 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety-Critical Learning for Long-Tail Events: The TUM Traffic Accident Dataset
Aug 20, 2025Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as an unavoidable and sporadic outcome of traffic networks. We present the TUM Traffic Accident (TUMTraf-A) dataset, a collection of real-world highway accidents. It contains ten sequences of vehicle crashes at high-speed driving with 294,924 labeled 2D and 93,012 labeled 3D boxes and track IDs within 48,144 labeled frames recorded from four roadside cameras and LiDARs at 10 Hz. The dataset contains ten object classes and is provided in the OpenLABEL format. We propose Accid3nD, an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our project website: https://tum-traffic-dataset.github.io/tumtraf-a.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025



Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
Mar 28, 2024Vision-Language Models (VLMs) and Multi-Modal Language models (MMLMs) have become prominent in autonomous driving research, as these models can provide interpretable textual reasoning and responses for end-to-end autonomous driving safety tasks using traffic scene images and other data modalities. However, current approaches to these systems use expensive large language model (LLM) backbones and image encoders, making such systems unsuitable for real-time autonomous driving systems where tight memory constraints exist and fast inference time is necessary. To address these previous issues, we develop EM-VLM4AD, an efficient, lightweight, multi-frame vision language model which performs Visual Question Answering for autonomous driving. In comparison to previous approaches, EM-VLM4AD requires at least 10 times less memory and floating point operations, while also achieving higher BLEU-4, METEOR, CIDEr, and ROGUE scores than the existing baseline on the DriveLM dataset. EM-VLM4AD also exhibits the ability to extract relevant information from traffic views related to prompts and can answer questions for various autonomous driving subtasks. We release our code to train and evaluate our model at https://github.com/akshaygopalkr/EM-VLM4AD.
Vision-based Analysis of Driver Activity and Driving Performance Under the Influence of Alcohol
Sep 14, 2023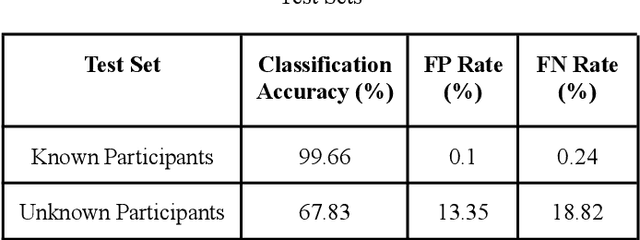

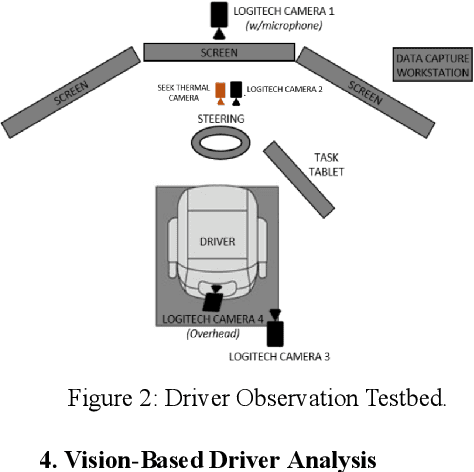
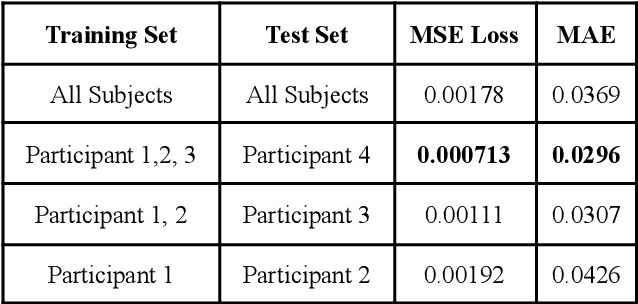
About 30% of all traffic crash fatalities in the United States involve drunk drivers, making the prevention of drunk driving paramount to vehicle safety in the US and other locations which have a high prevalence of driving while under the influence of alcohol. Driving impairment can be monitored through active use of sensors (when drivers are asked to engage in providing breath samples to a vehicle instrument or when pulled over by a police officer), but a more passive and robust mechanism of sensing may allow for wider adoption and benefit of intelligent systems that reduce drunk driving accidents. This could assist in identifying impaired drivers before they drive, or early in the driving process (before a crash or detection by law enforcement). In this research, we introduce a study which adopts a multi-modal ensemble of visual, thermal, audio, and chemical sensors to (1) examine the impact of acute alcohol administration on driving performance in a driving simulator, and (2) identify data-driven methods for detecting driving under the influence of alcohol. We describe computer vision and machine learning models for analyzing the driver's face in thermal imagery, and introduce a pipeline for training models on data collected from drivers with a range of breath-alcohol content levels, including discussion of relevant machine learning phenomena which can help in future experiment design for related studies.
Robust Detection, Assocation, and Localization of Vehicle Lights: A Context-Based Cascaded CNN Approach and Evaluations
Jul 27, 2023Vehicle light detection is required for important downstream safe autonomous driving tasks, such as predicting a vehicle's light state to determine if the vehicle is making a lane change or turning. Currently, many vehicle light detectors use single-stage detectors which predict bounding boxes to identify a vehicle light, in a manner decoupled from vehicle instances. In this paper, we present a method for detecting a vehicle light given an upstream vehicle detection and approximation of a visible light's center. Our method predicts four approximate corners associated with each vehicle light. We experiment with CNN architectures, data augmentation, and contextual preprocessing methods designed to reduce surrounding-vehicle confusion. We achieve an average distance error from the ground truth corner of 5.09 pixels, about 17.24% of the size of the vehicle light on average. We train and evaluate our model on the LISA Lights dataset, allowing us to thoroughly evaluate our vehicle light corner detection model on a large variety of vehicle light shapes and lighting conditions. We propose that this model can be integrated into a pipeline with vehicle detection and vehicle light center detection to make a fully-formed vehicle light detection network, valuable to identifying trajectory-informative signals in driving scenes.
Patterns of Vehicle Lights: Addressing Complexities in Curation and Annotation of Camera-Based Vehicle Light Datasets and Metrics
Jul 26, 2023



This paper explores the representation of vehicle lights in computer vision and its implications for various tasks in the field of autonomous driving. Different specifications for representing vehicle lights, including bounding boxes, center points, corner points, and segmentation masks, are discussed in terms of their strengths and weaknesses. Three important tasks in autonomous driving that can benefit from vehicle light detection are identified: nighttime vehicle detection, 3D vehicle orientation estimation, and dynamic trajectory cues. Each task may require a different representation of the light. The challenges of collecting and annotating large datasets for training data-driven models are also addressed, leading to introduction of the LISA Vehicle Lights Dataset and associated Light Visibility Model, which provides light annotations specifically designed for downstream applications in vehicle detection, intent and trajectory prediction, and safe path planning. A comparison of existing vehicle light datasets is provided, highlighting the unique features and limitations of each dataset. Overall, this paper provides insights into the representation of vehicle lights and the importance of accurate annotations for training effective detection models in autonomous driving applications. Our dataset and model are made available at https://cvrr.ucsd.edu/vehicle-lights-dataset
Robust Traffic Light Detection Using Salience-Sensitive Loss: Computational Framework and Evaluations
May 08, 2023

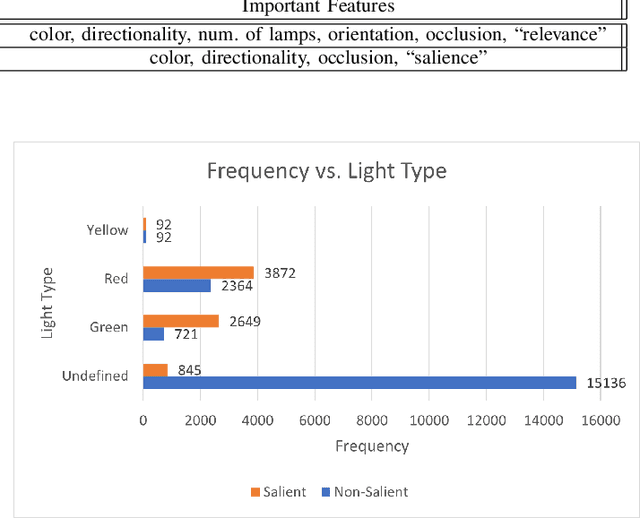

One of the most important tasks for ensuring safe autonomous driving systems is accurately detecting road traffic lights and accurately determining how they impact the driver's actions. In various real-world driving situations, a scene may have numerous traffic lights with varying levels of relevance to the driver, and thus, distinguishing and detecting the lights that are relevant to the driver and influence the driver's actions is a critical safety task. This paper proposes a traffic light detection model which focuses on this task by first defining salient lights as the lights that affect the driver's future decisions. We then use this salience property to construct the LAVA Salient Lights Dataset, the first US traffic light dataset with an annotated salience property. Subsequently, we train a Deformable DETR object detection transformer model using Salience-Sensitive Focal Loss to emphasize stronger performance on salient traffic lights, showing that a model trained with this loss function has stronger recall than one trained without.
Pedestrian Behavior Maps for Safety Advisories: CHAMP Framework and Real-World Data Analysis
May 08, 2023


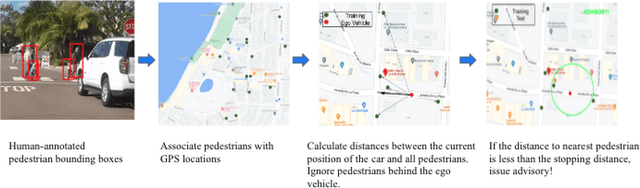
It is critical for vehicles to prevent any collisions with pedestrians. Current methods for pedestrian collision prevention focus on integrating visual pedestrian detectors with Automatic Emergency Braking (AEB) systems which can trigger warnings and apply brakes as a pedestrian enters a vehicle's path. Unfortunately, pedestrian-detection-based systems can be hindered in certain situations such as night-time or when pedestrians are occluded. Our system addresses such issues using an online, map-based pedestrian detection aggregation system where common pedestrian locations are learned after repeated passes of locations. Using a carefully collected and annotated dataset in La Jolla, CA, we demonstrate the system's ability to learn pedestrian zones and generate advisory notices when a vehicle is approaching a pedestrian despite challenges like dark lighting or pedestrian occlusion. Using the number of correct advisories, false advisories, and missed advisories to define precision and recall performance metrics, we evaluate our system and discuss future positive effects with further data collection. We have made our code available at https://github.com/s7desai/ped-mapping, and a video demonstration of the CHAMP system at https://youtu.be/dxeCrS_Gpkw.
Multi-View Ensemble Learning With Missing Data: Computational Framework and Evaluations using Novel Data from the Safe Autonomous Driving Domain
Jan 30, 2023

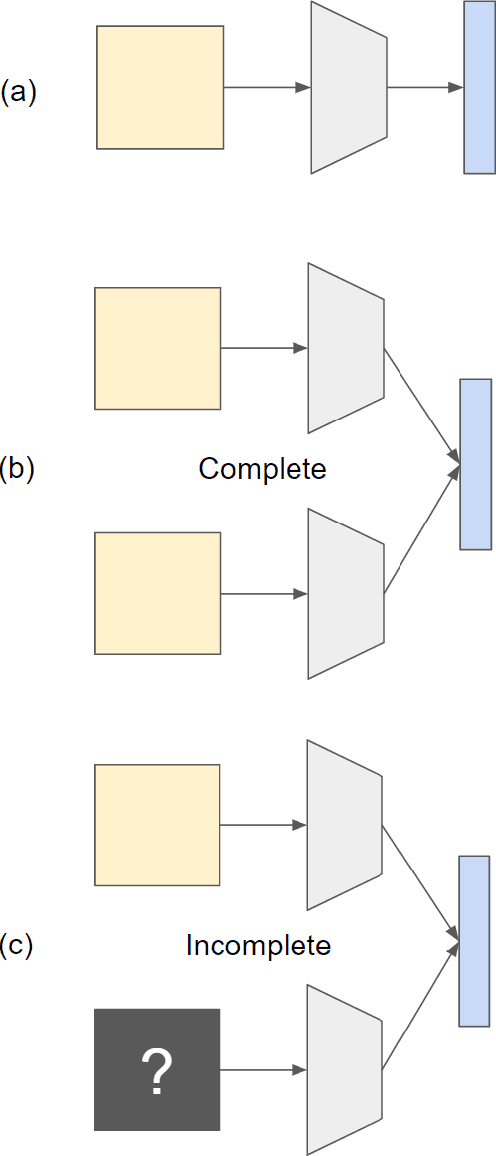

Real-world applications with multiple sensors observing an event are expected to make continuously-available predictions, even in cases where information may be intermittently missing. We explore methods in ensemble learning and sensor fusion to make use of redundancy and information shared between four camera views, applied to the task of hand activity classification for autonomous driving. In particular, we show that a late-fusion approach between parallel convolutional neural networks can outperform even the best-placed single camera model. To enable this approach, we propose a scheme for handling missing information, and then provide comparative analysis of this late-fusion approach to additional methods such as weighted majority voting and model combination schemes.
CHAMP: Crowdsourced, History-Based Advisory of Mapped Pedestrians for Safer Driver Assistance Systems
Jan 18, 2023
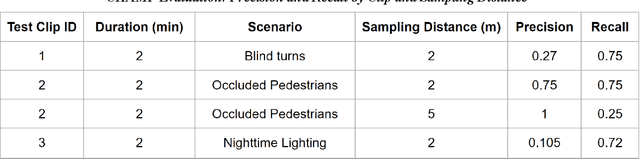

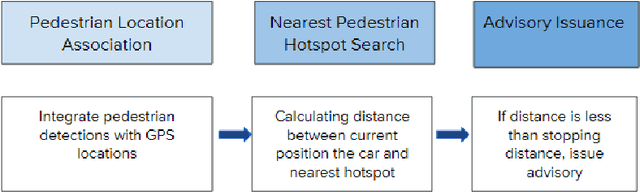
Vehicles are constantly approaching and sharing the road with pedestrians, and as a result it is critical for vehicles to prevent any collisions with pedestrians. Current methods for pedestrian collision prevention focus on integrating visual pedestrian detectors with Automatic Emergency Braking (AEB) systems which can trigger warnings and apply brakes as a pedestrian enters a vehicle's path. Unfortunately, pedestrian-detection-based systems can be hindered in certain situations such as nighttime or when pedestrians are occluded. Our system, CHAMP (Crowdsourced, History-based Advisories of Mapped Pedestrians), addresses such issues using an online, map-based pedestrian detection system where pedestrian locations are aggregated into a dataset after repeated passes of locations. Using this dataset, we are able to learn pedestrian zones and generate advisory notices when a vehicle is approaching a pedestrian despite challenges like dark lighting or pedestrian occlusion. We collected and carefully annotated pedestrian data in La Jolla, CA to construct training and test sets of pedestrian locations. Moreover, we use the number of correct advisories, false advisories, and missed advisories to define precision and recall performance metrics to evaluate CHAMP. This approach can be tuned such that we achieve a maximum of 100% precision and 75% recall on the experimental dataset, with performance enhancement options through further data collection.