 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBP: Path-based Trajectory Prediction for Autonomous Driving
Sep 07, 2023



Trajectory prediction plays a crucial role in the autonomous driving stack by enabling autonomous vehicles to anticipate the motion of surrounding agents. Goal-based prediction models have gained traction in recent years for addressing the multimodal nature of future trajectories. Goal-based prediction models simplify multimodal prediction by first predicting 2D goal locations of agents and then predicting trajectories conditioned on each goal. However, a single 2D goal location serves as a weak inductive bias for predicting the whole trajectory, often leading to poor map compliance, i.e., part of the trajectory going off-road or breaking traffic rules. In this paper, we improve upon goal-based prediction by proposing the Path-based prediction (PBP) approach. PBP predicts a discrete probability distribution over reference paths in the HD map using the path features and predicts trajectories in the path-relative Frenet frame. We applied the PBP trajectory decoder on top of the HiVT scene encoder and report results on the Argoverse dataset. Our experiments show that PBP achieves competitive performance on the standard trajectory prediction metrics, while significantly outperforming state-of-the-art baselines in terms of map compliance.
Salient Sign Detection In Safe Autonomous Driving: AI Which Reasons Over Full Visual Context
Jan 18, 2023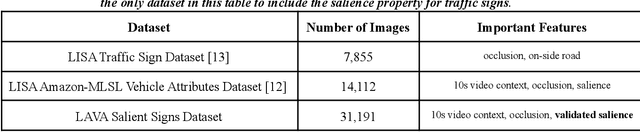



Detecting road traffic signs and accurately determining how they can affect the driver's future actions is a critical task for safe autonomous driving systems. However, various traffic signs in a driving scene have an unequal impact on the driver's decisions, making detecting the salient traffic signs a more important task. Our research addresses this issue, constructing a traffic sign detection model which emphasizes performance on salient signs, or signs that influence the decisions of a driver. We define a traffic sign salience property and use it to construct the LAVA Salient Signs Dataset, the first traffic sign dataset that includes an annotated salience property. Next, we use a custom salience loss function, Salience-Sensitive Focal Loss, to train a Deformable DETR object detection model in order to emphasize stronger performance on salient signs. Results show that a model trained with Salience-Sensitive Focal Loss outperforms a model trained without, with regards to recall of both salient signs and all signs combined. Further, the performance margin on salient signs compared to all signs is largest for the model trained with Salience-Sensitive Focal Loss.
Safe Control Transitions: Machine Vision Based Observable Readiness Index and Data-Driven Takeover Time Prediction
Jan 18, 2023



To make safe transitions from autonomous to manual control, a vehicle must have a representation of the awareness of driver state; two metrics which quantify this state are the Observable Readiness Index and Takeover Time. In this work, we show that machine learning models which predict these two metrics are robust to multiple camera views, expanding from the limited view angles in prior research. Importantly, these models take as input feature vectors corresponding to hand location and activity as well as gaze location, and we explore the tradeoffs of different views in generating these feature vectors. Further, we introduce two metrics to evaluate the quality of control transitions following the takeover event (the maximal lateral deviation and velocity deviation) and compute correlations of these post-takeover metrics to the pre-takeover predictive metrics.
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021
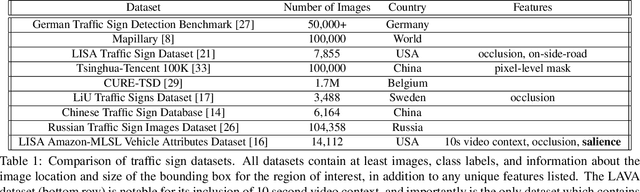

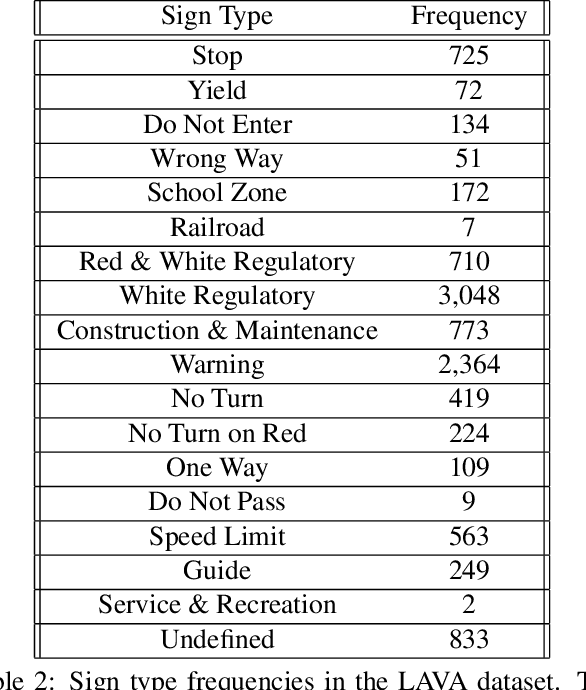
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Predicting Take-over Time for Autonomous Driving with Real-World Data: Robust Data Augmentation, Models, and Evaluation
Jul 27, 2021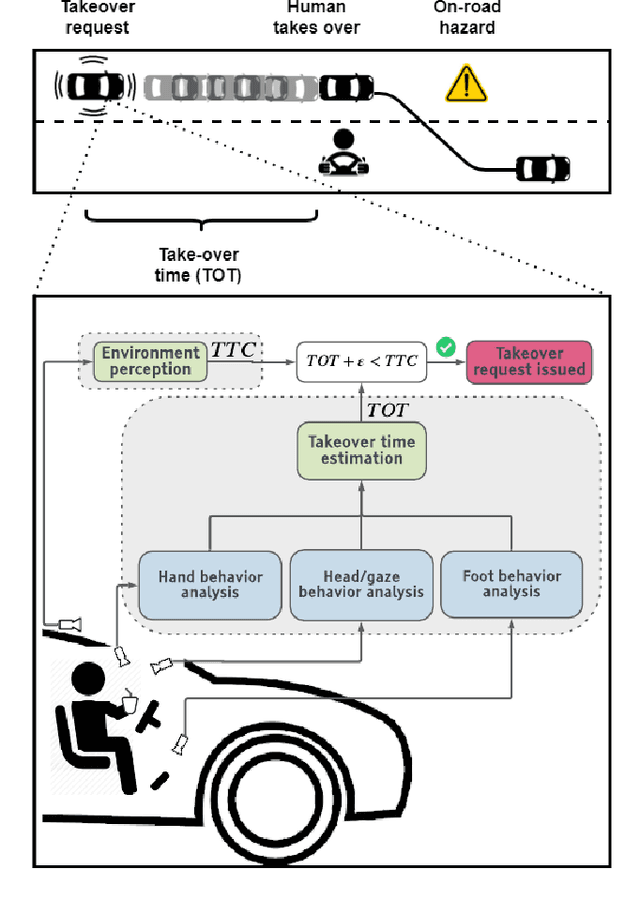

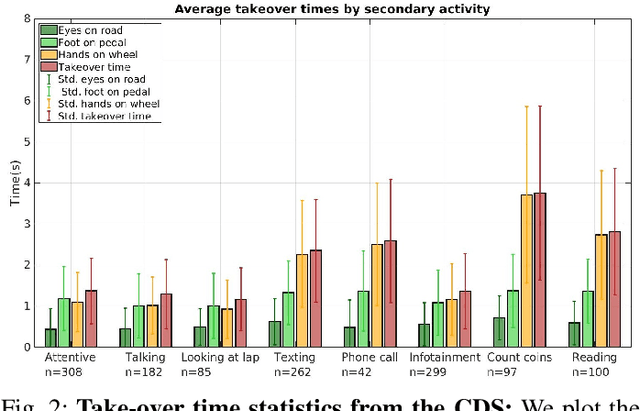
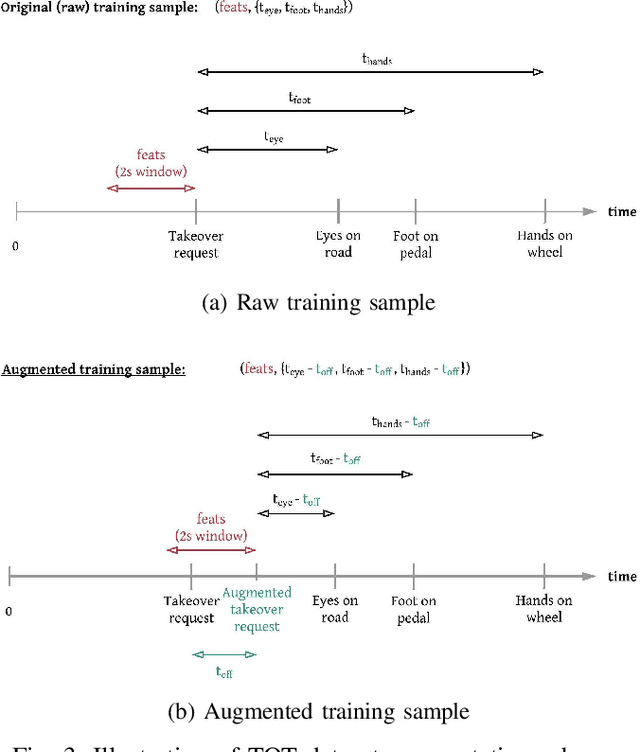
Understanding occupant-vehicle interactions by modeling control transitions is important to ensure safe approaches to passenger vehicle automation. Models which contain contextual, semantically meaningful representations of driver states can be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. However, such models rely on real-world control take-over data from drivers engaged in distracting activities, which is costly to collect. Here, we introduce a scheme for data augmentation for such a dataset. Using the augmented dataset, we develop and train take-over time (TOT) models that operate sequentially on mid and high-level features produced by computer vision algorithms operating on different driver-facing camera views, showing models trained on the augmented dataset to outperform the initial dataset. The demonstrated model features encode different aspects of the driver state, pertaining to the face, hands, foot and upper body of the driver. We perform ablative experiments on feature combinations as well as model architectures, showing that a TOT model supported by augmented data can be used to produce continuous estimates of take-over times without delay, suitable for complex real-world scenarios.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals
Jun 28, 2021



Accurately predicting the future motion of surrounding vehicles requires reasoning about the inherent uncertainty in goals and driving behavior. This uncertainty can be loosely decoupled into lateral (e.g., keeping lane, turning) and longitudinal (e.g., accelerating, braking). We present a novel method that combines learned discrete policy rollouts with a focused decoder on subsets of the lane graph. The policy rollouts explore different goals given our current observations, ensuring that the model captures lateral variability. The longitudinal variability is captured by our novel latent variable model decoder that is conditioned on various subsets of the lane graph. Our model achieves state-of-the-art performance on the nuScenes motion prediction dataset, and qualitatively demonstrates excellent scene compliance. Detailed ablations highlight the importance of both the policy rollouts and the decoder architecture.
Autonomous Vehicles that Alert Humans to Take-Over Controls: Modeling with Real-World Data
Apr 23, 2021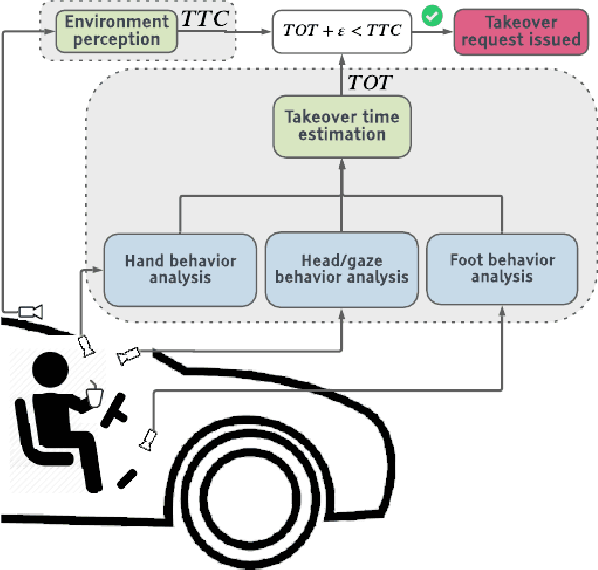
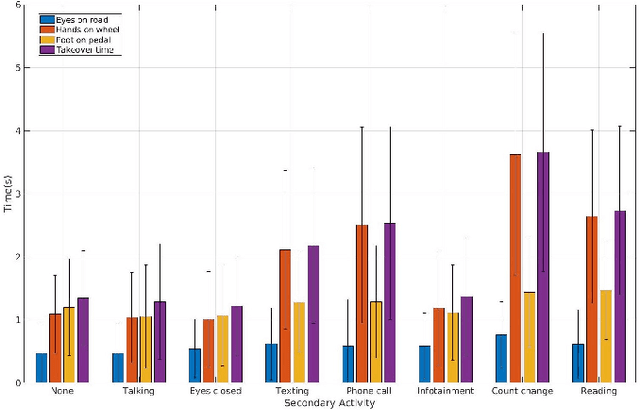
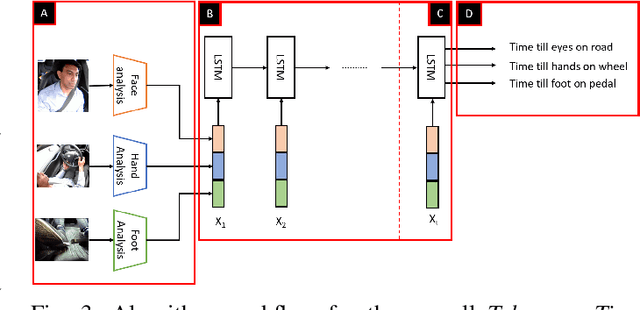
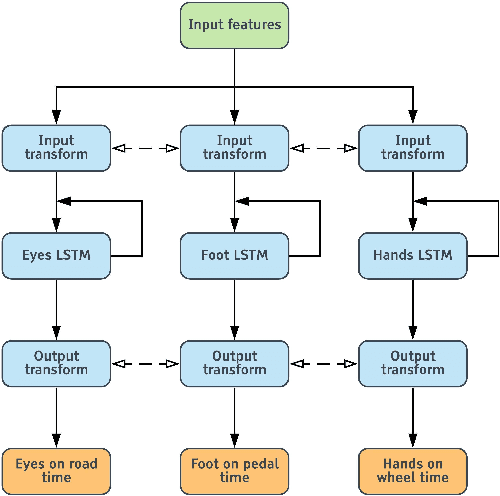
With increasing automation in passenger vehicles, the study of safe and smooth occupant-vehicle interaction and control transitions is key. In this study, we focus on the development of contextual, semantically meaningful representations of the driver state, which can then be used to determine the appropriate timing and conditions for transfer of control between driver and vehicle. To this end, we conduct a large-scale real-world controlled data study where participants are instructed to take-over control from an autonomous agent under different driving conditions while engaged in a variety of distracting activities. These take-over events are captured using multiple driver-facing cameras, which when labelled result in a dataset of control transitions and their corresponding take-over times (TOTs). After augmenting this dataset, we develop and train TOT models that operate sequentially on low and mid-level features produced by computer vision algorithms operating on different driver-facing camera views. The proposed TOT model produces continuous estimates of take-over times without delay, and shows promising qualitative and quantitative results in complex real-world scenarios.
Trajectory Prediction in Autonomous Driving with a Lane Heading Auxiliary Loss
Nov 12, 2020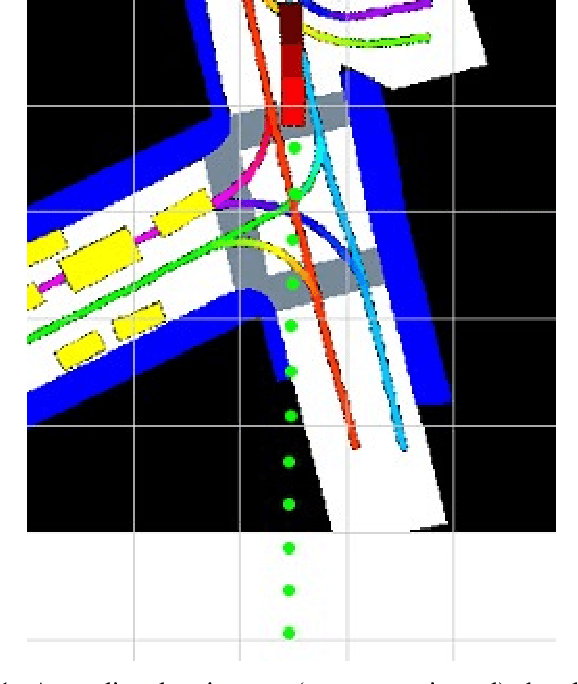
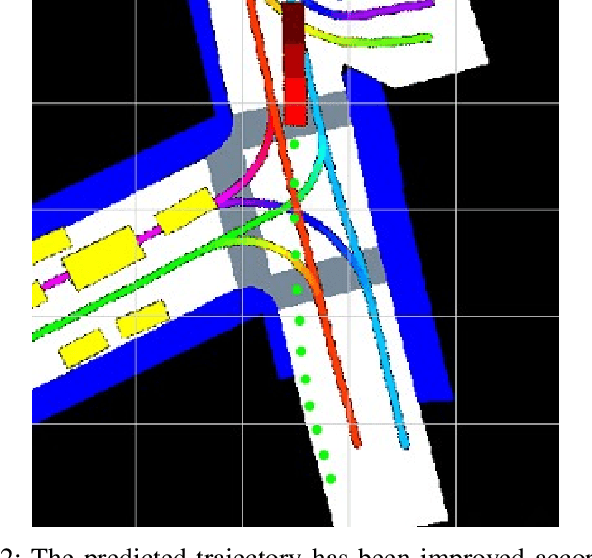
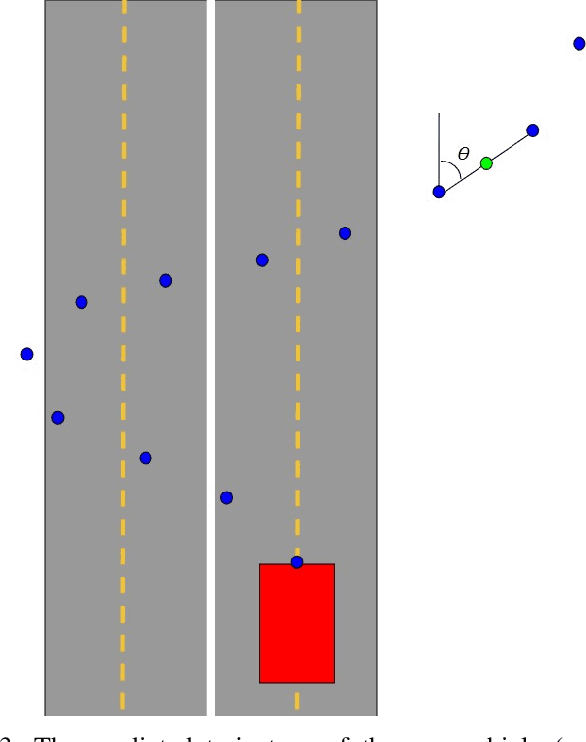

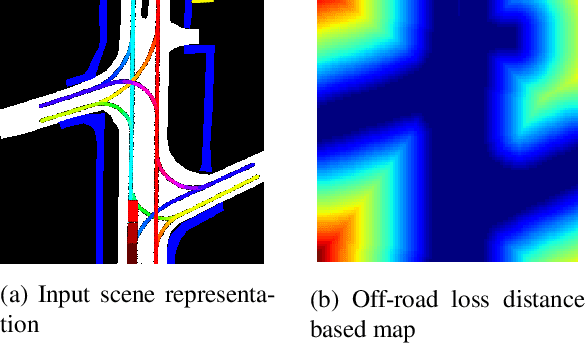
Predicting a vehicle's trajectory is an essential ability for autonomous vehicles navigating through complex urban traffic scenes. Bird's-eye-view roadmap information provides valuable information for making trajectory predictions, and while state-of-the-art models extract this information via image convolution, auxiliary loss functions can augment patterns inferred from deep learning by further encoding common knowledge of social and legal driving behaviors. Since human driving behavior is inherently multimodal, models which allow for multimodal output tend to outperform single-prediction models on standard metrics; the proposed loss function benefits such models, as all predicted modes must follow the same expected driving rules. Our contribution to trajectory prediction is twofold; we propose a new metric which addresses failure cases of the off-road rate metric by penalizing trajectories that contain driving behavior that opposes the ascribed heading (flow direction) of a driving lane, and we show this metric to be differentiable and therefore suitable as an auxiliary loss function. We then use this auxiliary loss to extend the the standard multiple trajectory prediction (MTP) and MultiPath models, achieving improved results on the nuScenes prediction benchmark by predicting trajectories which better conform to the lane-following rules of the road.
Trajectory Prediction for Autonomous Driving based on Multi-Head Attention with Joint Agent-Map Representation
Jun 04, 2020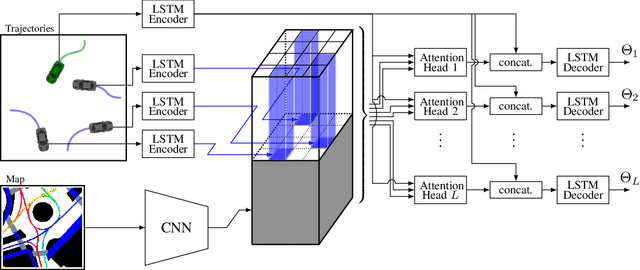

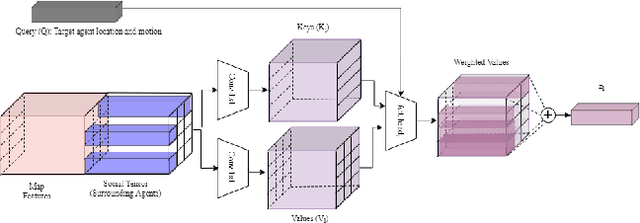
Predicting the trajectories of surrounding agents is an essential ability for robots navigating complex real-world environments. Autonomous vehicles (AV) in particular, can generate safe and efficient path plans by predicting the motion of surrounding road users. Future trajectories of agents can be inferred using two tightly linked cues: the locations and past motion of agents, and the static scene structure. The configuration of the agents may uncover which part of the scene is more relevant, while the scene structure can determine the relative influence of agents on each other's motion. To better model the interdependence of the two cues, we propose a multi-head attention-based model that uses a joint representation of the static scene and agent configuration for generating both keys and values for the attention heads. Moreover, to address the multimodality of future agent motion, we propose to use each attention head to generate a distinct future trajectory of the agent. Our model achieves state of the art results on the publicly available nuScenes dataset and generates diverse future trajectories compliant with scene structure and agent configuration. Additionally, the visualization of attention maps adds a layer of interpretability to the trajectories predicted by the model.
Trajectory Forecasts in Unknown Environments Conditioned on Grid-Based Plans
Jan 03, 2020



In this paper, we address the problem of forecasting agent trajectories in unknown environments, conditioned on their past motion and scene structure. Trajectory forecasting is a challenging problem due to the large variation in scene structure, and the multi-modal nature of the distribution of future trajectories. Unlike prior approaches that directly learn one-to-many mappings from observed context, to multiple future trajectories, we propose to condition trajectory forecasts on \textit{plans} sampled from a grid based policy learned using maximum entropy inverse reinforcement learning policy (MaxEnt IRL). We reformulate MaxEnt IRL to allow the policy to jointly infer plausible agent goals and paths to those goals on a coarse 2-D grid defined over an unknown scene. We propose an attention based trajectory generator that generates continuous valued future trajectories conditioned on state sequences sampled from the MaxEnt policy. Quantitative and qualitative evaluation on the publicly available Stanford drone dataset (SDD) shows that our model generates trajectories that are (1) diverse, representing the multi-modal predictive distribution, and (2) precise, conforming to the underlying scene structure over long prediction horizons, achieving state of the art results on the TrajNet benchmark split of SDD.