 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Dropout: Leveraging Conway's Game of Life for Neural Networks Regularization
Oct 25, 2025Regularization techniques play a crucial role in preventing overfitting and improving the generalization performance of neural networks. Dropout, a widely used regularization technique, randomly deactivates units during training to introduce redundancy and prevent co-adaptation among neurons. Despite its effectiveness, dropout has limitations, such as its static nature and lack of interpretability. In this paper, we propose a novel approach to regularization by substituting dropout with Conway's Game of Life (GoL), a cellular automata with simple rules that govern the evolution of a grid of cells. We introduce dynamic unit deactivation during training by representing neural network units as cells in a GoL grid and applying the game's rules to deactivate units. This approach allows for the emergence of spatial patterns that adapt to the training data, potentially enhancing the network's ability to generalize. We demonstrate the effectiveness of our approach on the CIFAR-10 dataset, showing that dynamic unit deactivation using GoL achieves comparable performance to traditional dropout techniques while offering insights into the network's behavior through the visualization of evolving patterns. Furthermore, our discussion highlights the applicability of our proposal in deeper architectures, demonstrating how it enhances the performance of different dropout techniques.
An Evaluation of a Visual Question Answering Strategy for Zero-shot Facial Expression Recognition in Still Images
Apr 30, 2025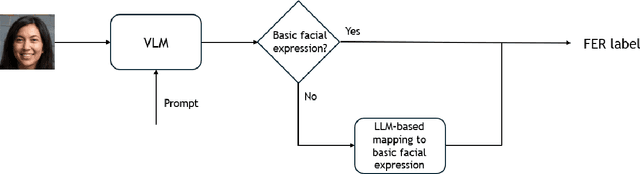

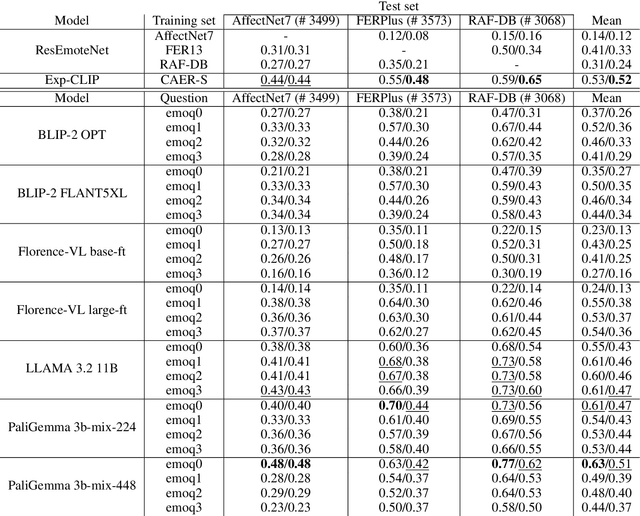
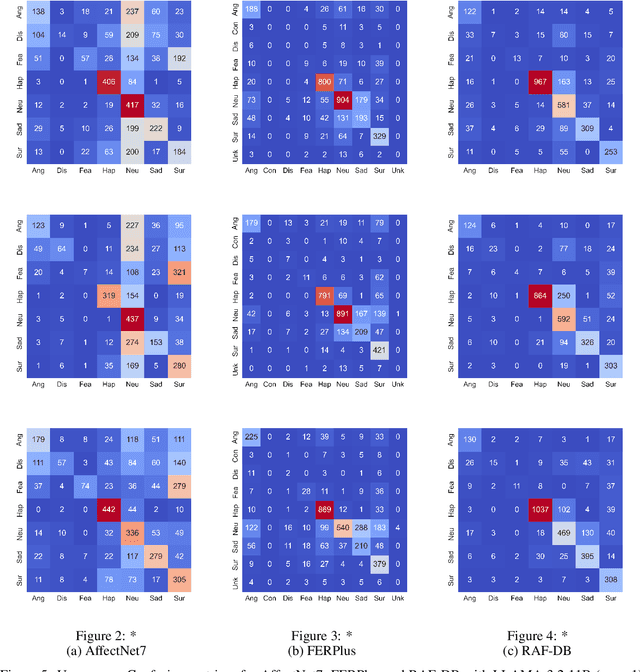
Facial expression recognition (FER) is a key research area in computer vision and human-computer interaction. Despite recent advances in deep learning, challenges persist, especially in generalizing to new scenarios. In fact, zero-shot FER significantly reduces the performance of state-of-the-art FER models. To address this problem, the community has recently started to explore the integration of knowledge from Large Language Models for visual tasks. In this work, we evaluate a broad collection of locally executed Visual Language Models (VLMs), avoiding the lack of task-specific knowledge by adopting a Visual Question Answering strategy. We compare the proposed pipeline with state-of-the-art FER models, both integrating and excluding VLMs, evaluating well-known FER benchmarks: AffectNet, FERPlus, and RAF-DB. The results show excellent performance for some VLMs in zero-shot FER scenarios, indicating the need for further exploration to improve FER generalization.
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Aug 28, 2024



Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
A Large-Scale Re-identification Analysis in Sporting Scenarios: the Betrayal of Reaching a Critical Point
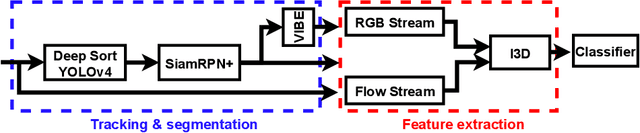
Dec 29, 2023Re-identifying participants in ultra-distance running competitions can be daunting due to the extensive distances and constantly changing terrain. To overcome these challenges, computer vision techniques have been developed to analyze runners' faces, numbers on their bibs, and clothing. However, our study presents a novel gait-based approach for runners' re-identification (re-ID) by leveraging various pre-trained human action recognition (HAR) models and loss functions. Our results show that this approach provides promising results for re-identifying runners in ultra-distance competitions. Furthermore, we investigate the significance of distinct human body movements when athletes are approaching their endurance limits and their potential impact on re-ID accuracy. Our study examines how the recognition of a runner's gait is affected by a competition's critical point (CP), defined as a moment of severe fatigue and the point where the finish line comes into view, just a few kilometers away from this location. We aim to determine how this CP can improve the accuracy of athlete re-ID. Our experimental results demonstrate that gait recognition can be significantly enhanced (up to a 9% increase in mAP) as athletes approach this point. This highlights the potential of utilizing gait recognition in real-world scenarios, such as ultra-distance competitions or long-duration surveillance tasks.
An X3D Neural Network Analysis for Runner's Performance Assessment in a Wild Sporting Environment
Jul 22, 2023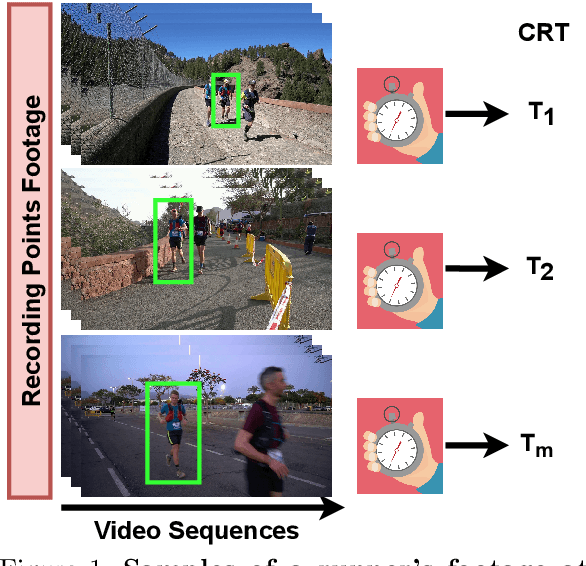
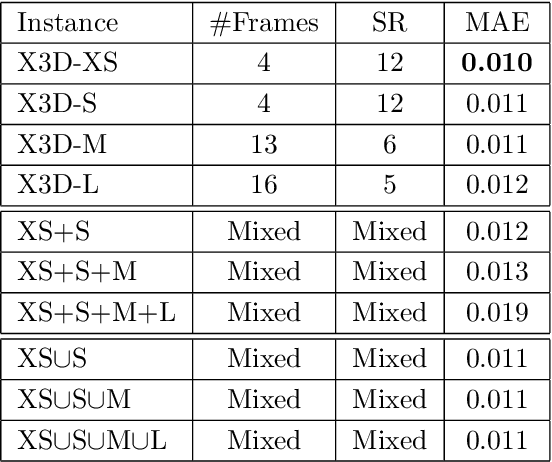
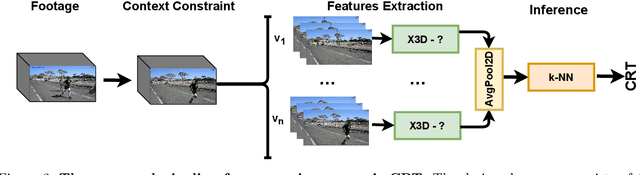
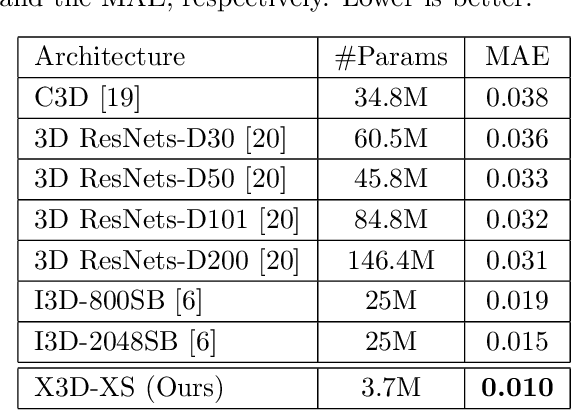
We present a transfer learning analysis on a sporting environment of the expanded 3D (X3D) neural networks. Inspired by action quality assessment methods in the literature, our method uses an action recognition network to estimate athletes' cumulative race time (CRT) during an ultra-distance competition. We evaluate the performance considering the X3D, a family of action recognition networks that expand a small 2D image classification architecture along multiple network axes, including space, time, width, and depth. We demonstrate that the resulting neural network can provide remarkable performance for short input footage, with a mean absolute error of 12 minutes and a half when estimating the CRT for runners who have been active from 8 to 20 hours. Our most significant discovery is that X3D achieves state-of-the-art performance while requiring almost seven times less memory to achieve better precision than previous work.
Towards cumulative race time regression in sports: I3D ConvNet transfer learning in ultra-distance running events
Aug 23, 2022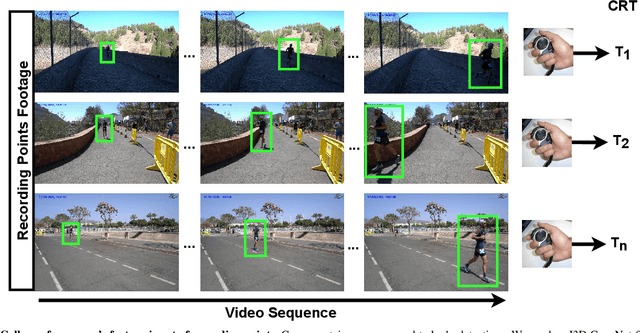


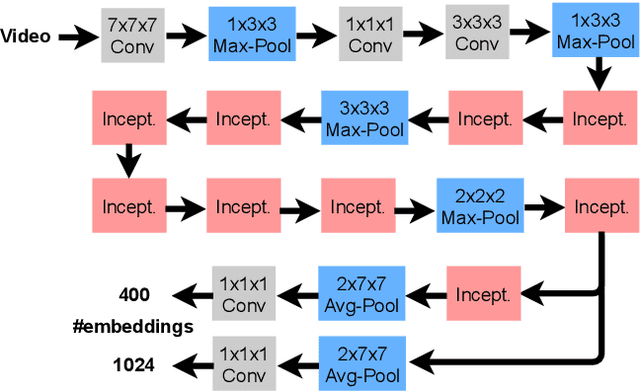
Predicting an athlete's performance based on short footage is highly challenging. Performance prediction requires high domain knowledge and enough evidence to infer an appropriate quality assessment. Sports pundits can often infer this kind of information in real-time. In this paper, we propose regressing an ultra-distance runner cumulative race time (CRT), i.e., the time the runner has been in action since the race start, by using only a few seconds of footage as input. We modified the I3D ConvNet backbone slightly and trained a newly added regressor for that purpose. We use appropriate pre-processing of the visual input to enable transfer learning from a specific runner. We show that the resulting neural network can provide a remarkable performance for short input footage: 18 minutes and a half mean absolute error in estimating the CRT for runners who have been in action from 8 to 20 hours. Our methodology has several favorable properties: it does not require a human expert to provide any insight, it can be used at any moment during the race by just observing a runner, and it can inform the race staff about a runner at any given time.
Decontextualized I3D ConvNet for ultra-distance runners performance analysis at a glance
Mar 25, 2022
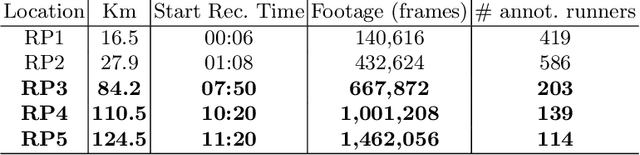

In May 2021, the site runnersworld.com published that participation in ultra-distance races has increased by 1,676% in the last 23 years. Moreover, nearly 41% of those runners participate in more than one race per year. The development of wearable devices has undoubtedly contributed to motivating participants by providing performance measures in real-time. However, we believe there is room for improvement, particularly from the organizers point of view. This work aims to determine how the runners performance can be quantified and predicted by considering a non-invasive technique focusing on the ultra-running scenario. In this sense, participants are captured when they pass through a set of locations placed along the race track. Each footage is considered an input to an I3D ConvNet to extract the participant's running gait in our work. Furthermore, weather and illumination capture conditions or occlusions may affect these footages due to the race staff and other runners. To address this challenging task, we have tracked and codified the participant's running gait at some RPs and removed the context intending to ensure a runner-of-interest proper evaluation. The evaluation suggests that the features extracted by an I3D ConvNet provide enough information to estimate the participant's performance along the different race tracks.
Deep learning for source camera identification on mobile devices
Oct 13, 2017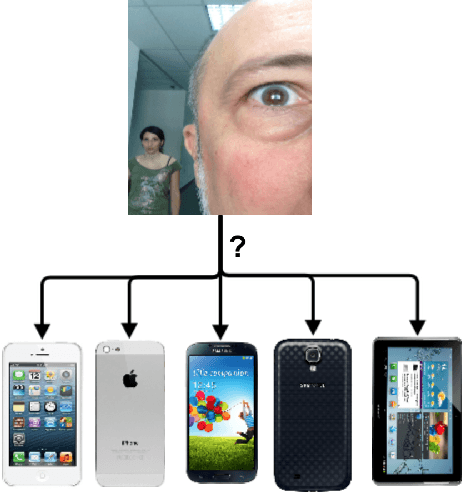

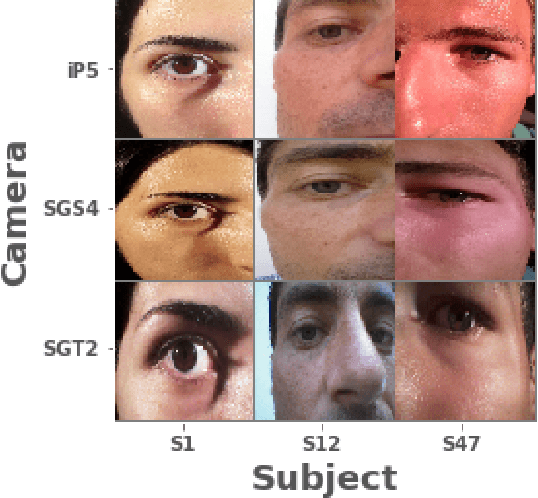
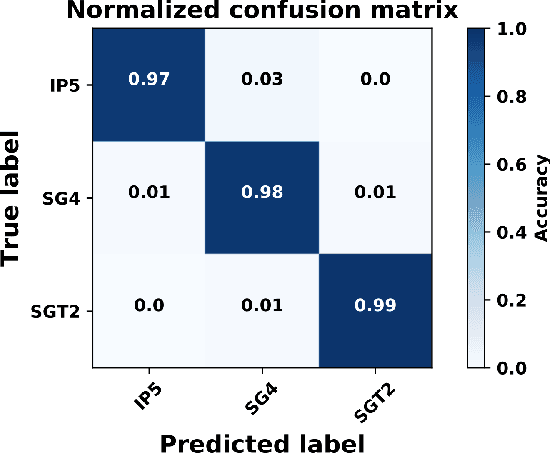
In the present paper, we propose a source camera identification method for mobile devices based on deep learning. Recently, convolutional neural networks (CNNs) have shown a remarkable performance on several tasks such as image recognition, video analysis or natural language processing. A CNN consists on a set of layers where each layer is composed by a set of high pass filters which are applied all over the input image. This convolution process provides the unique ability to extract features automatically from data and to learn from those features. Our proposal describes a CNN architecture which is able to infer the noise pattern of mobile camera sensors (also known as camera fingerprint) with the aim at detecting and identifying not only the mobile device used to capture an image (with a 98\% of accuracy), but also from which embedded camera the image was captured. More specifically, we provide an extensive analysis on the proposed architecture considering different configurations. The experiment has been carried out using the images captured from different mobile devices cameras (MICHE-I Dataset was used) and the obtained results have proved the robustness of the proposed method.
Comparative study of histogram distance measures for re-identification
Nov 24, 2016



Color based re-identification methods usually rely on a distance function to measure the similarity between individuals. In this paper we study the behavior of several histogram distance measures in different color spaces. We wonder whether there is a particular histogram distance measure better than others, likewise also, if there is a color space that present better discrimination features. Several experiments are designed and evaluated in several images to obtain measures against various color spaces. We test in several image databases. A measure ranking is generated to calculate the area under the CMC, this area is the indicator used to evaluate which distance measure and color space present the best performance for the considered databases. Also, other parameters such as the image division in horizontal stripes and number of histogram bins, have been studied.