 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveAnno3D -- An Active Learning Framework for Multi-Modal 3D Object Detection
Feb 05, 2024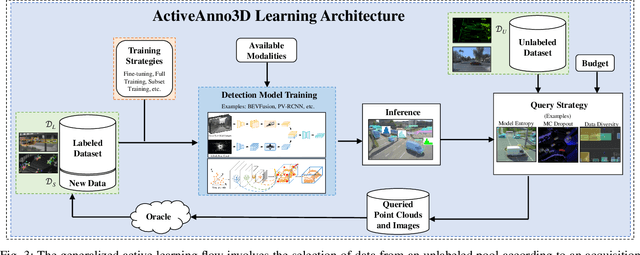
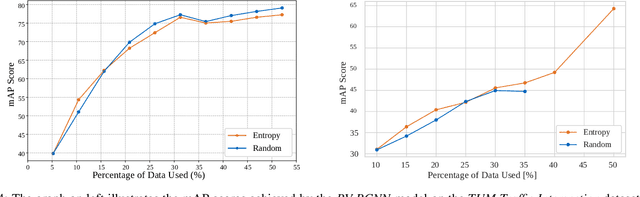
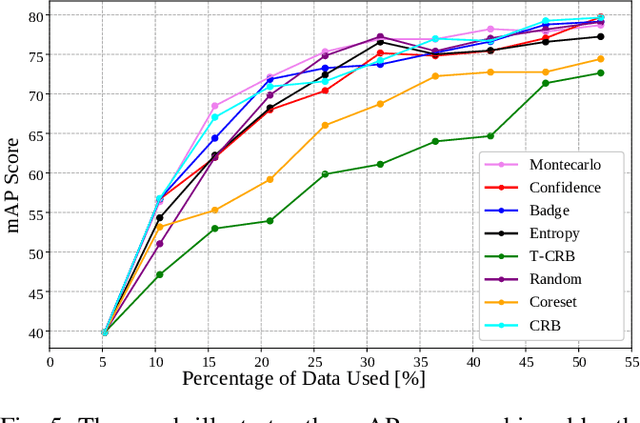

The curation of large-scale datasets is still costly and requires much time and resources. Data is often manually labeled, and the challenge of creating high-quality datasets remains. In this work, we fill the research gap using active learning for multi-modal 3D object detection. We propose ActiveAnno3D, an active learning framework to select data samples for labeling that are of maximum informativeness for training. We explore various continuous training methods and integrate the most efficient method regarding computational demand and detection performance. Furthermore, we perform extensive experiments and ablation studies with BEVFusion and PV-RCNN on the nuScenes and TUM Traffic Intersection dataset. We show that we can achieve almost the same performance with PV-RCNN and the entropy-based query strategy when using only half of the training data (77.25 mAP compared to 83.50 mAP) of the TUM Traffic Intersection dataset. BEVFusion achieved an mAP of 64.31 when using half of the training data and 75.0 mAP when using the complete nuScenes dataset. We integrate our active learning framework into the proAnno labeling tool to enable AI-assisted data selection and labeling and minimize the labeling costs. Finally, we provide code, weights, and visualization results on our website: https://active3d-framework.github.io/active3d-framework.
The Why, When, and How to Use Active Learning in Large-Data-Driven 3D Object Detection for Safe Autonomous Driving: An Empirical Exploration
Jan 30, 2024Active learning strategies for 3D object detection in autonomous driving datasets may help to address challenges of data imbalance, redundancy, and high-dimensional data. We demonstrate the effectiveness of entropy querying to select informative samples, aiming to reduce annotation costs and improve model performance. We experiment using the BEVFusion model for 3D object detection on the nuScenes dataset, comparing active learning to random sampling and demonstrating that entropy querying outperforms in most cases. The method is particularly effective in reducing the performance gap between majority and minority classes. Class-specific analysis reveals efficient allocation of annotated resources for limited data budgets, emphasizing the importance of selecting diverse and informative data for model training. Our findings suggest that entropy querying is a promising strategy for selecting data that enhances model learning in resource-constrained environments.
Vision-based Analysis of Driver Activity and Driving Performance Under the Influence of Alcohol
Sep 14, 2023

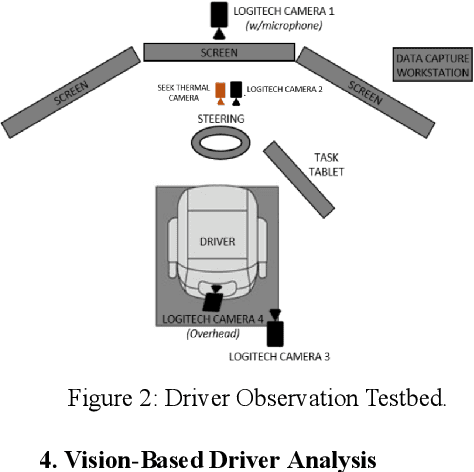
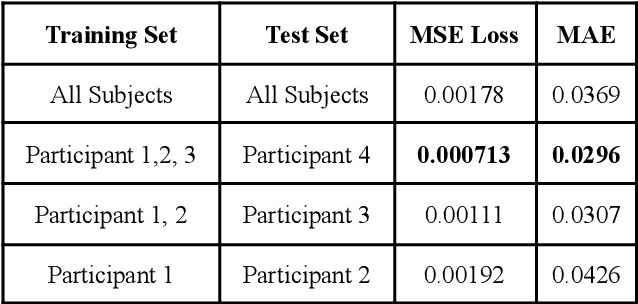
About 30% of all traffic crash fatalities in the United States involve drunk drivers, making the prevention of drunk driving paramount to vehicle safety in the US and other locations which have a high prevalence of driving while under the influence of alcohol. Driving impairment can be monitored through active use of sensors (when drivers are asked to engage in providing breath samples to a vehicle instrument or when pulled over by a police officer), but a more passive and robust mechanism of sensing may allow for wider adoption and benefit of intelligent systems that reduce drunk driving accidents. This could assist in identifying impaired drivers before they drive, or early in the driving process (before a crash or detection by law enforcement). In this research, we introduce a study which adopts a multi-modal ensemble of visual, thermal, audio, and chemical sensors to (1) examine the impact of acute alcohol administration on driving performance in a driving simulator, and (2) identify data-driven methods for detecting driving under the influence of alcohol. We describe computer vision and machine learning models for analyzing the driver's face in thermal imagery, and introduce a pipeline for training models on data collected from drivers with a range of breath-alcohol content levels, including discussion of relevant machine learning phenomena which can help in future experiment design for related studies.
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021
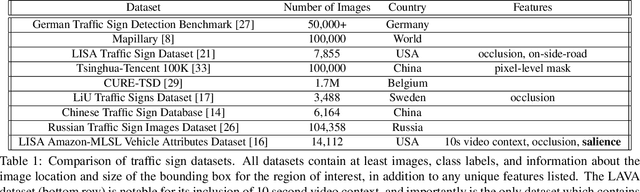

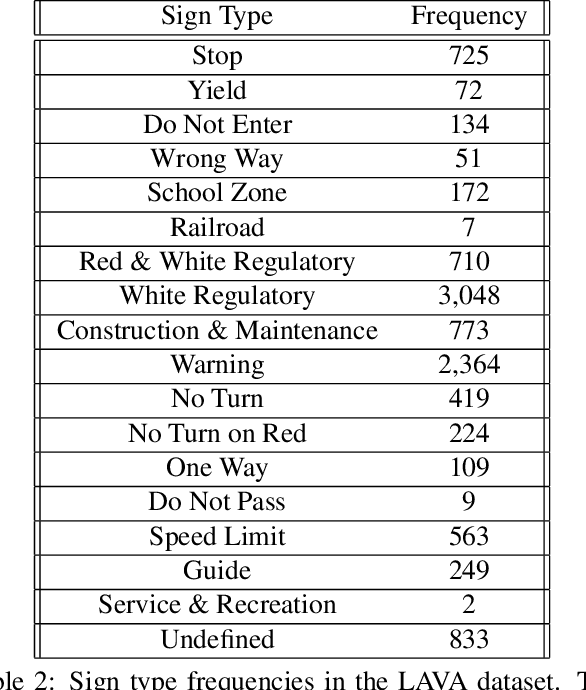
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Predicting Take-over Time for Autonomous Driving with Real-World Data: Robust Data Augmentation, Models, and Evaluation
Jul 27, 2021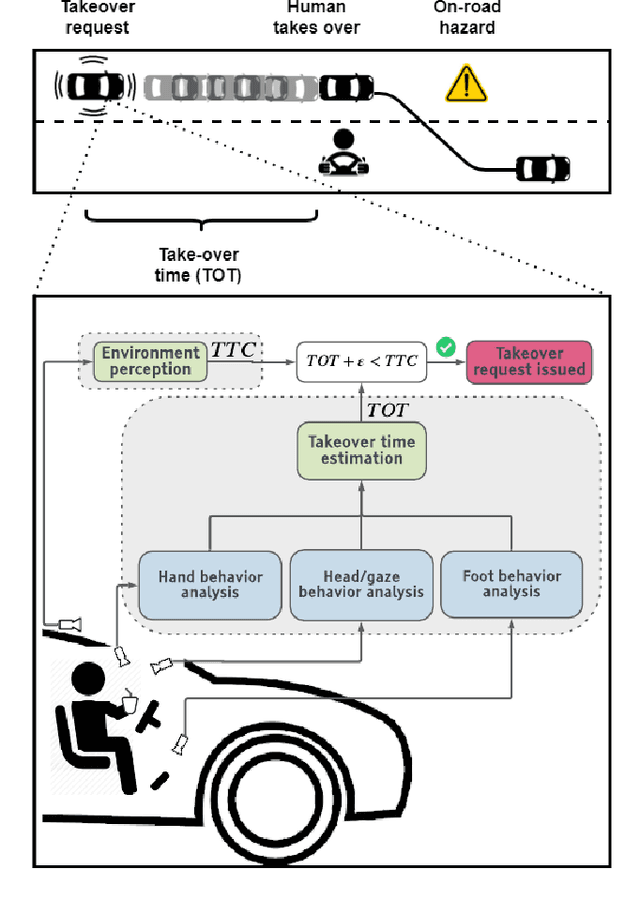

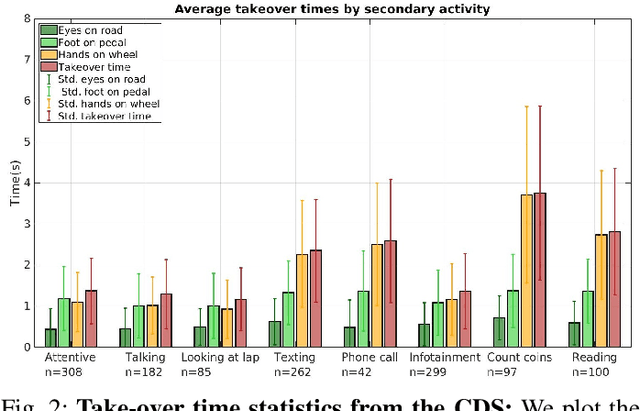
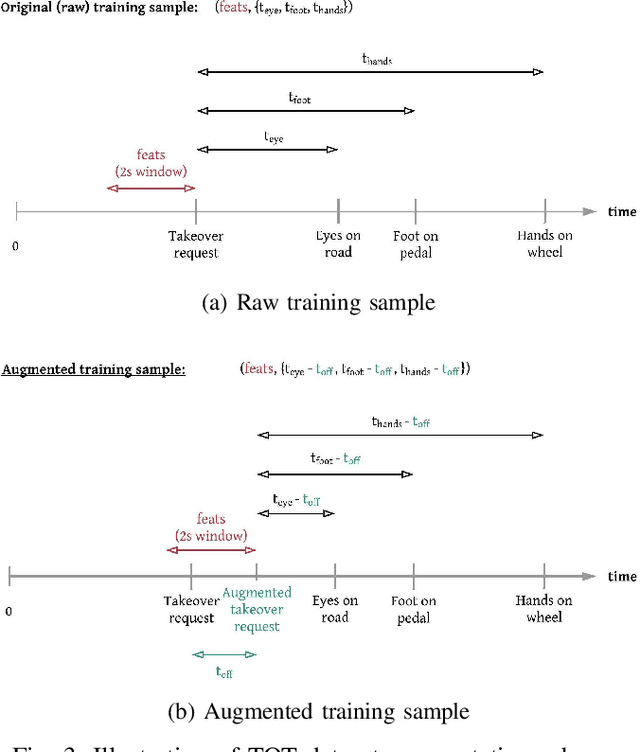
Understanding occupant-vehicle interactions by modeling control transitions is important to ensure safe approaches to passenger vehicle automation. Models which contain contextual, semantically meaningful representations of driver states can be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. However, such models rely on real-world control take-over data from drivers engaged in distracting activities, which is costly to collect. Here, we introduce a scheme for data augmentation for such a dataset. Using the augmented dataset, we develop and train take-over time (TOT) models that operate sequentially on mid and high-level features produced by computer vision algorithms operating on different driver-facing camera views, showing models trained on the augmented dataset to outperform the initial dataset. The demonstrated model features encode different aspects of the driver state, pertaining to the face, hands, foot and upper body of the driver. We perform ablative experiments on feature combinations as well as model architectures, showing that a TOT model supported by augmented data can be used to produce continuous estimates of take-over times without delay, suitable for complex real-world scenarios.
Autonomous Vehicles that Alert Humans to Take-Over Controls: Modeling with Real-World Data
Apr 23, 2021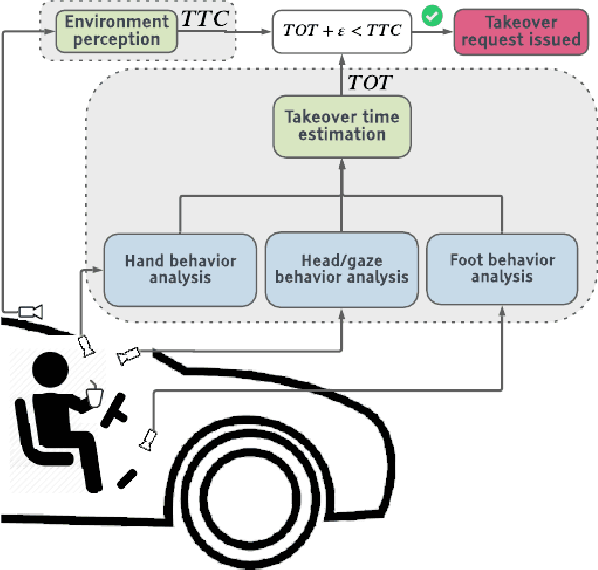
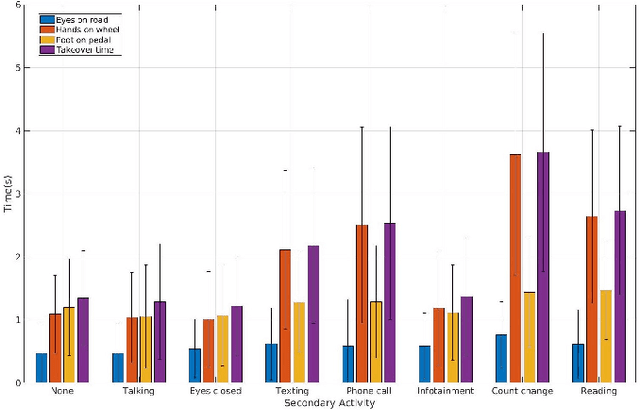
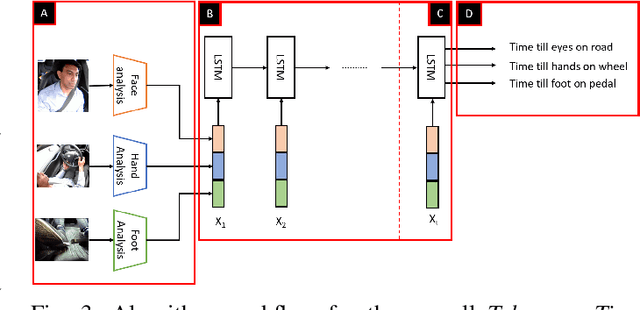
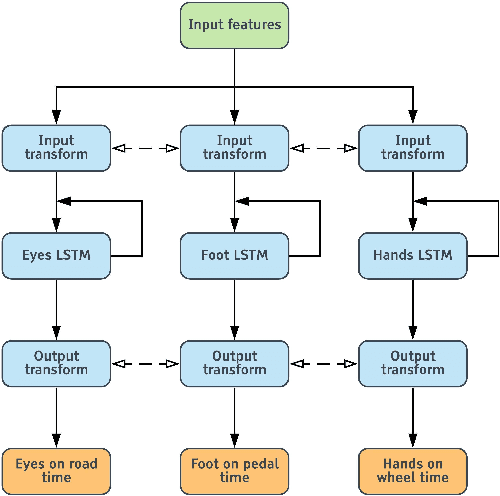
With increasing automation in passenger vehicles, the study of safe and smooth occupant-vehicle interaction and control transitions is key. In this study, we focus on the development of contextual, semantically meaningful representations of the driver state, which can then be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. To this end, we conduct a large-scale real-world controlled data study where participants are instructed to take-over control from an autonomous agent under different driving conditions while engaged in a variety of distracting activities. These take-over events are captured using multiple driver-facing cameras, which when labelled result in a dataset of control transitions and their corresponding take-over times (TOTs). After augmenting this dataset, we develop and train TOT models that operate sequentially on low and mid-level features produced by computer vision algorithms operating on different driver-facing camera views. The proposed TOT model produces continuous estimates of take-over times without delay, and shows promising qualitative and quantitative results in complex real-world scenarios.
LaneAF: Robust Multi-Lane Detection with Affinity Fields
Apr 02, 2021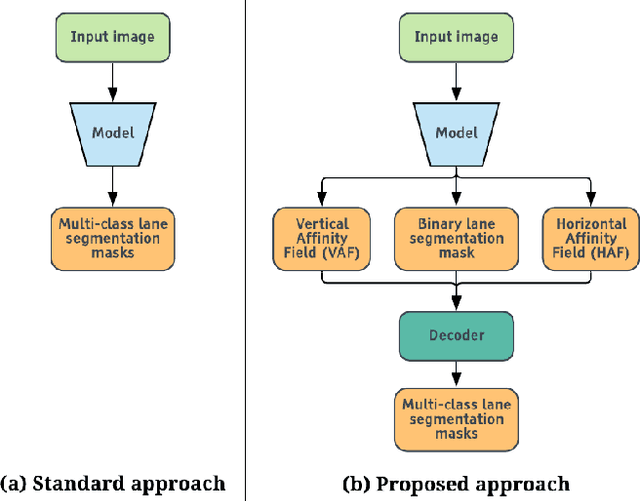

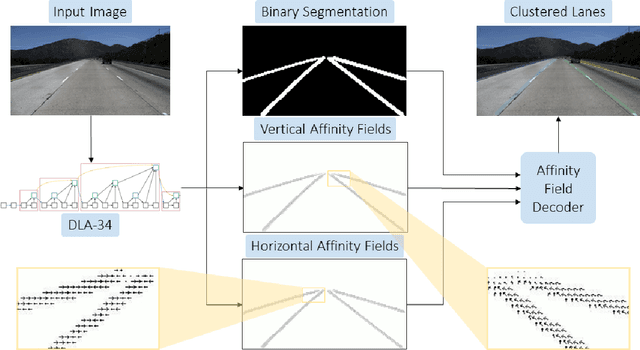
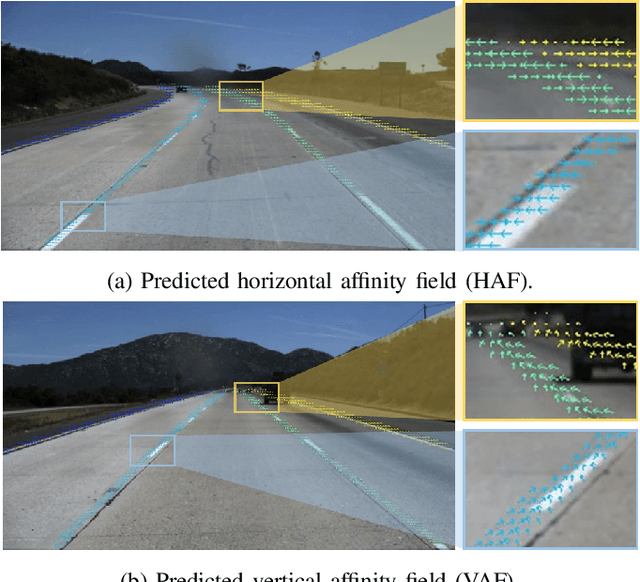
This study presents an approach to lane detection involving the prediction of binary segmentation masks and per-pixel affinity fields. These affinity fields, along with the binary masks, can then be used to cluster lane pixels horizontally and vertically into corresponding lane instances in a post-processing step. This clustering is achieved through a simple row-by-row decoding process with little overhead; such an approach allows LaneAF to detect a variable number of lanes without assuming a fixed or maximum number of lanes. Moreover, this form of clustering is more interpretable in comparison to previous visual clustering approaches, and can be analyzed to identify and correct sources of error. Qualitative and quantitative results obtained on popular lane detection datasets demonstrate the model's ability to detect and cluster lanes effectively and robustly. Our proposed approach performs on par with state-of-the-art approaches on the limited TuSimple benchmark, and sets a new state-of-the-art on the challenging CULane dataset.
TrackMPNN: A Message Passing Graph Neural Architecture for Multi-Object Tracking
Jan 28, 2021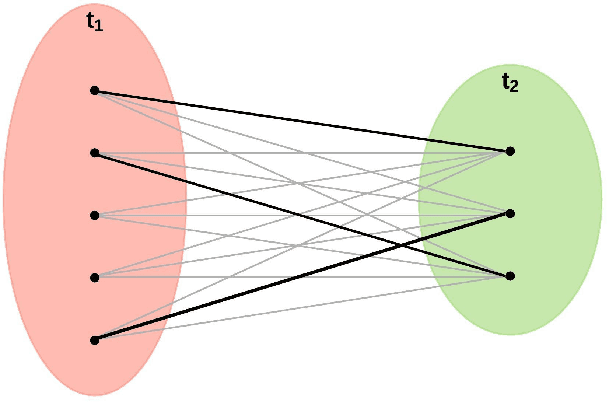
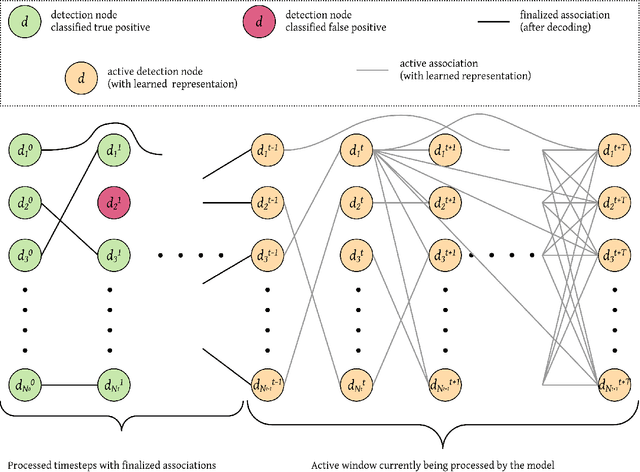
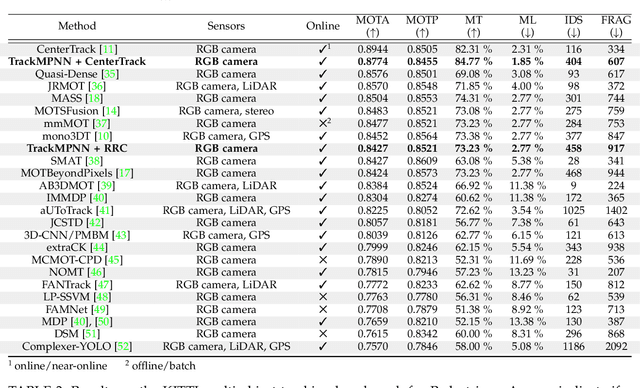
This study follows many previous approaches to multi-object tracking (MOT) that model the problem using graph-based data structures, and adapts this formulation to make it amenable to modern neural networks. Our main contributions in this work are the creation of a framework based on dynamic undirected graphs that represent the data association problem over multiple timesteps, and a message passing graph neural network (GNN) that operates on these graphs to produce the desired likelihood for every association therein. We further provide solutions and propositions for the computational problems that need to be addressed to create a memory-efficient, real-time, online algorithm that can reason over multiple timesteps, correct previous mistakes, update beliefs, possess long-term memory, and handle missed/false detections. In addition to this, our framework provides flexibility in the choice of temporal window sizes to operate on and the losses used for training. In essence, this study provides a framework for any kind of graph based neural network to be trained using conventional techniques from supervised learning, and then use these trained models to infer on new sequences in an online, real-time, computationally tractable manner. To demonstrate the efficacy and robustness of our approach, we only use the 2D box location and object category to construct the descriptor for each object instance. Despite this, our model performs on par with state-of-the-art approaches that make use of multiple hand-crafted and/or learned features. Experiments, qualitative examples and competitive results on popular MOT benchmarks for autonomous driving demonstrate the promise and uniqueness of the proposed approach.
Trajectory Prediction for Autonomous Driving based on Multi-Head Attention with Joint Agent-Map Representation
Jun 04, 2020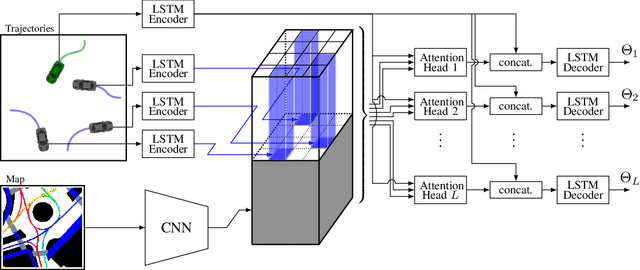

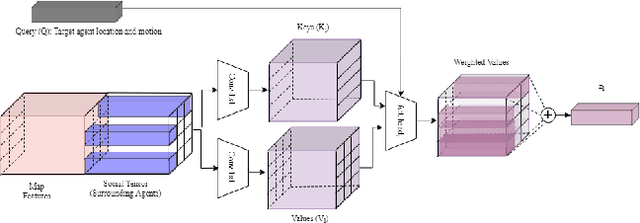
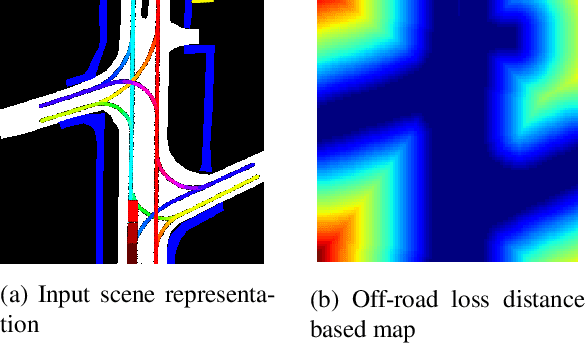
Predicting the trajectories of surrounding agents is an essential ability for robots navigating complex real-world environments. Autonomous vehicles (AV) in particular, can generate safe and efficient path plans by predicting the motion of surrounding road users. Future trajectories of agents can be inferred using two tightly linked cues: the locations and past motion of agents, and the static scene structure. The configuration of the agents may uncover which part of the scene is more relevant, while the scene structure can determine the relative influence of agents on each other's motion. To better model the interdependence of the two cues, we propose a multi-head attention-based model that uses a joint representation of the static scene and agent configuration for generating both keys and values for the attention heads. Moreover, to address the multimodality of future agent motion, we propose to use each attention head to generate a distinct future trajectory of the agent. Our model achieves state of the art results on the publicly available nuScenes dataset and generates diverse future trajectories compliant with scene structure and agent configuration. Additionally, the visualization of attention maps adds a layer of interpretability to the trajectories predicted by the model.
Driver Gaze Estimation in the Real World: Overcoming the Eyeglass Challenge
Feb 11, 2020

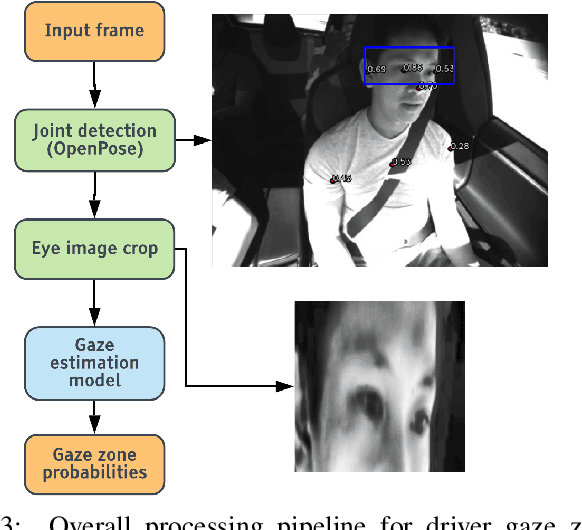
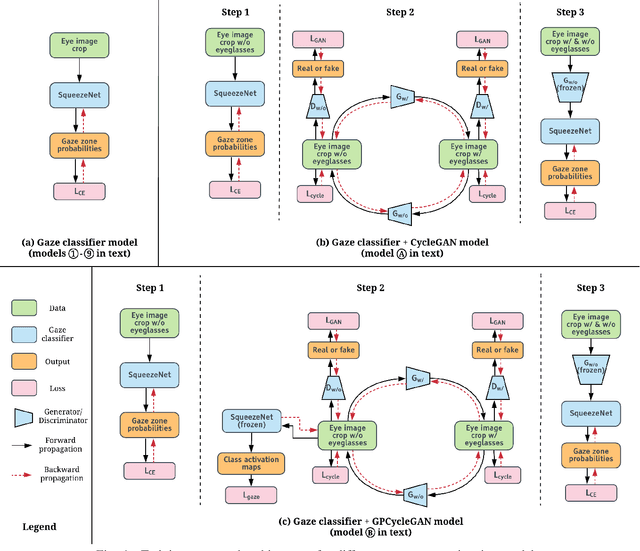
A driver's gaze is critical for determining the driver's attention level, state, situational awareness, and readiness to take over control from partially and fully automated vehicles. Tracking both the head and eyes (pupils) can provide reliable estimation of a driver's gaze using face images under ideal conditions. However, the vehicular environment introduces a variety of challenges that are usually unaccounted for - harsh illumination, nighttime conditions, and reflective/dark eyeglasses. Unfortunately, relying on head pose alone under such conditions can prove to be unreliable owing to significant eye movements. In this study, we offer solutions to address these problems encountered in the real world. To solve issues with lighting, we demonstrate that using an infrared camera with suitable equalization and normalization usually suffices. To handle eyeglasses and their corresponding artifacts, we adopt the idea of image-to-image translation using generative adversarial networks (GANs) to pre-process images prior to gaze estimation. To this end, we propose the Gaze Preserving CycleGAN (GPCycleGAN). As the name suggests, this network preserves the driver's gaze while removing potential eyeglasses from infrared face images. GPCycleGAN is based on the well-known CycleGAN approach, with the addition of a gaze classifier and a gaze consistency loss for additional supervision. Our approach exhibits improved performance and robustness on challenging real-world data spanning 13 subjects and a variety of driving conditions.