 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Querying for Cooperative Probabilistic Commitments
Dec 14, 2020
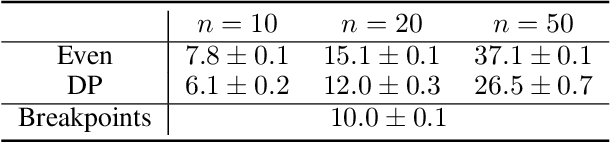
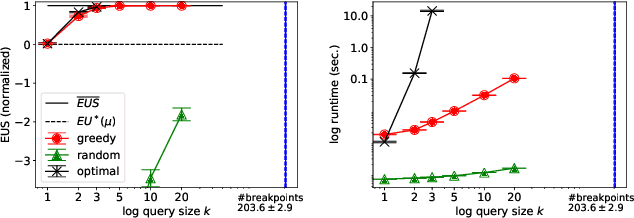
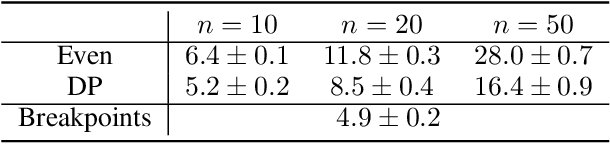
Multiagent systems can use commitments as the core of a general coordination infrastructure, supporting both cooperative and non-cooperative interactions. Agents whose objectives are aligned, and where one agent can help another achieve greater reward by sacrificing some of its own reward, should choose a cooperative commitment to maximize their joint reward. We present a solution to the problem of how cooperative agents can efficiently find an (approximately) optimal commitment by querying about carefully-selected commitment choices. We prove structural properties of the agents' values as functions of the parameters of the commitment specification, and develop a greedy method for composing a query with provable approximation bounds, which we empirically show can find nearly optimal commitments in a fraction of the time methods that lack our insights require.
Resource-Driven Mission-Phasing Techniques for Constrained Agents in Stochastic Environments
Jan 16, 2014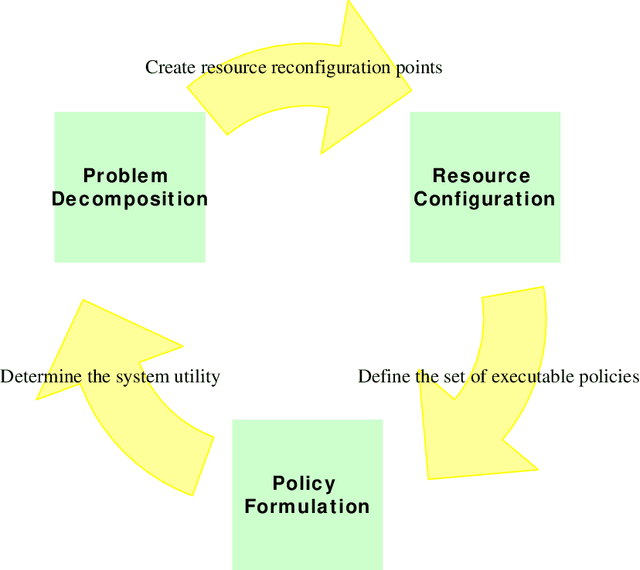
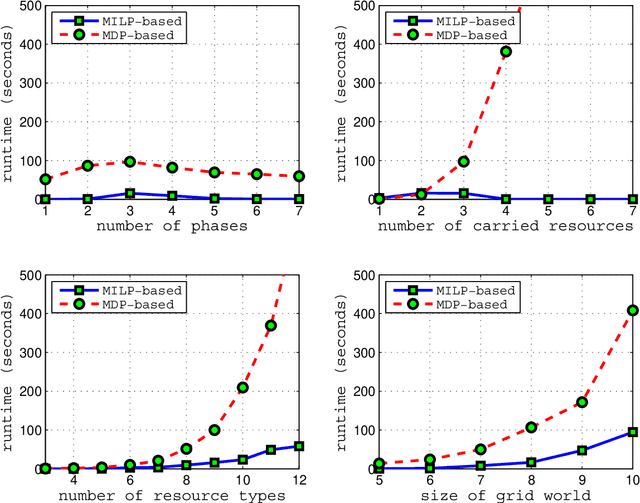

Because an agents resources dictate what actions it can possibly take, it should plan which resources it holds over time carefully, considering its inherent limitations (such as power or payload restrictions), the competing needs of other agents for the same resources, and the stochastic nature of the environment. Such agents can, in general, achieve more of their objectives if they can use --- and even create --- opportunities to change which resources they hold at various times. Driven by resource constraints, the agents could break their overall missions into an optimal series of phases, optimally reconfiguring their resources at each phase, and optimally using their assigned resources in each phase, given their knowledge of the stochastic environment. In this paper, we formally define and analyze this constrained, sequential optimization problem in both the single-agent and multi-agent contexts. We present a family of mixed integer linear programming (MILP) formulations of this problem that can optimally create phases (when phases are not predefined) accounting for costs and limitations in phase creation. Because our formulations multaneously also find the optimal allocations of resources at each phase and the optimal policies for using the allocated resources at each phase, they exploit structure across these coupled problems. This allows them to find solutions significantly faster(orders of magnitude faster in larger problems) than alternative solution techniques, as we demonstrate empirically.
The Automated Mapping of Plans for Plan Recognition
Feb 27, 2013
To coordinate with other agents in its environment, an agent needs models of what the other agents are trying to do. When communication is impossible or expensive, this information must be acquired indirectly via plan recognition. Typical approaches to plan recognition start with a specification of the possible plans the other agents may be following, and develop special techniques for discriminating among the possibilities. Perhaps more desirable would be a uniform procedure for mapping plans to general structures supporting inference based on uncertain and incomplete observations. In this paper, we describe a set of methods for converting plans represented in a flexible procedural language to observation models represented as probabilistic belief networks.
Plan Development using Local Probabilistic Models
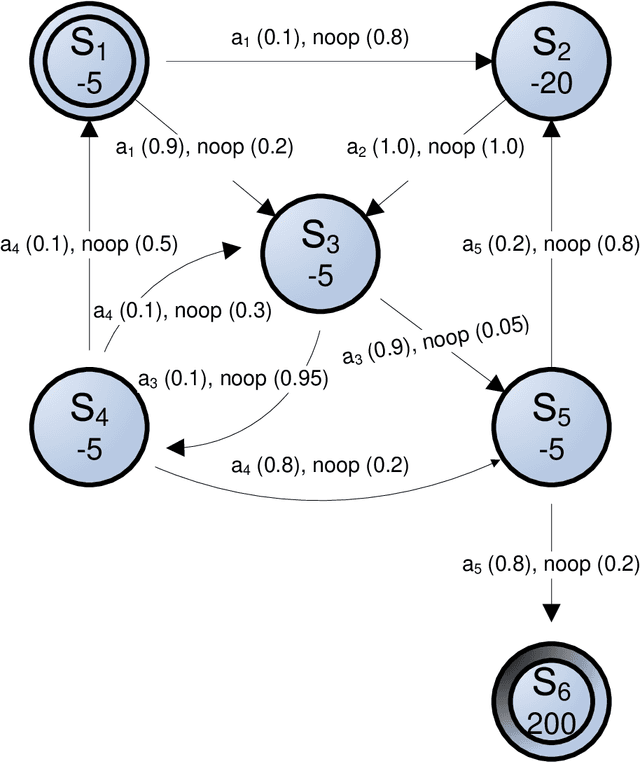
Feb 13, 2013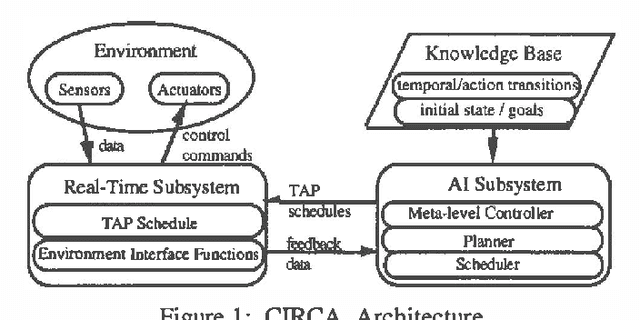

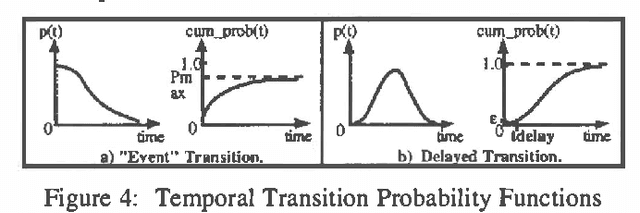
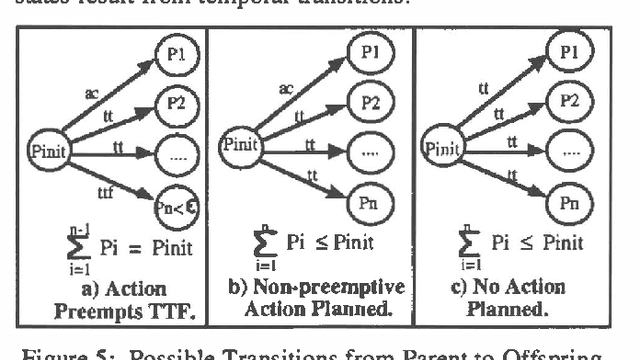
Approximate models of world state transitions are necessary when building plans for complex systems operating in dynamic environments. External event probabilities can depend on state feature values as well as time spent in that particular state. We assign temporally -dependent probability functions to state transitions. These functions are used to locally compute state probabilities, which are then used to select highly probable goal paths and eliminate improbable states. This probabilistic model has been implemented in the Cooperative Intelligent Real-time Control Architecture (CIRCA), which combines an AI planner with a separate real-time system such that plans are developed, scheduled, and executed with real-time guarantees. We present flight simulation tests that demonstrate how our probabilistic model may improve CIRCA performance.
Predicting the expected behavior of agents that learn about agents: the CLRI framework
Jun 20, 2003


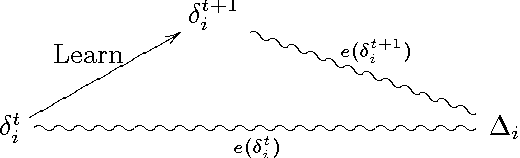
We describe a framework and equations used to model and predict the behavior of multi-agent systems (MASs) with learning agents. A difference equation is used for calculating the progression of an agent's error in its decision function, thereby telling us how the agent is expected to fare in the MAS. The equation relies on parameters which capture the agent's learning abilities, such as its change rate, learning rate and retention rate, as well as relevant aspects of the MAS such as the impact that agents have on each other. We validate the framework with experimental results using reinforcement learning agents in a market system, as well as with other experimental results gathered from the AI literature. Finally, we use PAC-theory to show how to calculate bounds on the values of the learning parameters.
Learning Nested Agent Models in an Information Economy
Sep 26, 1998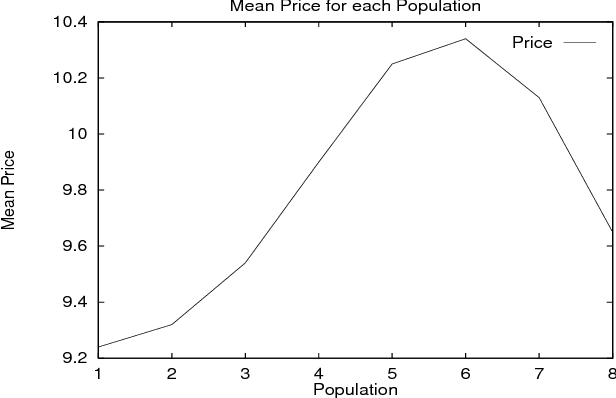
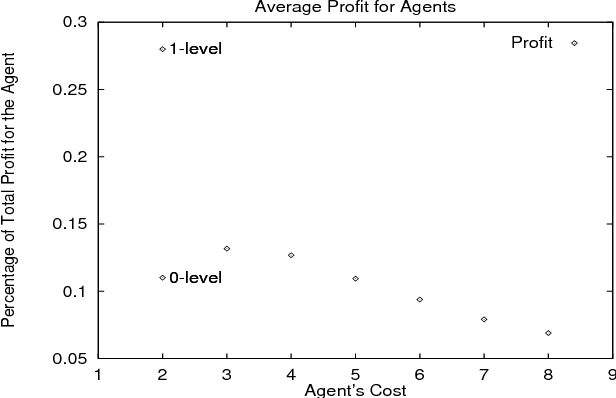
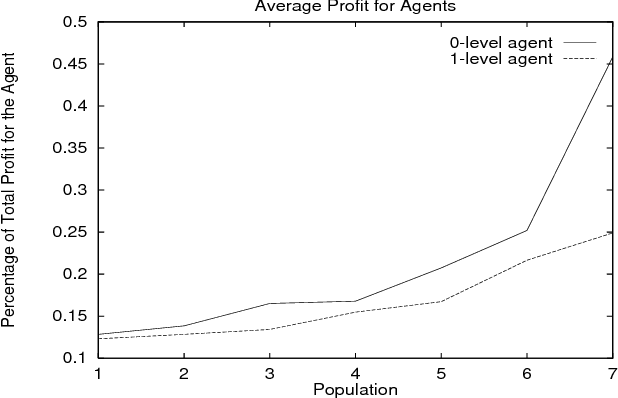
We present our approach to the problem of how an agent, within an economic Multi-Agent System, can determine when it should behave strategically (i.e. learn and use models of other agents), and when it should act as a simple price-taker. We provide a framework for the incremental implementation of modeling capabilities in agents, and a description of the forms of knowledge required. The agents were implemented and different populations simulated in order to learn more about their behavior and the merits of using and learning agent models. Our results show, among other lessons, how savvy buyers can avoid being ``cheated'' by sellers, how price volatility can be used to quantitatively predict the benefits of deeper models, and how specific types of agent populations influence system behavior.