 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeeling the Space: Egomotion-Aware Video Representation for Efficient and Accurate 3D Scene Understanding
Mar 18, 2026Recent Multimodal Large Language Models (MLLMs) have shown high potential for spatial reasoning within 3D scenes. However, they typically rely on computationally expensive 3D representations like point clouds or reconstructed Bird's-Eye View (BEV) maps, or lack physical grounding to resolve ambiguities in scale and size. This paper significantly enhances MLLMs with egomotion modality data, captured by Inertial Measurement Units (IMUs) concurrently with the video. In particular, we propose a novel framework, called Motion-MLLM, introducing two key components: (1) a cascaded motion-visual keyframe filtering module that leverages both IMU data and visual features to efficiently select a sparse yet representative set of keyframes, and (2) an asymmetric cross-modal fusion module where motion tokens serve as intermediaries that channel egomotion cues and cross-frame visual context into the visual representation. By grounding visual content in physical egomotion trajectories, Motion-MLLM can reason about absolute scale and spatial relationships across the scene. Our extensive evaluation shows that Motion-MLLM makes significant improvements in various tasks related to 3D scene understanding and spatial reasoning. Compared to state-of-the-art (SOTA) methods based on video frames and explicit 3D data, Motion-MLLM exhibits similar or even higher accuracy with significantly less overhead (i.e., 1.40$\times$ and 1.63$\times$ higher cost-effectiveness, respectively).
Enhancing Predictability of Multi-Tenant DNN Inference for Autonomous Vehicles' Perception
Feb 11, 2026Autonomous vehicles (AVs) rely on sensors and deep neural networks (DNNs) to perceive their surrounding environment and make maneuver decisions in real time. However, achieving real-time DNN inference in the AV's perception pipeline is challenging due to the large gap between the computation requirement and the AV's limited resources. Most, if not all, of existing studies focus on optimizing the DNN inference time to achieve faster perception by compressing the DNN model with pruning and quantization. In contrast, we present a Predictable Perception system with DNNs (PP-DNN) that reduce the amount of image data to be processed while maintaining the same level of accuracy for multi-tenant DNNs by dynamically selecting critical frames and regions of interest (ROIs). PP-DNN is based on our key insight that critical frames and ROIs for AVs vary with the AV's surrounding environment. However, it is challenging to identify and use critical frames and ROIs in multi-tenant DNNs for predictable inference. Given image-frame streams, PP-DNN leverages an ROI generator to identify critical frames and ROIs based on the similarities of consecutive frames and traffic scenarios. PP-DNN then leverages a FLOPs predictor to predict multiply-accumulate operations (MACs) from the dynamic critical frames and ROIs. The ROI scheduler coordinates the processing of critical frames and ROIs with multiple DNN models. Finally, we design a detection predictor for the perception of non-critical frames. We have implemented PP-DNN in an ROS-based AV pipeline and evaluated it with the BDD100K and the nuScenes dataset. PP-DNN is observed to significantly enhance perception predictability, increasing the number of fusion frames by up to 7.3x, reducing the fusion delay by >2.6x and fusion-delay variations by >2.3x, improving detection completeness by 75.4% and the cost-effectiveness by up to 98% over the baseline.
Keypoints as Dynamic Centroids for Unified Human Pose and Segmentation
May 17, 2025The dynamic movement of the human body presents a fundamental challenge for human pose estimation and body segmentation. State-of-the-art approaches primarily rely on combining keypoint heatmaps with segmentation masks but often struggle in scenarios involving overlapping joints or rapidly changing poses during instance-level segmentation. To address these limitations, we propose Keypoints as Dynamic Centroid (KDC), a new centroid-based representation for unified human pose estimation and instance-level segmentation. KDC adopts a bottom-up paradigm to generate keypoint heatmaps for both easily distinguishable and complex keypoints and improves keypoint detection and confidence scores by introducing KeyCentroids using a keypoint disk. It leverages high-confidence keypoints as dynamic centroids in the embedding space to generate MaskCentroids, allowing for swift clustering of pixels to specific human instances during rapid body movements in live environments. Our experimental evaluations on the CrowdPose, OCHuman, and COCO benchmarks demonstrate KDC's effectiveness and generalizability in challenging scenarios in terms of both accuracy and runtime performance. The implementation is available at: https://sites.google.com/view/niazahmad/projects/kdc.
Achieving the Safety and Security of the End-to-End AV Pipeline
Sep 05, 2024
In the current landscape of autonomous vehicle (AV) safety and security research, there are multiple isolated problems being tackled by the community at large. Due to the lack of common evaluation criteria, several important research questions are at odds with one another. For instance, while much research has been conducted on physical attacks deceiving AV perception systems, there is often inadequate investigations on working defenses and on the downstream effects of safe vehicle control. This paper provides a thorough description of the current state of AV safety and security research. We provide individual sections for the primary research questions that concern this research area, including AV surveillance, sensor system reliability, security of the AV stack, algorithmic robustness, and safe environment interaction. We wrap up the paper with a discussion of the issues that concern the interactions of these separate problems. At the conclusion of each section, we propose future research questions that still lack conclusive answers. This position article will serve as an entry point to novice and veteran researchers seeking to partake in this research domain.
DynaMIX: Resource Optimization for DNN-Based Real-Time Applications on a Multi-Tasking System
Feb 03, 2023As deep neural networks (DNNs) prove their importance and feasibility, more and more DNN-based apps, such as detection and classification of objects, have been developed and deployed on autonomous vehicles (AVs). To meet their growing expectations and requirements, AVs should "optimize" use of their limited onboard computing resources for multiple concurrent in-vehicle apps while satisfying their timing requirements (especially for safety). That is, real-time AV apps should share the limited on-board resources with other concurrent apps without missing their deadlines dictated by the frame rate of a camera that generates and provides input images to the apps. However, most, if not all, of existing DNN solutions focus on enhancing the concurrency of their specific hardware without dynamically optimizing/modifying the DNN apps' resource requirements, subject to the number of running apps, owing to their high computational cost. To mitigate this limitation, we propose DynaMIX (Dynamic MIXed-precision model construction), which optimizes the resource requirement of concurrent apps and aims to maximize execution accuracy. To realize a real-time resource optimization, we formulate an optimization problem using app performance profiles to consider both the accuracy and worst-case latency of each app. We also propose dynamic model reconfiguration by lazy loading only the selected layers at runtime to reduce the overhead of loading the entire model. DynaMIX is evaluated in terms of constraint satisfaction and inference accuracy for a multi-tasking system and compared against state-of-the-art solutions, demonstrating its effectiveness and feasibility under various environmental/operating conditions.
Federated User Representation Learning
Sep 27, 2019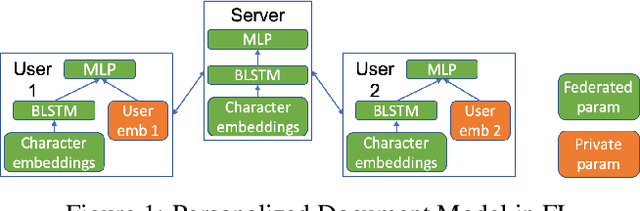

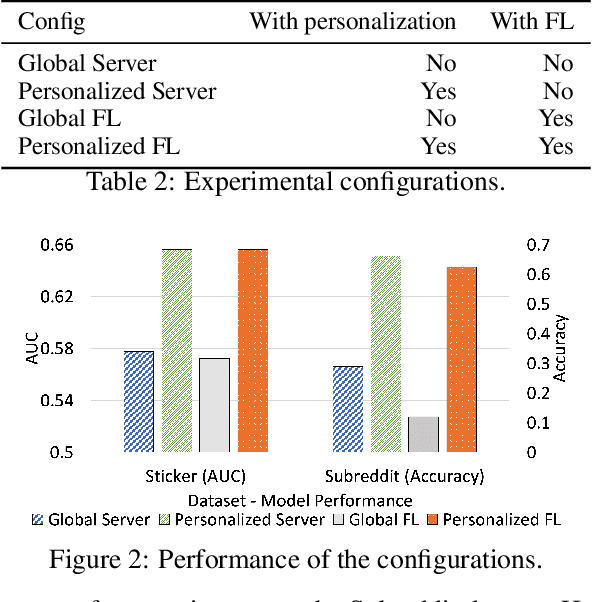
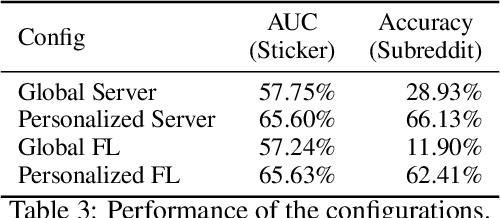
Collaborative personalization, such as through learned user representations (embeddings), can improve the prediction accuracy of neural-network-based models significantly. We propose Federated User Representation Learning (FURL), a simple, scalable, privacy-preserving and resource-efficient way to utilize existing neural personalization techniques in the Federated Learning (FL) setting. FURL divides model parameters into federated and private parameters. Private parameters, such as private user embeddings, are trained locally, but unlike federated parameters, they are not transferred to or averaged on the server. We show theoretically that this parameter split does not affect training for most model personalization approaches. Storing user embeddings locally not only preserves user privacy, but also improves memory locality of personalization compared to on-server training. We evaluate FURL on two datasets, demonstrating a significant improvement in model quality with 8% and 51% performance increases, and approximately the same level of performance as centralized training with only 0% and 4% reductions. Furthermore, we show that user embeddings learned in FL and the centralized setting have a very similar structure, indicating that FURL can learn collaboratively through the shared parameters while preserving user privacy.
Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning
Jun 29, 2018

Privacy policies are the primary channel through which companies inform users about their data collection and sharing practices. These policies are often long and difficult to comprehend. Short notices based on information extracted from privacy policies have been shown to be useful but face a significant scalability hurdle, given the number of policies and their evolution over time. Companies, users, researchers, and regulators still lack usable and scalable tools to cope with the breadth and depth of privacy policies. To address these hurdles, we propose an automated framework for privacy policy analysis (Polisis). It enables scalable, dynamic, and multi-dimensional queries on natural language privacy policies. At the core of Polisis is a privacy-centric language model, built with 130K privacy policies, and a novel hierarchy of neural-network classifiers that accounts for both high-level aspects and fine-grained details of privacy practices. We demonstrate Polisis' modularity and utility with two applications supporting structured and free-form querying. The structured querying application is the automated assignment of privacy icons from privacy policies. With Polisis, we can achieve an accuracy of 88.4% on this task. The second application, PriBot, is the first freeform question-answering system for privacy policies. We show that PriBot can produce a correct answer among its top-3 results for 82% of the test questions. Using an MTurk user study with 700 participants, we show that at least one of PriBot's top-3 answers is relevant to users for 89% of the test questions.
Plan Development using Local Probabilistic Models
Feb 13, 2013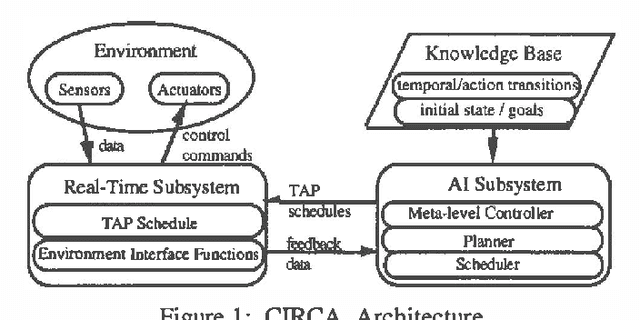

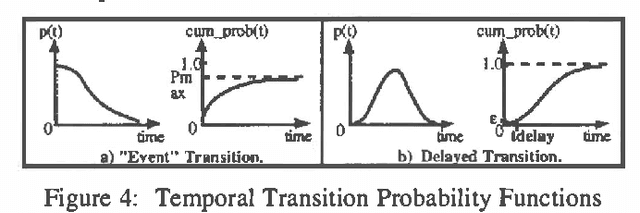
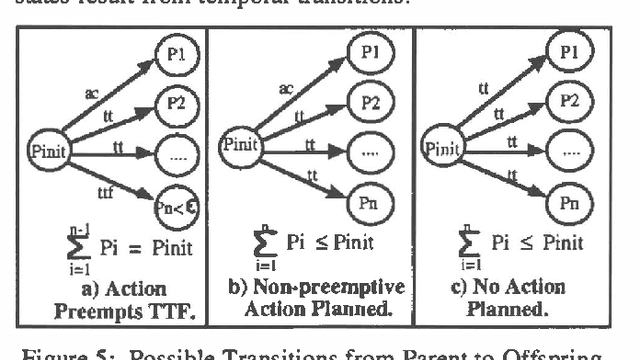
Approximate models of world state transitions are necessary when building plans for complex systems operating in dynamic environments. External event probabilities can depend on state feature values as well as time spent in that particular state. We assign temporally -dependent probability functions to state transitions. These functions are used to locally compute state probabilities, which are then used to select highly probable goal paths and eliminate improbable states. This probabilistic model has been implemented in the Cooperative Intelligent Real-time Control Architecture (CIRCA), which combines an AI planner with a separate real-time system such that plans are developed, scheduled, and executed with real-time guarantees. We present flight simulation tests that demonstrate how our probabilistic model may improve CIRCA performance.