 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Work Zone Intelligence for Safety-Critical Speed Regulation of Mixed-Autonomy Vehicles in Dynamic Environments
Jun 07, 2026Temporary work-zone speed limits are communicated through visually inconsistent signage and are often missing from digital maps, creating safety risks for human drivers and automated vehicle systems. We present a real-time, onboard perception pipeline that detects active work zones, recognizes associated temporary speed limits, and outputs a law-aware work-zone state and speed value suitable for driver alerts or downstream automated control. The system fuses object detections with semantic verification and temporally smoothed, hysteresis-based state transitions to reduce false activations and flicker in dynamic scenes, and runs fully on low-cost embedded hardware. Evaluated manually on a annotated subset of the ROADWork dataset (490 sequences), the system achieves inside-work-zone event-level recall of 96.5% and event-level precision of 68.7%. Speed-limit recognition evaluated on 35 minutes of in-house driving data attains 95.45% precision and 53.85% recall, with no incorrect speed classifications and a single false positive. These results demonstrate a practical, scalable approach for grounding work-zone speed awareness directly in onboard perception rather than maps or infrastructure. We release our source code for the proposed system pipeline on our GitHub repository: https://github.com/Mi3-Lab/workzone
Looking and Listening Inside and Outside: Multimodal Artificial Intelligence Systems for Driver Safety Assessment and Intelligent Vehicle Decision-Making
Feb 07, 2026The looking-in-looking-out (LILO) framework has enabled intelligent vehicle applications that understand both the outside scene and the driver state to improve safety outcomes, with examples in smart airbag deployment, takeover time prediction in autonomous control transitions, and driver attention monitoring. In this research, we propose an augmentation to this framework, making a case for the audio modality as an additional source of information to understand the driver, and in the evolving autonomy landscape, also the passengers and those outside the vehicle. We expand LILO by incorporating audio signals, forming the looking-and-listening inside-and-outside (L-LIO) framework to enhance driver state assessment and environment understanding through multimodal sensor fusion. We evaluate three example cases where audio enhances vehicle safety: supervised learning on driver speech audio to classify potential impairment states (e.g., intoxication), collection and analysis of passenger natural language instructions (e.g., "turn after that red building") to motivate how spoken language can interface with planning systems through audio-aligned instruction data, and limitations of vision-only systems where audio may disambiguate the guidance and gestures of external agents. Datasets include custom-collected in-vehicle and external audio samples in real-world environments. Pilot findings show that audio yields safety-relevant insights, particularly in nuanced or context-rich scenarios where sound is critical to safe decision-making or visual signals alone are insufficient. Challenges include ambient noise interference, privacy considerations, and robustness across human subjects, motivating further work on reliability in dynamic real-world contexts. L-LIO augments driver and scene understanding through multimodal fusion of audio and visual sensing, offering new paths for safety intervention.
Vision and language: Novel Representations and Artificial intelligence for Driving Scene Safety Assessment and Autonomous Vehicle Planning
Feb 07, 2026Vision-language models (VLMs) have recently emerged as powerful representation learning systems that align visual observations with natural language concepts, offering new opportunities for semantic reasoning in safety-critical autonomous driving. This paper investigates how vision-language representations support driving scene safety assessment and decision-making when integrated into perception, prediction, and planning pipelines. We study three complementary system-level use cases. First, we introduce a lightweight, category-agnostic hazard screening approach leveraging CLIP-based image-text similarity to produce a low-latency semantic hazard signal. This enables robust detection of diverse and out-of-distribution road hazards without explicit object detection or visual question answering. Second, we examine the integration of scene-level vision-language embeddings into a transformer-based trajectory planning framework using the Waymo Open Dataset. Our results show that naively conditioning planners on global embeddings does not improve trajectory accuracy, highlighting the importance of representation-task alignment and motivating the development of task-informed extraction methods for safety-critical planning. Third, we investigate natural language as an explicit behavioral constraint on motion planning using the doScenes dataset. In this setting, passenger-style instructions grounded in visual scene elements suppress rare but severe planning failures and improve safety-aligned behavior in ambiguous scenarios. Taken together, these findings demonstrate that vision-language representations hold significant promise for autonomous driving safety when used to express semantic risk, intent, and behavioral constraints. Realizing this potential is fundamentally an engineering problem requiring careful system design and structured grounding rather than direct feature injection.
Natural Language Instructions for Scene-Responsive Human-in-the-Loop Motion Planning in Autonomous Driving using Vision-Language-Action Models
Feb 04, 2026Instruction-grounded driving, where passenger language guides trajectory planning, requires vehicles to understand intent before motion. However, most prior instruction-following planners rely on simulation or fixed command vocabularies, limiting real-world generalization. doScenes, the first real-world dataset linking free-form instructions (with referentiality) to nuScenes ground-truth motion, enables instruction-conditioned planning. In this work, we adapt OpenEMMA, an open-source MLLM-based end-to-end driving framework that ingests front-camera views and ego-state and outputs 10-step speed-curvature trajectories, to this setting, presenting a reproducible instruction-conditioned baseline on doScenes and investigate the effects of human instruction prompts on predicted driving behavior. We integrate doScenes directives as passenger-style prompts within OpenEMMA's vision-language interface, enabling linguistic conditioning before trajectory generation. Evaluated on 849 annotated scenes using ADE, we observe that instruction conditioning substantially improves robustness by preventing extreme baseline failures, yielding a 98.7% reduction in mean ADE. When such outliers are removed, instructions still influence trajectory alignment, with well-phrased prompts improving ADE by up to 5.1%. We use this analysis to discuss what makes a "good" instruction for the OpenEMMA framework. We release the evaluation prompts and scripts to establish a reproducible baseline for instruction-aware planning. GitHub: https://github.com/Mi3-Lab/doScenes-VLM-Planning
SMc2f: Robust Scenario Mining for Robotic Autonomy from Coarse to Fine
Jan 17, 2026The safety validation of autonomous robotic vehicles hinges on systematically testing their planning and control stacks against rare, safety-critical scenarios. Mining these long-tail events from massive real-world driving logs is therefore a critical step in the robotic development lifecycle. The goal of the Scenario Mining task is to retrieve useful information to enable targeted re-simulation, regression testing, and failure analysis of the robot's decision-making algorithms. RefAV, introduced by the Argoverse team, is an end-to-end framework that uses large language models (LLMs) to spatially and temporally localize scenarios described in natural language. However, this process performs retrieval on trajectory labels, ignoring the direct connection between natural language and raw RGB images, which runs counter to the intuition of video retrieval; it also depends on the quality of upstream 3D object detection and tracking. Further, inaccuracies in trajectory data lead to inaccuracies in downstream spatial and temporal localization. To address these issues, we propose Robust Scenario Mining for Robotic Autonomy from Coarse to Fine (SMc2f), a coarse-to-fine pipeline that employs vision-language models (VLMs) for coarse image-text filtering, builds a database of successful mining cases on top of RefAV and automatically retrieves exemplars to few-shot condition the LLM for more robust retrieval, and introduces text-trajectory contrastive learning to pull matched pairs together and push mismatched pairs apart in a shared embedding space, yielding a fine-grained matcher that refines the LLM's candidate trajectories. Experiments on public datasets demonstrate substantial gains in both retrieval quality and efficiency.
DepthVision: Robust Vision-Language Understanding through GAN-Based LiDAR-to-RGB Synthesis
Sep 09, 2025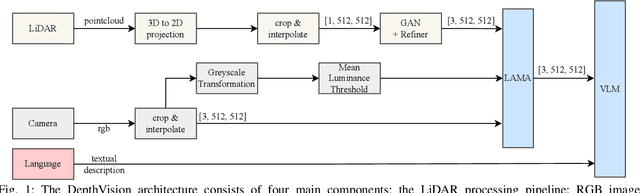
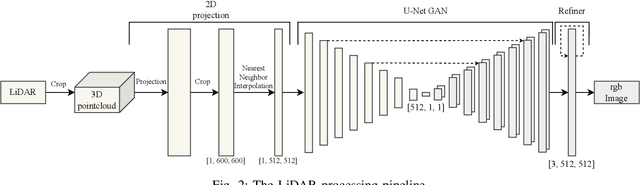
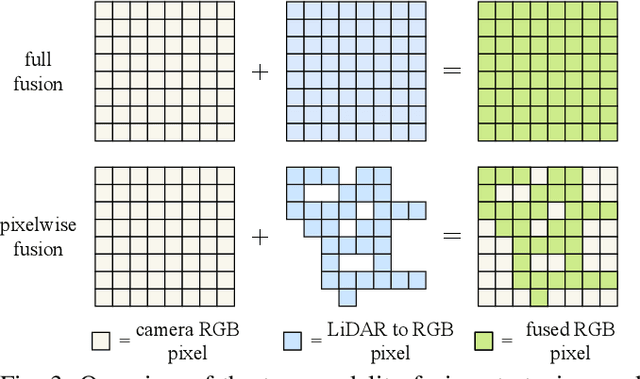
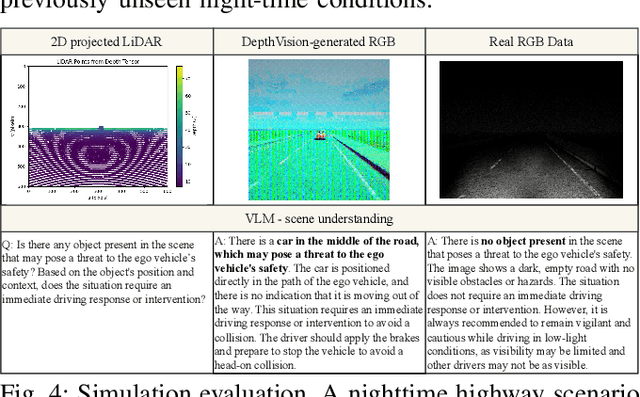
Ensuring reliable robot operation when visual input is degraded or insufficient remains a central challenge in robotics. This letter introduces DepthVision, a framework for multimodal scene understanding designed to address this problem. Unlike existing Vision-Language Models (VLMs), which use only camera-based visual input alongside language, DepthVision synthesizes RGB images from sparse LiDAR point clouds using a conditional generative adversarial network (GAN) with an integrated refiner network. These synthetic views are then combined with real RGB data using a Luminance-Aware Modality Adaptation (LAMA), which blends the two types of data dynamically based on ambient lighting conditions. This approach compensates for sensor degradation, such as darkness or motion blur, without requiring any fine-tuning of downstream vision-language models. We evaluate DepthVision on real and simulated datasets across various models and tasks, with particular attention to safety-critical tasks. The results demonstrate that our approach improves performance in low-light conditions, achieving substantial gains over RGB-only baselines while preserving compatibility with frozen VLMs. This work highlights the potential of LiDAR-guided RGB synthesis for achieving robust robot operation in real-world environments.
Safety-Critical Learning for Long-Tail Events: The TUM Traffic Accident Dataset
Aug 20, 2025Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as an unavoidable and sporadic outcome of traffic networks. We present the TUM Traffic Accident (TUMTraf-A) dataset, a collection of real-world highway accidents. It contains ten sequences of vehicle crashes at high-speed driving with 294,924 labeled 2D and 93,012 labeled 3D boxes and track IDs within 48,144 labeled frames recorded from four roadside cameras and LiDARs at 10 Hz. The dataset contains ten object classes and is provided in the OpenLABEL format. We propose Accid3nD, an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our project website: https://tum-traffic-dataset.github.io/tumtraf-a.
Words as Geometric Features: Estimating Homography using Optical Character Recognition as Compressed Image Representation
May 25, 2025



Document alignment and registration play a crucial role in numerous real-world applications, such as automated form processing, anomaly detection, and workflow automation. Traditional methods for document alignment rely on image-based features like keypoints, edges, and textures to estimate geometric transformations, such as homographies. However, these approaches often require access to the original document images, which may not always be available due to privacy, storage, or transmission constraints. This paper introduces a novel approach that leverages Optical Character Recognition (OCR) outputs as features for homography estimation. By utilizing the spatial positions and textual content of OCR-detected words, our method enables document alignment without relying on pixel-level image data. This technique is particularly valuable in scenarios where only OCR outputs are accessible. Furthermore, the method is robust to OCR noise, incorporating RANSAC to handle outliers and inaccuracies in the OCR data. On a set of test documents, we demonstrate that our OCR-based approach even performs more accurately than traditional image-based methods, offering a more efficient and scalable solution for document registration tasks. The proposed method facilitates applications in document processing, all while reducing reliance on high-dimensional image data.
Beyond General Prompts: Automated Prompt Refinement using Contrastive Class Alignment Scores for Disambiguating Objects in Vision-Language Models
May 14, 2025



Vision-language models (VLMs) offer flexible object detection through natural language prompts but suffer from performance variability depending on prompt phrasing. In this paper, we introduce a method for automated prompt refinement using a novel metric called the Contrastive Class Alignment Score (CCAS), which ranks prompts based on their semantic alignment with a target object class while penalizing similarity to confounding classes. Our method generates diverse prompt candidates via a large language model and filters them through CCAS, computed using prompt embeddings from a sentence transformer. We evaluate our approach on challenging object categories, demonstrating that our automatic selection of high-precision prompts improves object detection accuracy without the need for additional model training or labeled data. This scalable and model-agnostic pipeline offers a principled alternative to manual prompt engineering for VLM-based detection systems.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.