 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structured Unplugged Approach for Foundational AI Literacy in Primary Education
May 27, 2025Younger generations are growing up in a world increasingly shaped by intelligent technologies, making early AI literacy crucial for developing the skills to critically understand and navigate them. However, education in this field often emphasizes tool-based learning, prioritizing usage over understanding the underlying concepts. This lack of knowledge leaves non-experts, especially children, prone to misconceptions, unrealistic expectations, and difficulties in recognizing biases and stereotypes. In this paper, we propose a structured and replicable teaching approach that fosters foundational AI literacy in primary students, by building upon core mathematical elements closely connected to and of interest in primary curricula, to strengthen conceptualization, data representation, classification reasoning, and evaluation of AI. To assess the effectiveness of our approach, we conducted an empirical study with thirty-one fifth-grade students across two classes, evaluating their progress through a post-test and a satisfaction survey. Our results indicate improvements in terminology understanding and usage, features description, logical reasoning, and evaluative skills, with students showing a deeper comprehension of decision-making processes and their limitations. Moreover, the approach proved engaging, with students particularly enjoying activities that linked AI concepts to real-world reasoning. Materials: https://github.com/tail-unica/ai-literacy-primary-ed.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
LIMBA: An Open-Source Framework for the Preservation and Valorization of Low-Resource Languages using Generative Models
Nov 20, 2024

Minority languages are vital to preserving cultural heritage, yet they face growing risks of extinction due to limited digital resources and the dominance of artificial intelligence models trained on high-resource languages. This white paper proposes a framework to generate linguistic tools for low-resource languages, focusing on data creation to support the development of language models that can aid in preservation efforts. Sardinian, an endangered language, serves as the case study to demonstrate the framework's effectiveness. By addressing the data scarcity that hinders intelligent applications for such languages, we contribute to promoting linguistic diversity and support ongoing efforts in language standardization and revitalization through modern technologies.
How Fair is Your Diffusion Recommender Model?
Sep 06, 2024



Diffusion-based recommender systems have recently proven to outperform traditional generative recommendation approaches, such as variational autoencoders and generative adversarial networks. Nevertheless, the machine learning literature has raised several concerns regarding the possibility that diffusion models, while learning the distribution of data samples, may inadvertently carry information bias and lead to unfair outcomes. In light of this aspect, and considering the relevance that fairness has held in recommendations over the last few decades, we conduct one of the first fairness investigations in the literature on DiffRec, a pioneer approach in diffusion-based recommendation. First, we propose an experimental setting involving DiffRec (and its variant L-DiffRec) along with nine state-of-the-art recommendation models, two popular recommendation datasets from the fairness-aware literature, and six metrics accounting for accuracy and consumer/provider fairness. Then, we perform a twofold analysis, one assessing models' performance under accuracy and recommendation fairness separately, and the other identifying if and to what extent such metrics can strike a performance trade-off. Experimental results from both studies confirm the initial unfairness warnings but pave the way for how to address them in future research directions.
The Impact of Balancing Real and Synthetic Data on Accuracy and Fairness in Face Recognition
Sep 04, 2024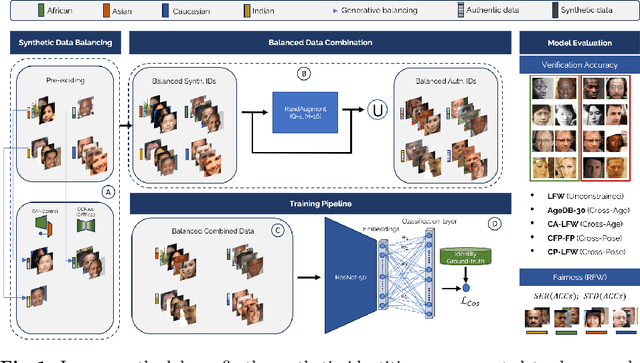

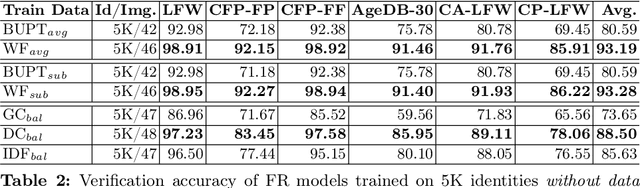
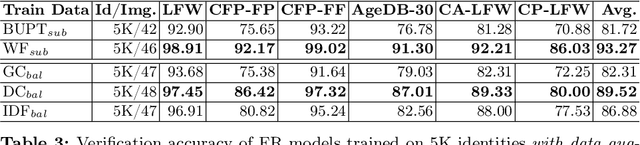
Over the recent years, the advancements in deep face recognition have fueled an increasing demand for large and diverse datasets. Nevertheless, the authentic data acquired to create those datasets is typically sourced from the web, which, in many cases, can lead to significant privacy issues due to the lack of explicit user consent. Furthermore, obtaining a demographically balanced, large dataset is even more difficult because of the natural imbalance in the distribution of images from different demographic groups. In this paper, we investigate the impact of demographically balanced authentic and synthetic data, both individually and in combination, on the accuracy and fairness of face recognition models. Initially, several generative methods were used to balance the demographic representations of the corresponding synthetic datasets. Then a state-of-the-art face encoder was trained and evaluated using (combinations of) synthetic and authentic images. Our findings emphasized two main points: (i) the increased effectiveness of training data generated by diffusion-based models in enhancing accuracy, whether used alone or combined with subsets of authentic data, and (ii) the minimal impact of incorporating balanced data from pre-trained generative methods on fairness (in nearly all tested scenarios using combined datasets, fairness scores remained either unchanged or worsened, even when compared to unbalanced authentic datasets). Source code and data are available at \url{https://cutt.ly/AeQy1K5G} for reproducibility.
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Aug 28, 2024



Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
Fair Augmentation for Graph Collaborative Filtering
Aug 22, 2024
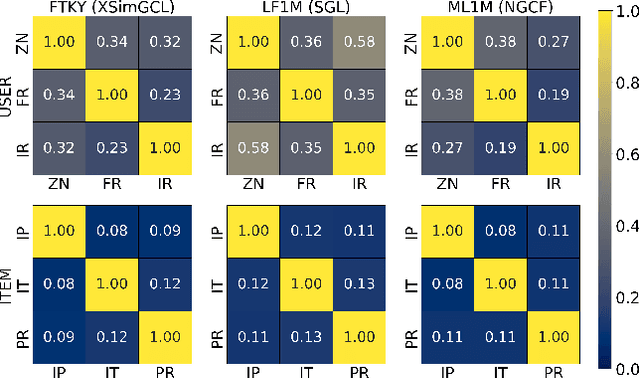


Recent developments in recommendation have harnessed the collaborative power of graph neural networks (GNNs) in learning users' preferences from user-item networks. Despite emerging regulations addressing fairness of automated systems, unfairness issues in graph collaborative filtering remain underexplored, especially from the consumer's perspective. Despite numerous contributions on consumer unfairness, only a few of these works have delved into GNNs. A notable gap exists in the formalization of the latest mitigation algorithms, as well as in their effectiveness and reliability on cutting-edge models. This paper serves as a solid response to recent research highlighting unfairness issues in graph collaborative filtering by reproducing one of the latest mitigation methods. The reproduced technique adjusts the system fairness level by learning a fair graph augmentation. Under an experimental setup based on 11 GNNs, 5 non-GNN models, and 5 real-world networks across diverse domains, our investigation reveals that fair graph augmentation is consistently effective on high-utility models and large datasets. Experiments on the transferability of the fair augmented graph open new issues for future recommendation studies. Source code: https://github.com/jackmedda/FA4GCF.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
If It's Not Enough, Make It So: Reducing Authentic Data Demand in Face Recognition through Synthetic Faces
Apr 04, 2024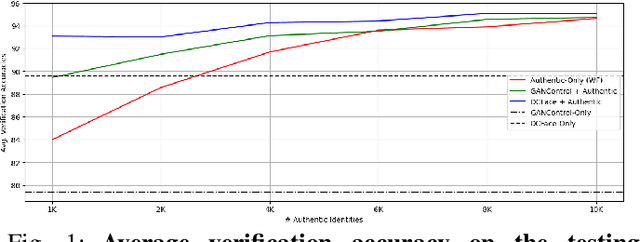
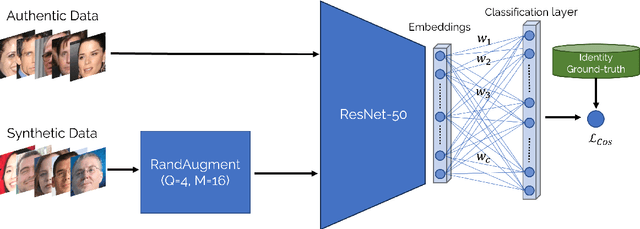
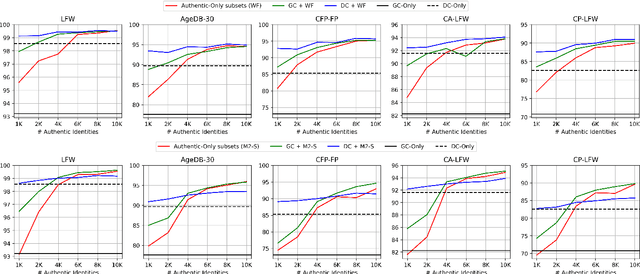
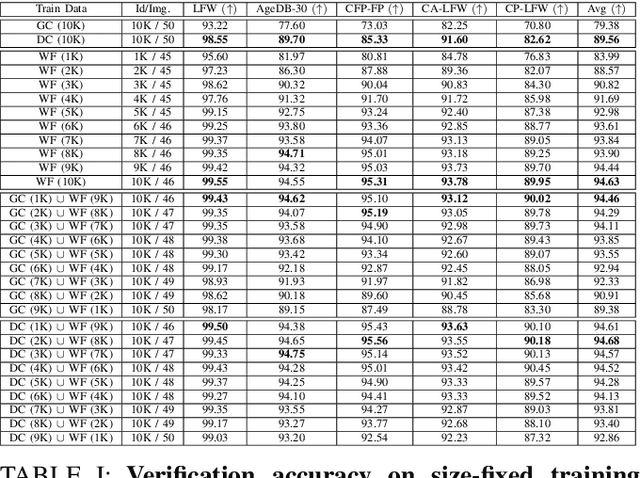
Recent advances in deep face recognition have spurred a growing demand for large, diverse, and manually annotated face datasets. Acquiring authentic, high-quality data for face recognition has proven to be a challenge, primarily due to privacy concerns. Large face datasets are primarily sourced from web-based images, lacking explicit user consent. In this paper, we examine whether and how synthetic face data can be used to train effective face recognition models with reduced reliance on authentic images, thereby mitigating data collection concerns. First, we explored the performance gap among recent state-of-the-art face recognition models, trained with synthetic data only and authentic (scarce) data only. Then, we deepened our analysis by training a state-of-the-art backbone with various combinations of synthetic and authentic data, gaining insights into optimizing the limited use of the latter for verification accuracy. Finally, we assessed the effectiveness of data augmentation approaches on synthetic and authentic data, with the same goal in mind. Our results highlighted the effectiveness of FR trained on combined datasets, particularly when combined with appropriate augmentation techniques.
Robustness in Fairness against Edge-level Perturbations in GNN-based Recommendation
Jan 26, 2024
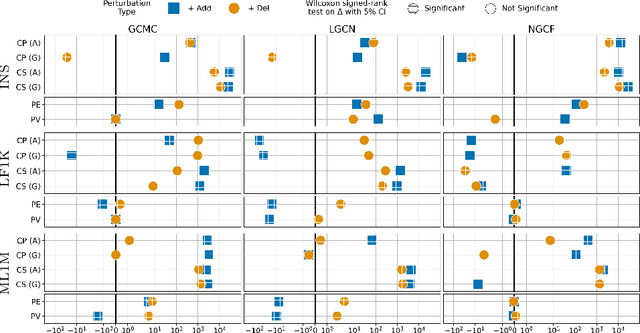

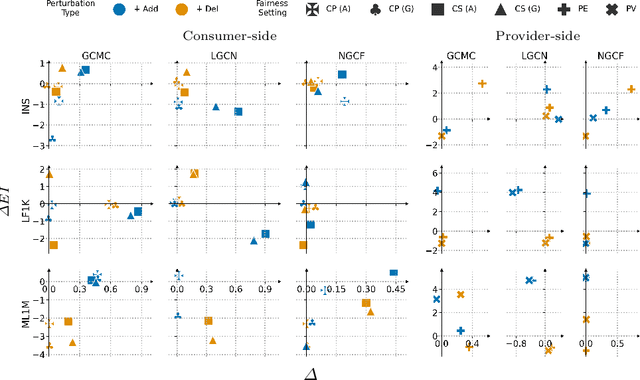
Efforts in the recommendation community are shifting from the sole emphasis on utility to considering beyond-utility factors, such as fairness and robustness. Robustness of recommendation models is typically linked to their ability to maintain the original utility when subjected to attacks. Limited research has explored the robustness of a recommendation model in terms of fairness, e.g., the parity in performance across groups, under attack scenarios. In this paper, we aim to assess the robustness of graph-based recommender systems concerning fairness, when exposed to attacks based on edge-level perturbations. To this end, we considered four different fairness operationalizations, including both consumer and provider perspectives. Experiments on three datasets shed light on the impact of perturbations on the targeted fairness notion, uncovering key shortcomings in existing evaluation protocols for robustness. As an example, we observed perturbations affect consumer fairness on a higher extent than provider fairness, with alarming unfairness for the former. Source code: https://github.com/jackmedda/CPFairRobust