 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering: which investigated applications?
Mar 04, 2021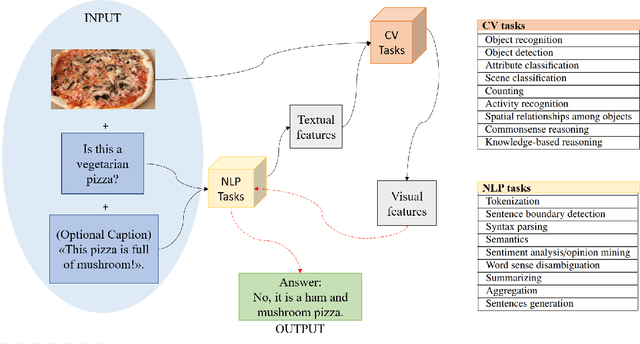
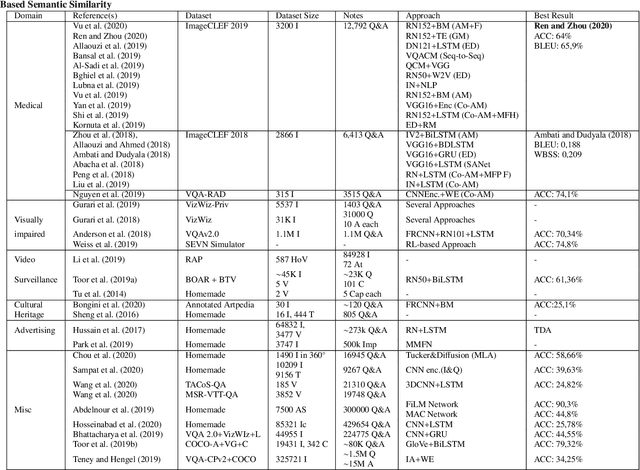

Visual Question Answering (VQA) is an extremely stimulating and challenging research area where Computer Vision (CV) and Natural Language Processig (NLP) have recently met. In image captioning and video summarization, the semantic information is completely contained in still images or video dynamics, and it has only to be mined and expressed in a human-consistent way. Differently from this, in VQA semantic information in the same media must be compared with the semantics implied by a question expressed in natural language, doubling the artificial intelligence-related effort. Some recent surveys about VQA approaches have focused on methods underlying either the image-related processing or the verbal-related one, or on the way to consistently fuse the conveyed information. Possible applications are only suggested, and, in fact, most cited works rely on general-purpose datasets that are used to assess the building blocks of a VQA system. This paper rather considers the proposals that focus on real-world applications, possibly using as benchmarks suitable data bound to the application domain. The paper also reports about some recent challenges in VQA research.
Deep learning for source camera identification on mobile devices
Oct 13, 2017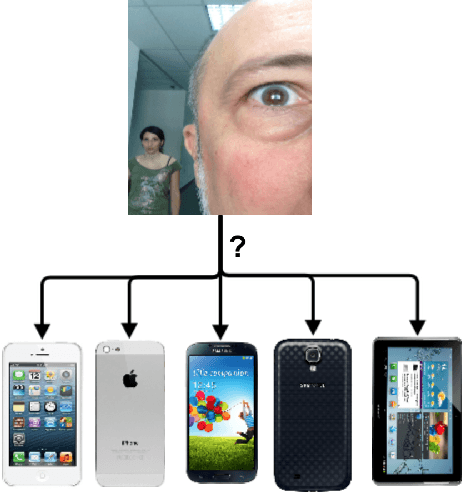

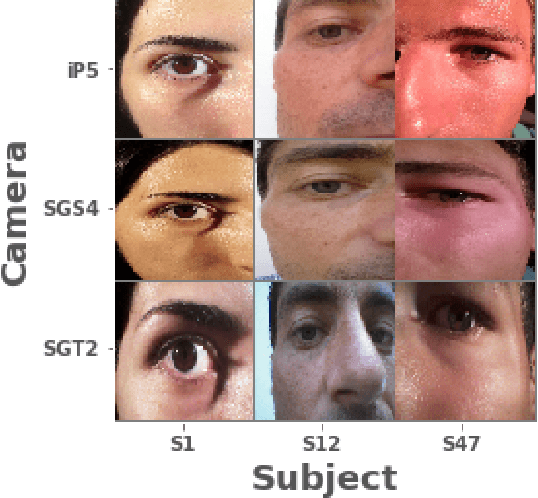
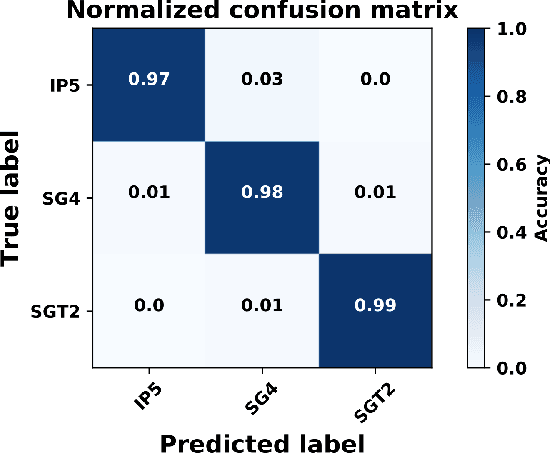
In the present paper, we propose a source camera identification method for mobile devices based on deep learning. Recently, convolutional neural networks (CNNs) have shown a remarkable performance on several tasks such as image recognition, video analysis or natural language processing. A CNN consists on a set of layers where each layer is composed by a set of high pass filters which are applied all over the input image. This convolution process provides the unique ability to extract features automatically from data and to learn from those features. Our proposal describes a CNN architecture which is able to infer the noise pattern of mobile camera sensors (also known as camera fingerprint) with the aim at detecting and identifying not only the mobile device used to capture an image (with a 98\% of accuracy), but also from which embedded camera the image was captured. More specifically, we provide an extensive analysis on the proposed architecture considering different configurations. The experiment has been carried out using the images captured from different mobile devices cameras (MICHE-I Dataset was used) and the obtained results have proved the robustness of the proposed method.