 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGTA: Scene-Graph Based Multi-Modal Traffic Agent for Video Understanding
Apr 04, 2026We present Scene-Graph Based Multi-Modal Traffic Agent (SGTA), a modular framework for traffic video understanding that combines structured scene graphs with multi-modal reasoning. It constructs a traffic scene graph from roadside videos using detection, tracking, and lane extraction, followed by tool-based reasoning over both symbolic graph queries and visual inputs. SGTA adopts ReAct to process interleaved reasoning traces from large language models with tool invocations, enabling interpretable decision-making for complex video questions. Experiments on selected TUMTraffic VideoQA dataset sample demonstrate that SGTA achieves competitive accuracy across multiple question types while providing transparent reasoning steps. These results highlight the potential of integrating structured scene representations with multi-modal agents for traffic video understanding.
Energy-Aware Imitation Learning for Steering Prediction Using Events and Frames
Mar 30, 2026In autonomous driving, relying solely on frame-based cameras can lead to inaccuracies caused by factors like long exposure times, high-speed motion, and challenging lighting conditions. To address these issues, we introduce a bio-inspired vision sensor known as the event camera. Unlike conventional cameras, event cameras capture sparse, asynchronous events that provide a complementary modality to mitigate these challenges. In this work, we propose an energy-aware imitation learning framework for steering prediction that leverages both events and frames. Specifically, we design an Energy-driven Cross-modality Fusion Module (ECFM) and an energy-aware decoder to produce reliable and safe predictions. Extensive experiments on two public real-world datasets, DDD20 and DRFuser, demonstrate that our method outperforms existing state-of-the-art (SOTA) approaches. The codes and trained models will be released upon acceptance.
SegRGB-X: General RGB-X Semantic Segmentation Model
Mar 30, 2026Semantic segmentation across arbitrary sensor modalities faces significant challenges due to diverse sensor characteristics, and the traditional configurations for this task result in redundant development efforts. We address these challenges by introducing a universal arbitrary-modal semantic segmentation framework that unifies segmentation across multiple modalities. Our approach features three key innovations: (1) the Modality-aware CLIP (MA-CLIP), which provides modality-specific scene understanding guidance through LoRA fine-tuning; (2) Modality-aligned Embeddings for capturing fine-grained features; and (3) the Domain-specific Refinement Module (DSRM) for dynamic feature adjustment. Evaluated on five diverse datasets with different complementary modalities (event, thermal, depth, polarization, and light field), our model surpasses specialized multi-modal methods and achieves state-of-the-art performance with a mIoU of 65.03%. The codes will be released upon acceptance.
Safety-Critical Learning for Long-Tail Events: The TUM Traffic Accident Dataset
Aug 20, 2025Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as an unavoidable and sporadic outcome of traffic networks. We present the TUM Traffic Accident (TUMTraf-A) dataset, a collection of real-world highway accidents. It contains ten sequences of vehicle crashes at high-speed driving with 294,924 labeled 2D and 93,012 labeled 3D boxes and track IDs within 48,144 labeled frames recorded from four roadside cameras and LiDARs at 10 Hz. The dataset contains ten object classes and is provided in the OpenLABEL format. We propose Accid3nD, an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our project website: https://tum-traffic-dataset.github.io/tumtraf-a.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025



Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
CoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Mar 09, 2025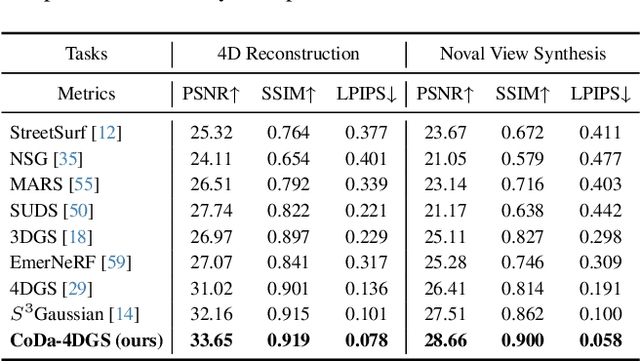
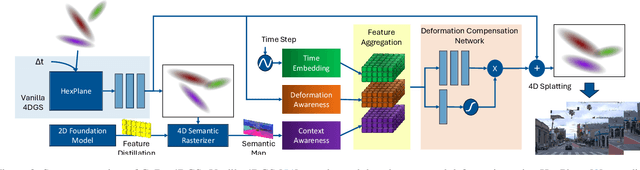
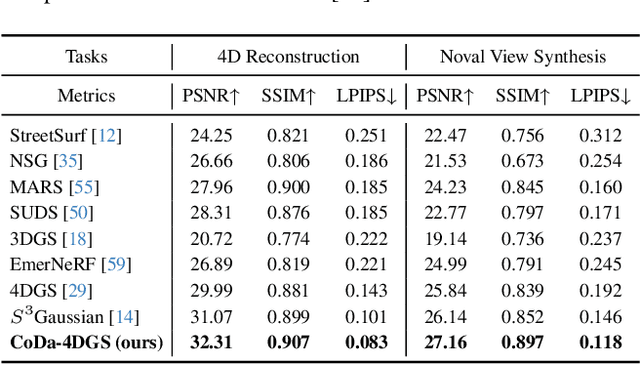

Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS's ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
TUMTraffic-VideoQA: A Benchmark for Unified Spatio-Temporal Video Understanding in Traffic Scenes
Feb 04, 2025



We present TUMTraffic-VideoQA, a novel dataset and benchmark designed for spatio-temporal video understanding in complex roadside traffic scenarios. The dataset comprises 1,000 videos, featuring 85,000 multiple-choice QA pairs, 2,300 object captioning, and 5,700 object grounding annotations, encompassing diverse real-world conditions such as adverse weather and traffic anomalies. By incorporating tuple-based spatio-temporal object expressions, TUMTraffic-VideoQA unifies three essential tasks-multiple-choice video question answering, referred object captioning, and spatio-temporal object grounding-within a cohesive evaluation framework. We further introduce the TUMTraffic-Qwen baseline model, enhanced with visual token sampling strategies, providing valuable insights into the challenges of fine-grained spatio-temporal reasoning. Extensive experiments demonstrate the dataset's complexity, highlight the limitations of existing models, and position TUMTraffic-VideoQA as a robust foundation for advancing research in intelligent transportation systems. The dataset and benchmark are publicly available to facilitate further exploration.
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Aug 28, 2024



Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
WARM-3D: A Weakly-Supervised Sim2Real Domain Adaptation Framework for Roadside Monocular 3D Object Detection
Jul 30, 2024



Existing roadside perception systems are limited by the absence of publicly available, large-scale, high-quality 3D datasets. Exploring the use of cost-effective, extensive synthetic datasets offers a viable solution to tackle this challenge and enhance the performance of roadside monocular 3D detection. In this study, we introduce the TUMTraf Synthetic Dataset, offering a diverse and substantial collection of high-quality 3D data to augment scarce real-world datasets. Besides, we present WARM-3D, a concise yet effective framework to aid the Sim2Real domain transfer for roadside monocular 3D detection. Our method leverages cheap synthetic datasets and 2D labels from an off-the-shelf 2D detector for weak supervision. We show that WARM-3D significantly enhances performance, achieving a +12.40% increase in mAP 3D over the baseline with only pseudo-2D supervision. With 2D GT as weak labels, WARM-3D even reaches performance close to the Oracle baseline. Moreover, WARM-3D improves the ability of 3D detectors to unseen sample recognition across various real-world environments, highlighting its potential for practical applications.