 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving the Safety and Security of the End-to-End AV Pipeline
Sep 05, 2024
In the current landscape of autonomous vehicle (AV) safety and security research, there are multiple isolated problems being tackled by the community at large. Due to the lack of common evaluation criteria, several important research questions are at odds with one another. For instance, while much research has been conducted on physical attacks deceiving AV perception systems, there is often inadequate investigations on working defenses and on the downstream effects of safe vehicle control. This paper provides a thorough description of the current state of AV safety and security research. We provide individual sections for the primary research questions that concern this research area, including AV surveillance, sensor system reliability, security of the AV stack, algorithmic robustness, and safe environment interaction. We wrap up the paper with a discussion of the issues that concern the interactions of these separate problems. At the conclusion of each section, we propose future research questions that still lack conclusive answers. This position article will serve as an entry point to novice and veteran researchers seeking to partake in this research domain.
Theoretically Principled Trade-off for Stateful Defenses against Query-Based Black-Box Attacks
Jul 30, 2023Adversarial examples threaten the integrity of machine learning systems with alarming success rates even under constrained black-box conditions. Stateful defenses have emerged as an effective countermeasure, detecting potential attacks by maintaining a buffer of recent queries and detecting new queries that are too similar. However, these defenses fundamentally pose a trade-off between attack detection and false positive rates, and this trade-off is typically optimized by hand-picking feature extractors and similarity thresholds that empirically work well. There is little current understanding as to the formal limits of this trade-off and the exact properties of the feature extractors/underlying problem domain that influence it. This work aims to address this gap by offering a theoretical characterization of the trade-off between detection and false positive rates for stateful defenses. We provide upper bounds for detection rates of a general class of feature extractors and analyze the impact of this trade-off on the convergence of black-box attacks. We then support our theoretical findings with empirical evaluations across multiple datasets and stateful defenses.
Investigating Stateful Defenses Against Black-Box Adversarial Examples
Mar 17, 2023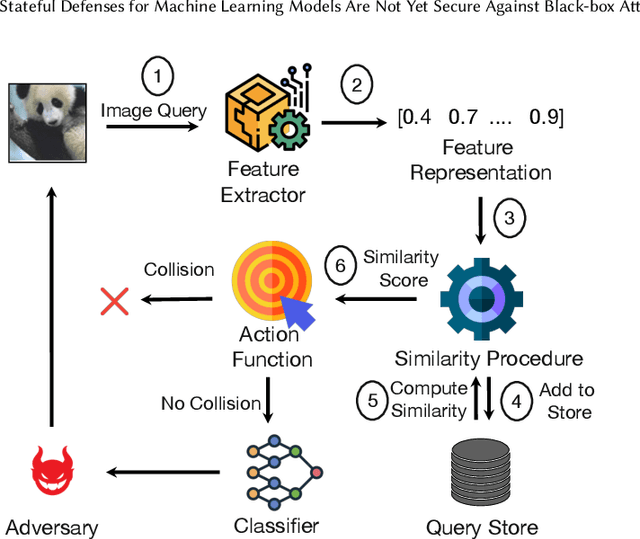

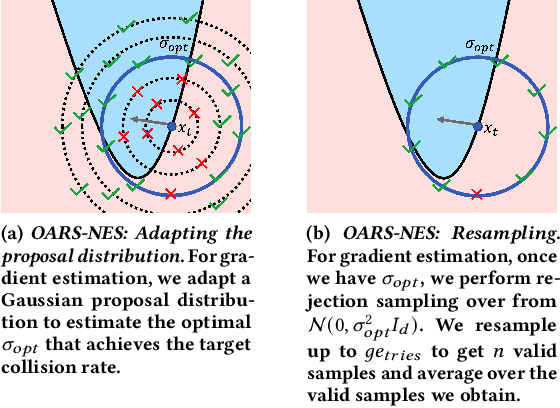
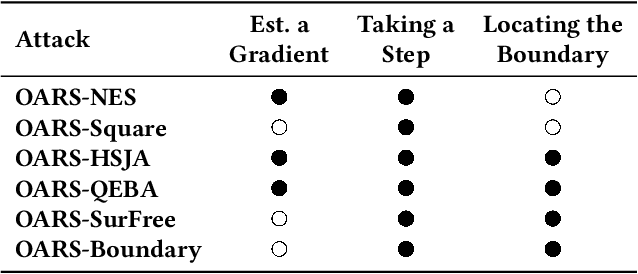
Defending machine-learning (ML) models against white-box adversarial attacks has proven to be extremely difficult. Instead, recent work has proposed stateful defenses in an attempt to defend against a more restricted black-box attacker. These defenses operate by tracking a history of incoming model queries, and rejecting those that are suspiciously similar. The current state-of-the-art stateful defense Blacklight was proposed at USENIX Security '22 and claims to prevent nearly 100% of attacks on both the CIFAR10 and ImageNet datasets. In this paper, we observe that an attacker can significantly reduce the accuracy of a Blacklight-protected classifier (e.g., from 82.2% to 6.4% on CIFAR10) by simply adjusting the parameters of an existing black-box attack. Motivated by this surprising observation, since existing attacks were evaluated by the Blacklight authors, we provide a systematization of stateful defenses to understand why existing stateful defense models fail. Finally, we propose a stronger evaluation strategy for stateful defenses comprised of adaptive score and hard-label based black-box attacks. We use these attacks to successfully reduce even reconfigured versions of Blacklight to as low as 0% robust accuracy.
Constraining the Attack Space of Machine Learning Models with Distribution Clamping Preprocessing
May 18, 2022
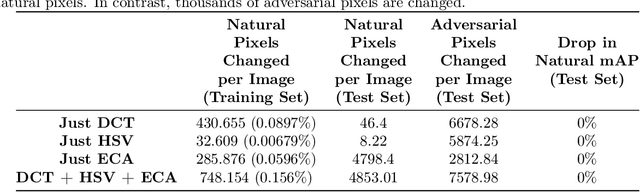
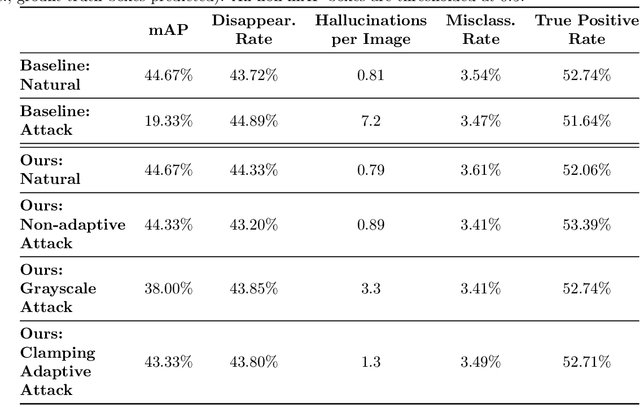
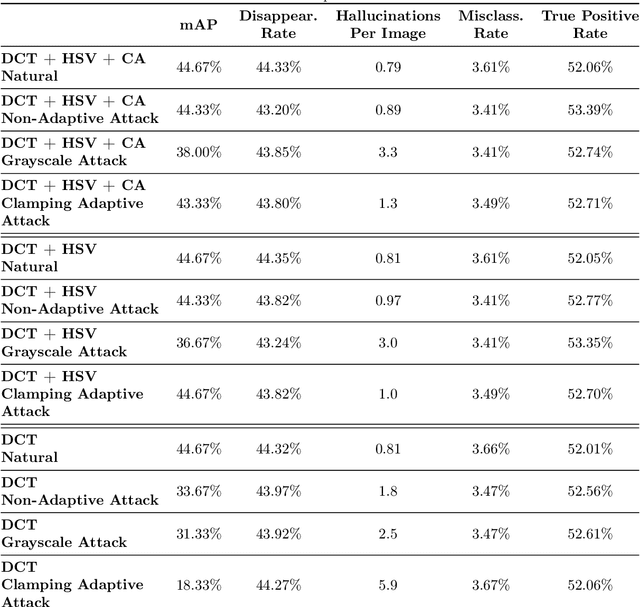
Preprocessing and outlier detection techniques have both been applied to neural networks to increase robustness with varying degrees of success. In this paper, we formalize the ideal preprocessor function as one that would take any input and set it to the nearest in-distribution input. In other words, we detect any anomalous pixels and set them such that the new input is in-distribution. We then illustrate a relaxed solution to this problem in the context of patch attacks. Specifically, we demonstrate that we can model constraints on the patch attack that specify regions as out of distribution. With these constraints, we are able to preprocess inputs successfully, increasing robustness on CARLA object detection.
Concept-based Explanations for Out-Of-Distribution Detectors
Mar 04, 2022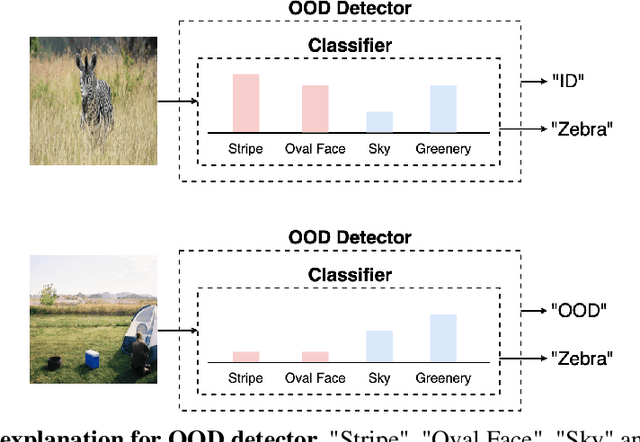
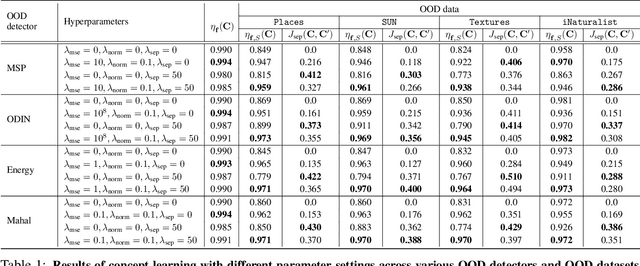
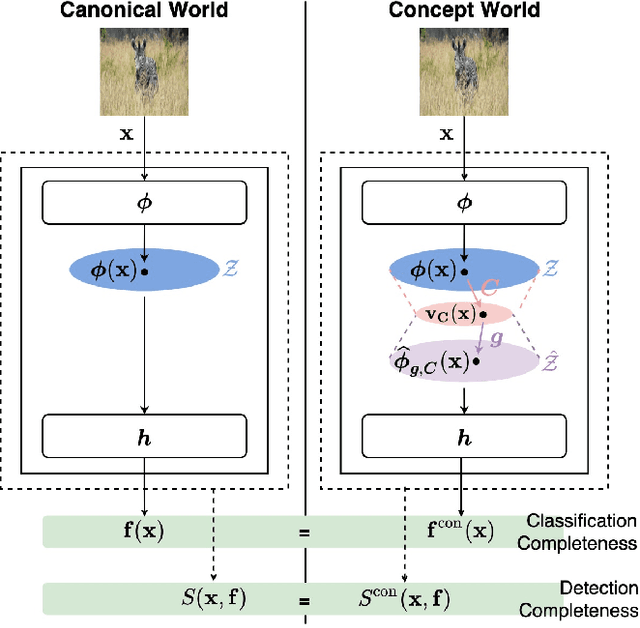
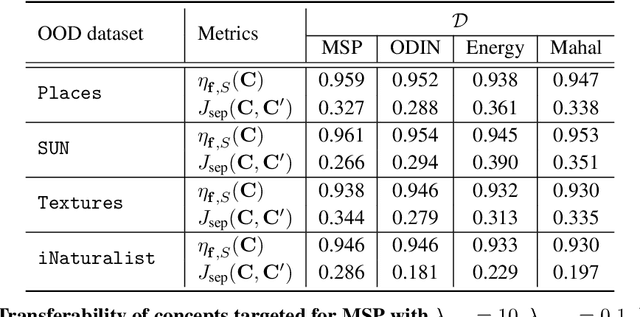
Out-of-distribution (OOD) detection plays a crucial role in ensuring the safe deployment of deep neural network (DNN) classifiers. While a myriad of methods have focused on improving the performance of OOD detectors, a critical gap remains in interpreting their decisions. We help bridge this gap by providing explanations for OOD detectors based on learned high-level concepts. We first propose two new metrics for assessing the effectiveness of a particular set of concepts for explaining OOD detectors: 1) detection completeness, which quantifies the sufficiency of concepts for explaining an OOD-detector's decisions, and 2) concept separability, which captures the distributional separation between in-distribution and OOD data in the concept space. Based on these metrics, we propose a framework for learning a set of concepts that satisfy the desired properties of detection completeness and concept separability and demonstrate the framework's effectiveness in providing concept-based explanations for diverse OOD techniques. We also show how to identify prominent concepts that contribute to the detection results via a modified Shapley value-based importance score.
Towards Adversarially Robust Deepfake Detection: An Ensemble Approach
Feb 11, 2022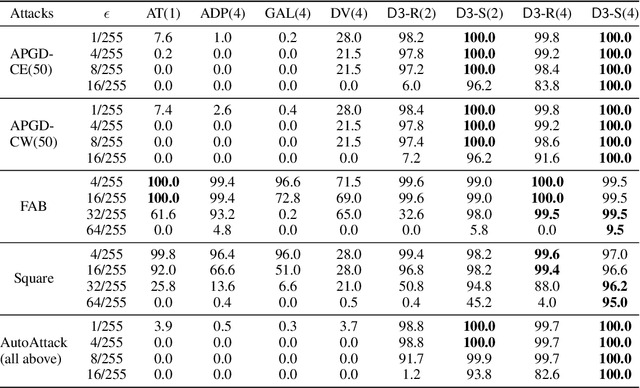
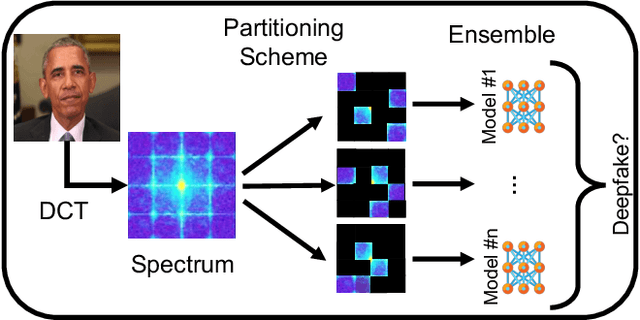
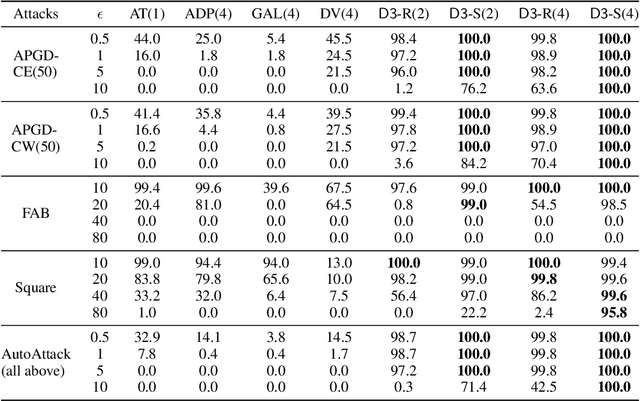
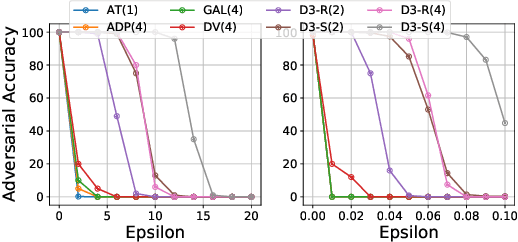
Detecting deepfakes is an important problem, but recent work has shown that DNN-based deepfake detectors are brittle against adversarial deepfakes, in which an adversary adds imperceptible perturbations to a deepfake to evade detection. In this work, we show that a modification to the detection strategy in which we replace a single classifier with a carefully chosen ensemble, in which input transformations for each model in the ensemble induces pairwise orthogonal gradients, can significantly improve robustness beyond the de facto solution of adversarial training. We present theoretical results to show that such orthogonal gradients can help thwart a first-order adversary by reducing the dimensionality of the input subspace in which adversarial deepfakes lie. We validate the results empirically by instantiating and evaluating a randomized version of such "orthogonal" ensembles for adversarial deepfake detection and find that these randomized ensembles exhibit significantly higher robustness as deepfake detectors compared to state-of-the-art deepfake detectors against adversarial deepfakes, even those created using strong PGD-500 attacks.
Using Anomaly Feature Vectors for Detecting, Classifying and Warning of Outlier Adversarial Examples
Jul 01, 2021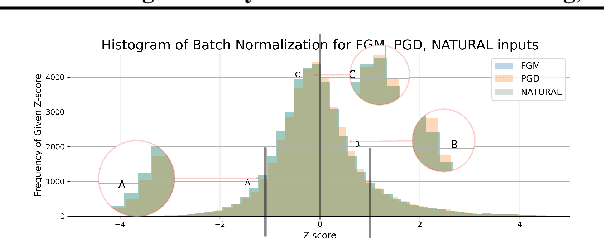
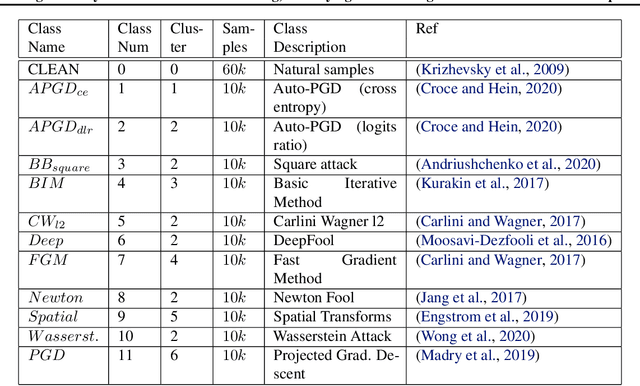
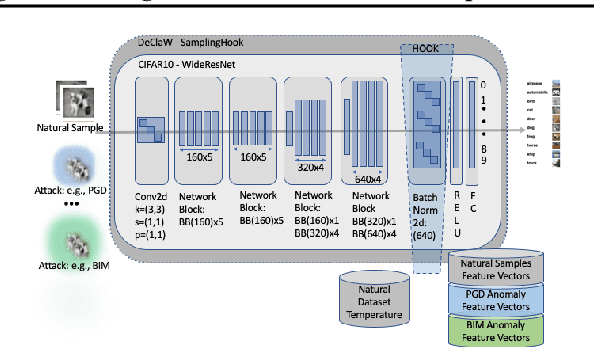
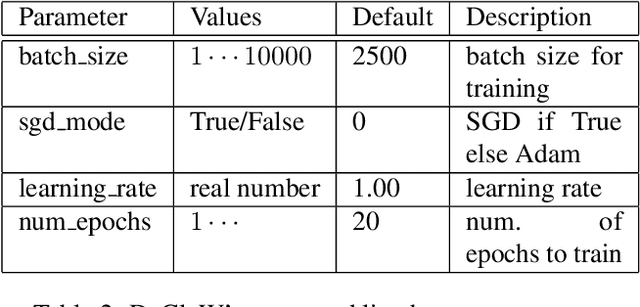
We present DeClaW, a system for detecting, classifying, and warning of adversarial inputs presented to a classification neural network. In contrast to current state-of-the-art methods that, given an input, detect whether an input is clean or adversarial, we aim to also identify the types of adversarial attack (e.g., PGD, Carlini-Wagner or clean). To achieve this, we extract statistical profiles, which we term as anomaly feature vectors, from a set of latent features. Preliminary findings suggest that AFVs can help distinguish among several types of adversarial attacks (e.g., PGD versus Carlini-Wagner) with close to 93% accuracy on the CIFAR-10 dataset. The results open the door to using AFV-based methods for exploring not only adversarial attack detection but also classification of the attack type and then design of attack-specific mitigation strategies.
Smart Black Box 2.0: Efficient High-bandwidth Driving Data Collection based on Video Anomalies
Feb 09, 2021
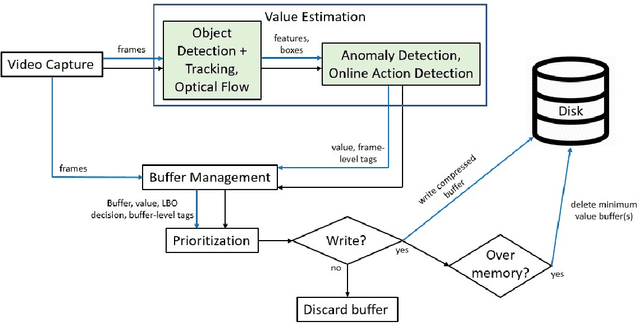


Autonomous vehicles require fleet-wide data collection for continuous algorithm development and validation. The Smart Black Box (SBB) intelligent event data recorder has been proposed as a system for prioritized high-bandwidth data capture. This paper extends the SBB by applying anomaly detection and action detection methods for generalized event-of-interest (EOI) detection. An updated SBB pipeline is proposed for the real-time capture of driving video data. A video dataset is constructed to evaluate the SBB on real-world data for the first time. SBB performance is assessed by comparing the compression of normal and anomalous data and by comparing our prioritized data recording with a FIFO strategy. Results show that SBB data compression can increase the anomalous-to-normal memory ratio by ~25%, while the prioritized recording strategy increases the anomalous-to-normal count ratio when compared to a FIFO strategy. We compare the real-world dataset SBB results to a baseline SBB given ground-truth anomaly labels and conclude that improved general EOI detection methods will greatly improve SBB performance.
Essential Features: Reducing the Attack Surface of Adversarial Perturbations with Robust Content-Aware Image Preprocessing
Dec 03, 2020
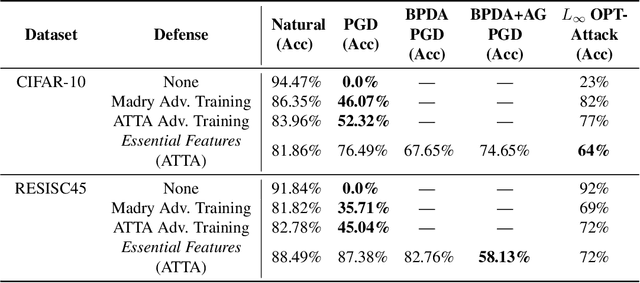
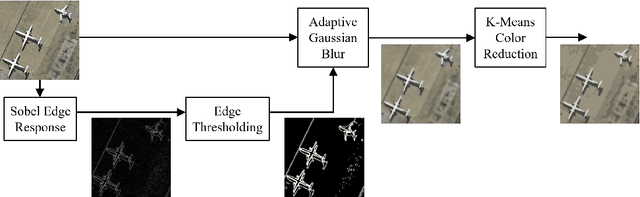
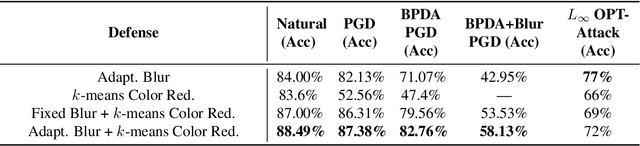
Adversaries are capable of adding perturbations to an image to fool machine learning models into incorrect predictions. One approach to defending against such perturbations is to apply image preprocessing functions to remove the effects of the perturbation. Existing approaches tend to be designed orthogonally to the content of the image and can be beaten by adaptive attacks. We propose a novel image preprocessing technique called Essential Features that transforms the image into a robust feature space that preserves the main content of the image while significantly reducing the effects of the perturbations. Specifically, an adaptive blurring strategy that preserves the main edge features of the original object along with a k-means color reduction approach is employed to simplify the image to its k most representative colors. This approach significantly limits the attack surface for adversaries by limiting the ability to adjust colors while preserving pertinent features of the original image. We additionally design several adaptive attacks and find that our approach remains more robust than previous baselines. On CIFAR-10 we achieve 64% robustness and 58.13% robustness on RESISC45, raising robustness by over 10% versus state-of-the-art adversarial training techniques against adaptive white-box and black-box attacks. The results suggest that strategies that retain essential features in images by adaptive processing of the content hold promise as a complement to adversarial training for boosting robustness against adversarial inputs.
Query-Efficient Physical Hard-Label Attacks on Deep Learning Visual Classification
Feb 17, 2020
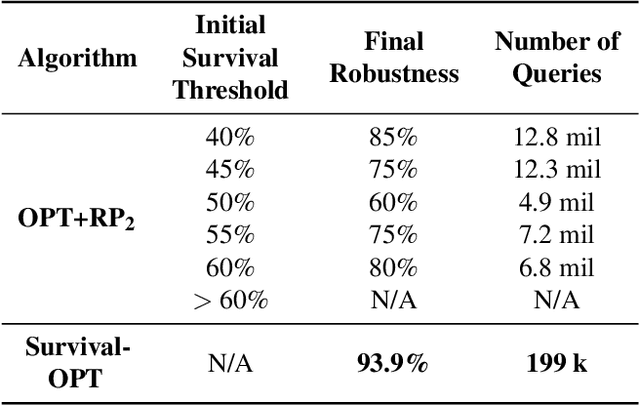

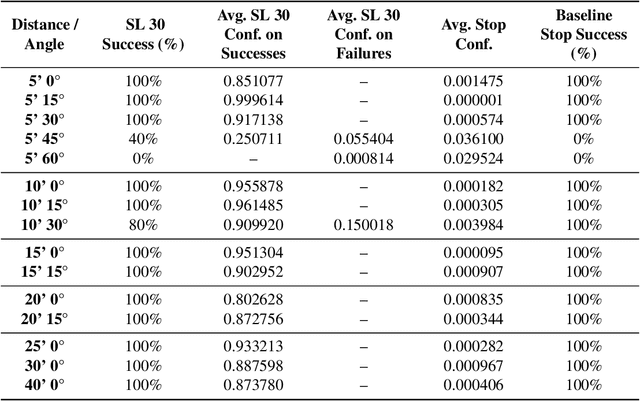
We present Survival-OPT, a physical adversarial example algorithm in the black-box hard-label setting where the attacker only has access to the model prediction class label. Assuming such limited access to the model is more relevant for settings such as proprietary cyber-physical and cloud systems than the whitebox setting assumed by prior work. By leveraging the properties of physical attacks, we create a novel approach based on the survivability of perturbations corresponding to physical transformations. Through simply querying the model for hard-label predictions, we optimize perturbations to survive in many different physical conditions and show that adversarial examples remain a security risk to cyber-physical systems (CPSs) even in the hard-label threat model. We show that Survival-OPT is query-efficient and robust: using fewer than 200K queries, we successfully attack a stop sign to be misclassified as a speed limit 30 km/hr sign in 98.5% of video frames in a drive-by setting. Survival-OPT also outperforms our baseline combination of existing hard-label and physical approaches, which required over 10x more queries for less robust results.