 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeceLLMate: Sandboxing Browser AI Agents
Dec 14, 2025Browser-using agents (BUAs) are an emerging class of autonomous agents that interact with web browsers in human-like ways, including clicking, scrolling, filling forms, and navigating across pages. While these agents help automate repetitive online tasks, they are vulnerable to prompt injection attacks that can trick an agent into performing undesired actions, such as leaking private information or issuing state-changing requests. We propose ceLLMate, a browser-level sandboxing framework that restricts the agent's ambient authority and reduces the blast radius of prompt injections. We address two fundamental challenges: (1) The semantic gap challenge in policy enforcement arises because the agent operates through low-level UI observations and manipulations; however, writing and enforcing policies directly over UI-level events is brittle and error-prone. To address this challenge, we introduce an agent sitemap that maps low-level browser behaviors to high-level semantic actions. (2) Policy prediction in BUAs is the norm rather than the exception. BUAs have no app developer to pre-declare sandboxing policies, and thus, ceLLMate pairs website-authored mandatory policies with an automated policy-prediction layer that adapts and instantiates these policies from the user's natural-language task. We implement ceLLMate as an agent-agnostic browser extension and demonstrate how it enables sandboxing policies that effectively block various types of prompt injection attacks with negligible overhead.
May I have your Attention? Breaking Fine-Tuning based Prompt Injection Defenses using Architecture-Aware Attacks
Jul 10, 2025



A popular class of defenses against prompt injection attacks on large language models (LLMs) relies on fine-tuning the model to separate instructions and data, so that the LLM does not follow instructions that might be present with data. There are several academic systems and production-level implementations of this idea. We evaluate the robustness of this class of prompt injection defenses in the whitebox setting by constructing strong optimization-based attacks and showing that the defenses do not provide the claimed security properties. Specifically, we construct a novel attention-based attack algorithm for text-based LLMs and apply it to two recent whitebox defenses SecAlign (CCS 2025) and StruQ (USENIX Security 2025), showing attacks with success rates of up to 70% with modest increase in attacker budget in terms of tokens. Our findings make fundamental progress towards understanding the robustness of prompt injection defenses in the whitebox setting. We release our code and attacks at https://github.com/nishitvp/better_opts_attacks
Words as Geometric Features: Estimating Homography using Optical Character Recognition as Compressed Image Representation
May 25, 2025



Document alignment and registration play a crucial role in numerous real-world applications, such as automated form processing, anomaly detection, and workflow automation. Traditional methods for document alignment rely on image-based features like keypoints, edges, and textures to estimate geometric transformations, such as homographies. However, these approaches often require access to the original document images, which may not always be available due to privacy, storage, or transmission constraints. This paper introduces a novel approach that leverages Optical Character Recognition (OCR) outputs as features for homography estimation. By utilizing the spatial positions and textual content of OCR-detected words, our method enables document alignment without relying on pixel-level image data. This technique is particularly valuable in scenarios where only OCR outputs are accessible. Furthermore, the method is robust to OCR noise, incorporating RANSAC to handle outliers and inaccuracies in the OCR data. On a set of test documents, we demonstrate that our OCR-based approach even performs more accurately than traditional image-based methods, offering a more efficient and scalable solution for document registration tasks. The proposed method facilitates applications in document processing, all while reducing reliance on high-dimensional image data.
Misusing Tools in Large Language Models With Visual Adversarial Examples
Oct 04, 2023



Large Language Models (LLMs) are being enhanced with the ability to use tools and to process multiple modalities. These new capabilities bring new benefits and also new security risks. In this work, we show that an attacker can use visual adversarial examples to cause attacker-desired tool usage. For example, the attacker could cause a victim LLM to delete calendar events, leak private conversations and book hotels. Different from prior work, our attacks can affect the confidentiality and integrity of user resources connected to the LLM while being stealthy and generalizable to multiple input prompts. We construct these attacks using gradient-based adversarial training and characterize performance along multiple dimensions. We find that our adversarial images can manipulate the LLM to invoke tools following real-world syntax almost always (~98%) while maintaining high similarity to clean images (~0.9 SSIM). Furthermore, using human scoring and automated metrics, we find that the attacks do not noticeably affect the conversation (and its semantics) between the user and the LLM.
SkillFence: A Systems Approach to Practically Mitigating Voice-Based Confusion Attacks
Dec 16, 2022



Voice assistants are deployed widely and provide useful functionality. However, recent work has shown that commercial systems like Amazon Alexa and Google Home are vulnerable to voice-based confusion attacks that exploit design issues. We propose a systems-oriented defense against this class of attacks and demonstrate its functionality for Amazon Alexa. We ensure that only the skills a user intends execute in response to voice commands. Our key insight is that we can interpret a user's intentions by analyzing their activity on counterpart systems of the web and smartphones. For example, the Lyft ride-sharing Alexa skill has an Android app and a website. Our work shows how information from counterpart apps can help reduce dis-ambiguities in the skill invocation process. We build SkilIFence, a browser extension that existing voice assistant users can install to ensure that only legitimate skills run in response to their commands. Using real user data from MTurk (N = 116) and experimental trials involving synthetic and organic speech, we show that SkillFence provides a balance between usability and security by securing 90.83% of skills that a user will need with a False acceptance rate of 19.83%.
Re-purposing Perceptual Hashing based Client Side Scanning for Physical Surveillance
Dec 08, 2022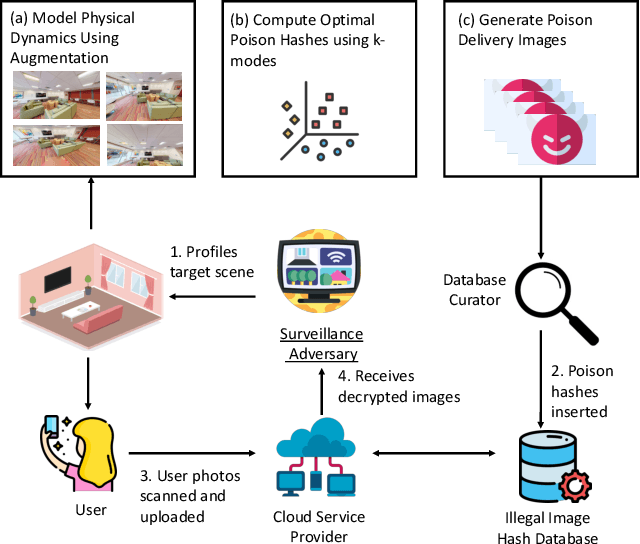



Content scanning systems employ perceptual hashing algorithms to scan user content for illegal material, such as child pornography or terrorist recruitment flyers. Perceptual hashing algorithms help determine whether two images are visually similar while preserving the privacy of the input images. Several efforts from industry and academia propose to conduct content scanning on client devices such as smartphones due to the impending roll out of end-to-end encryption that will make server-side content scanning difficult. However, these proposals have met with strong criticism because of the potential for the technology to be misused and re-purposed. Our work informs this conversation by experimentally characterizing the potential for one type of misuse -- attackers manipulating the content scanning system to perform physical surveillance on target locations. Our contributions are threefold: (1) we offer a definition of physical surveillance in the context of client-side image scanning systems; (2) we experimentally characterize this risk and create a surveillance algorithm that achieves physical surveillance rates of >40% by poisoning 5% of the perceptual hash database; (3) we experimentally study the trade-off between the robustness of client-side image scanning systems and surveillance, showing that more robust detection of illegal material leads to increased potential for physical surveillance.
Exploring Adversarial Robustness of Deep Metric Learning
Feb 14, 2021
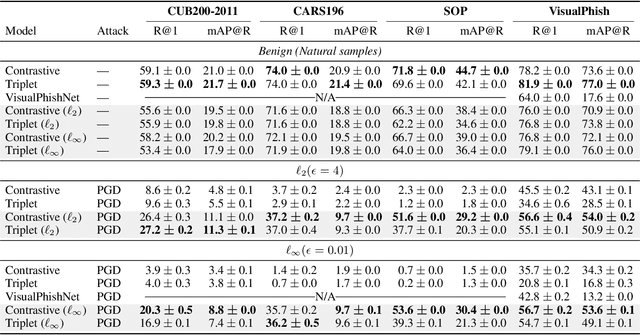

Deep Metric Learning (DML), a widely-used technique, involves learning a distance metric between pairs of samples. DML uses deep neural architectures to learn semantic embeddings of the input, where the distance between similar examples is small while dissimilar ones are far apart. Although the underlying neural networks produce good accuracy on naturally occurring samples, they are vulnerable to adversarially-perturbed samples that reduce performance. We take a first step towards training robust DML models and tackle the primary challenge of the metric losses being dependent on the samples in a mini-batch, unlike standard losses that only depend on the specific input-output pair. We analyze this dependence effect and contribute a robust optimization formulation. Using experiments on three commonly-used DML datasets, we demonstrate 5-76 fold increases in adversarial accuracy, and outperform an existing DML model that sought out to be robust.
Sequential Attacks on Kalman Filter-based Forward Collision Warning Systems
Dec 16, 2020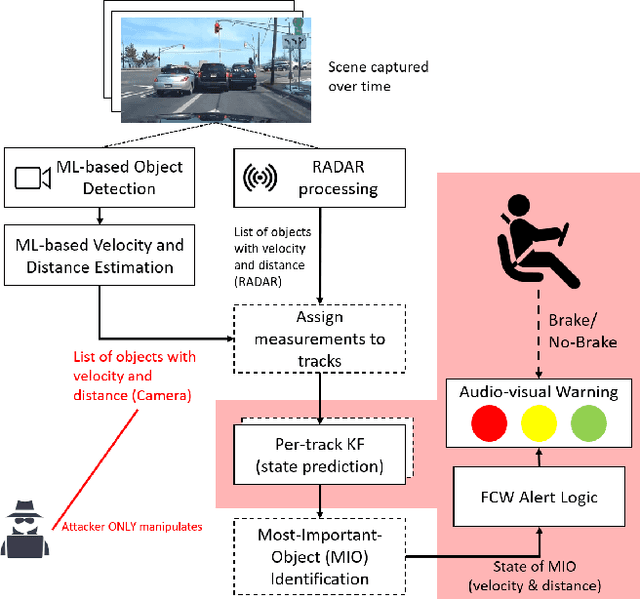
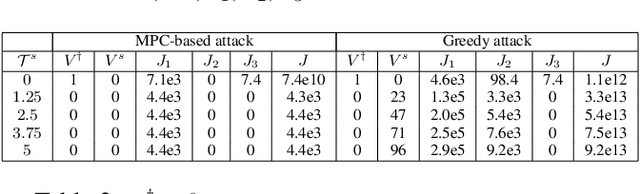

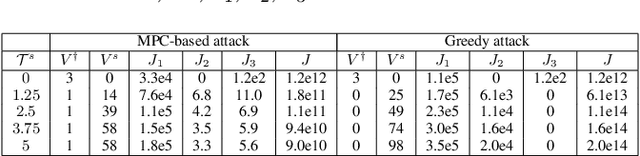
Kalman Filter (KF) is widely used in various domains to perform sequential learning or variable estimation. In the context of autonomous vehicles, KF constitutes the core component of many Advanced Driver Assistance Systems (ADAS), such as Forward Collision Warning (FCW). It tracks the states (distance, velocity etc.) of relevant traffic objects based on sensor measurements. The tracking output of KF is often fed into downstream logic to produce alerts, which will then be used by human drivers to make driving decisions in near-collision scenarios. In this paper, we study adversarial attacks on KF as part of the more complex machine-human hybrid system of Forward Collision Warning. Our attack goal is to negatively affect human braking decisions by causing KF to output incorrect state estimations that lead to false or delayed alerts. We accomplish this by sequentially manipulating measure ments fed into the KF, and propose a novel Model Predictive Control (MPC) approach to compute the optimal manipulation. Via experiments conducted in a simulated driving environment, we show that the attacker is able to successfully change FCW alert signals through planned manipulation over measurements prior to the desired target time. These results demonstrate that our attack can stealthily mislead a distracted human driver and cause vehicle collisions.
Invisible Perturbations: Physical Adversarial Examples Exploiting the Rolling Shutter Effect
Nov 30, 2020
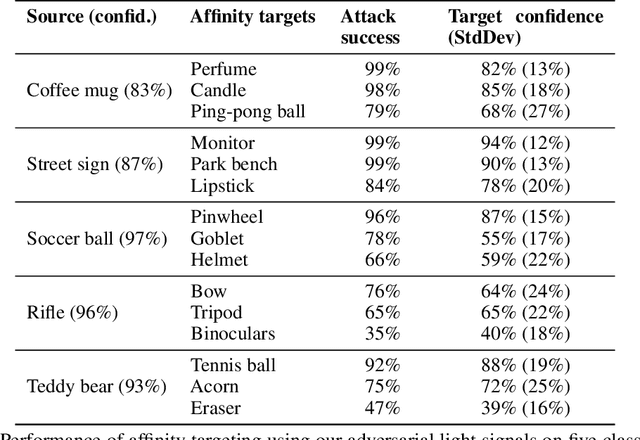
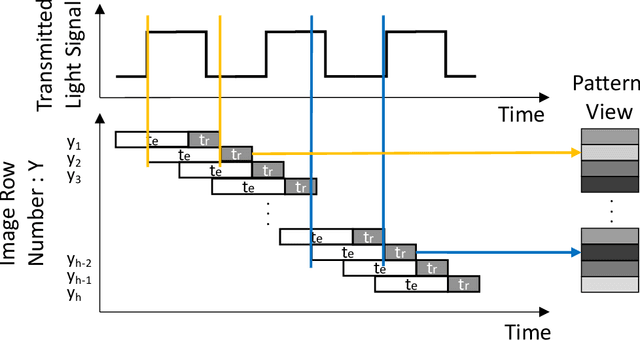
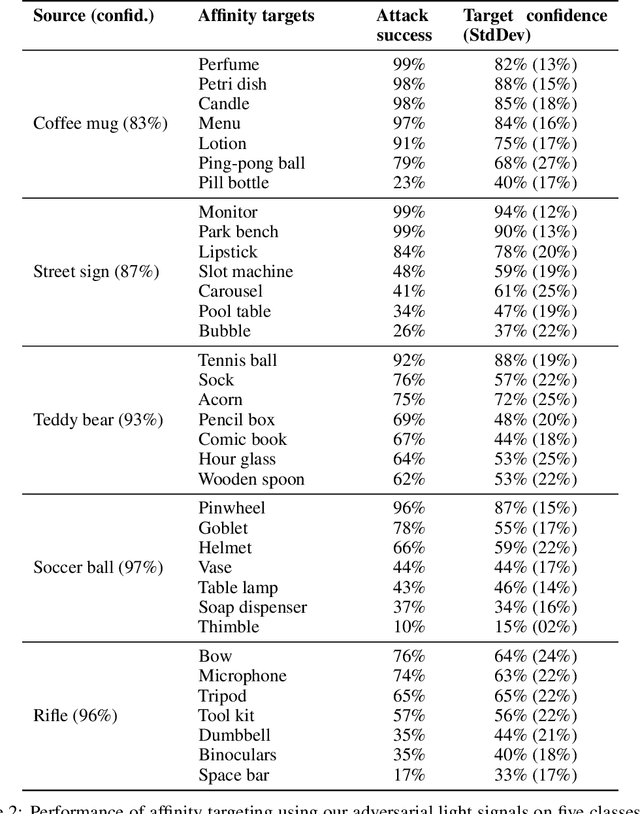
Physical adversarial examples for camera-based computer vision have so far been achieved through visible artifacts -- a sticker on a Stop sign, colorful borders around eyeglasses or a 3D printed object with a colorful texture. An implicit assumption here is that the perturbations must be visible so that a camera can sense them. By contrast, we contribute a procedure to generate, for the first time, physical adversarial examples that are invisible to human eyes. Rather than modifying the victim object with visible artifacts, we modify light that illuminates the object. We demonstrate how an attacker can craft a modulated light signal that adversarially illuminates a scene and causes targeted misclassifications on a state-of-the-art ImageNet deep learning model. Concretely, we exploit the radiometric rolling shutter effect in commodity cameras to create precise striping patterns that appear on images. To human eyes, it appears like the object is illuminated, but the camera creates an image with stripes that will cause ML models to output the attacker-desired classification. We conduct a range of simulation and physical experiments with LEDs, demonstrating targeted attack rates up to 84%.
Query-Efficient Physical Hard-Label Attacks on Deep Learning Visual Classification
Feb 17, 2020
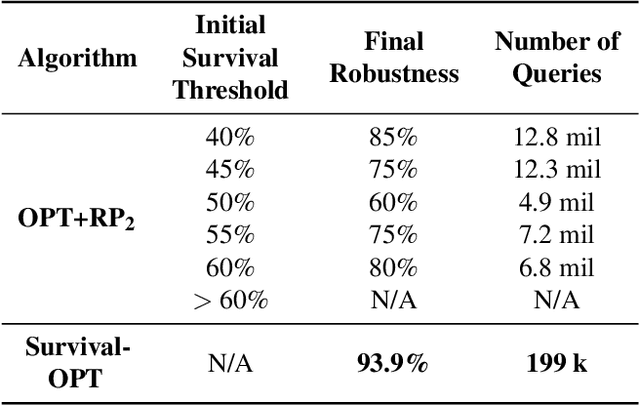

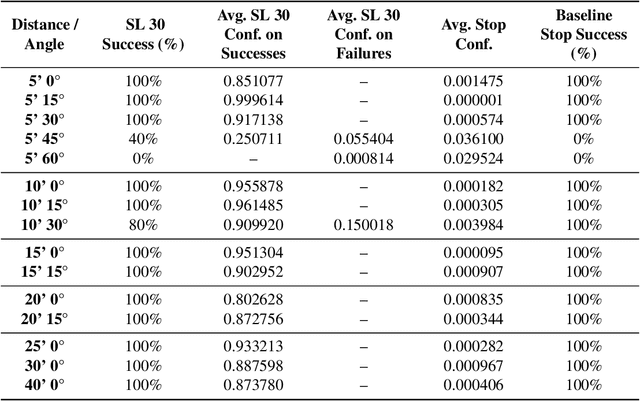
We present Survival-OPT, a physical adversarial example algorithm in the black-box hard-label setting where the attacker only has access to the model prediction class label. Assuming such limited access to the model is more relevant for settings such as proprietary cyber-physical and cloud systems than the whitebox setting assumed by prior work. By leveraging the properties of physical attacks, we create a novel approach based on the survivability of perturbations corresponding to physical transformations. Through simply querying the model for hard-label predictions, we optimize perturbations to survive in many different physical conditions and show that adversarial examples remain a security risk to cyber-physical systems (CPSs) even in the hard-label threat model. We show that Survival-OPT is query-efficient and robust: using fewer than 200K queries, we successfully attack a stop sign to be misclassified as a speed limit 30 km/hr sign in 98.5% of video frames in a drive-by setting. Survival-OPT also outperforms our baseline combination of existing hard-label and physical approaches, which required over 10x more queries for less robust results.