Activity Classification
Aug 20, 2019
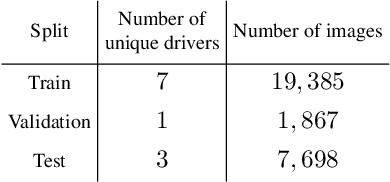


This paper provides a simple solution for reliably solving image classification tasks tied to spatial locations of salient objects in the scene. Unlike conventional image classification approaches that are designed to be invariant to translations of objects in the scene, we focus on tasks where the output classes vary with respect to where an object of interest is situated within an image. To handle this variant of the image classification task, we propose augmenting the standard cross-entropy (classification) loss with a domain dependent Forced Spatial Attention (FSA) loss, which in essence compels the network to attend to specific regions in the image associated with the desired output class. To demonstrate the utility of this loss function, we consider the task of driver foot activity classification - where each activity is strongly correlated with where the driver's foot is in the scene. Training with our proposed loss function results in significantly improved accuracies, better generalization, and robustness against noise, while obviating the need for very large datasets.
3D BAT: A Semi-Automatic, Web-based 3D Annotation Toolbox for Full-Surround, Multi-Modal Data Streams
May 01, 2019



In this paper, we focus on obtaining 2D and 3D labels, as well as track IDs for objects on the road with the help of a novel 3D Bounding Box Annotation Toolbox (3D BAT). Our open source, web-based 3D BAT incorporates several smart features to improve usability and efficiency. For instance, this annotation toolbox supports semi-automatic labeling of tracks using interpolation, which is vital for downstream tasks like tracking, motion planning and motion prediction. Moreover, annotations for all camera images are automatically obtained by projecting annotations from 3D space into the image domain. In addition to the raw image and point cloud feeds, a Masterview consisting of the top view (bird's-eye-view), side view and front views is made available to observe objects of interest from different perspectives. Comparisons of our method with other publicly available annotation tools reveal that 3D annotations can be obtained faster and more efficiently by using our toolbox.