 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode World Models for General Game Playing
Oct 06, 2025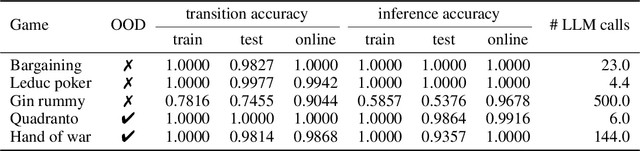

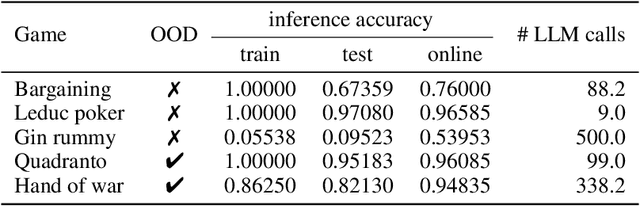
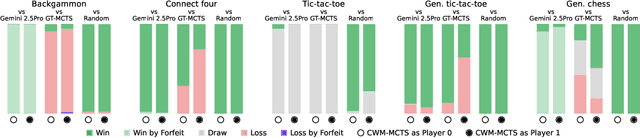
Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
Machine learning empowered Modulation detection for OFDM-based signals
Aug 15, 2024We propose a blind ML-based modulation detection for OFDM-based technologies. Unlike previous works that assume an ideal environment with precise knowledge of subcarrier count and cyclic prefix location, we consider blind modulation detection while accounting for realistic environmental parameters and imperfections. Our approach employs a ResNet network to simultaneously detect the modulation type and accurately locate the cyclic prefix. Specifically, after eliminating the environmental impact from the signal and accurately extracting the OFDM symbols, we convert these symbols into scatter plots. Due to their unique shapes, these scatter plots are then classified using ResNet. As a result, our proposed modulation classification method can be applied to any OFDM-based technology without prior knowledge of the transmitted signal. We evaluate its performance across various modulation schemes and subcarrier numbers. Simulation results show that our method achieves a modulation detection accuracy exceeding $80\%$ at an SNR of $10$ dB and $95\%$ at an SNR of $25$ dB.
Genie: Generative Interactive Environments
Feb 23, 2024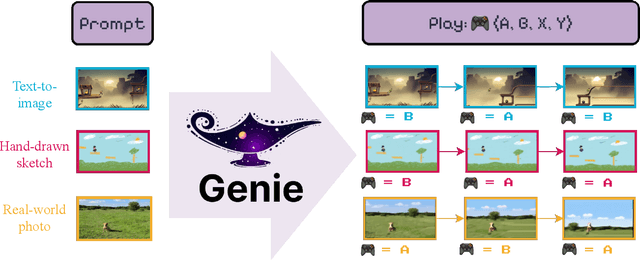
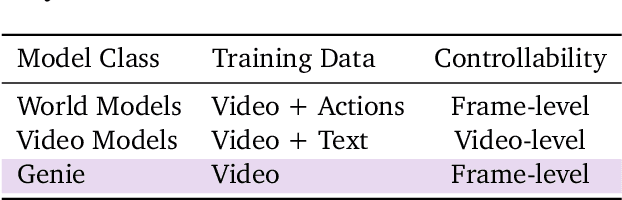
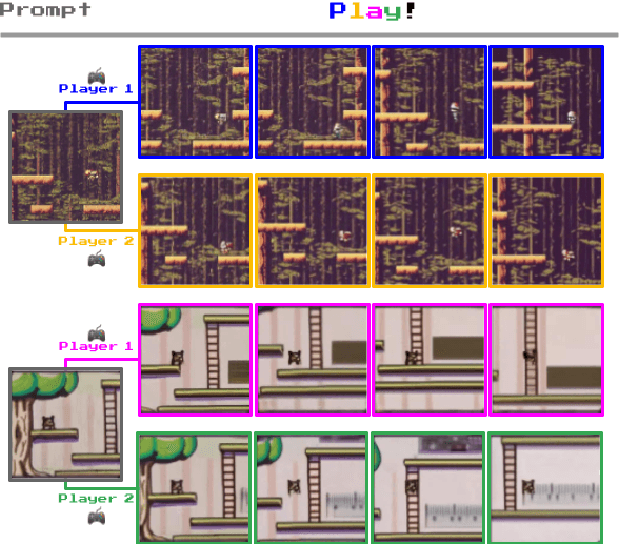
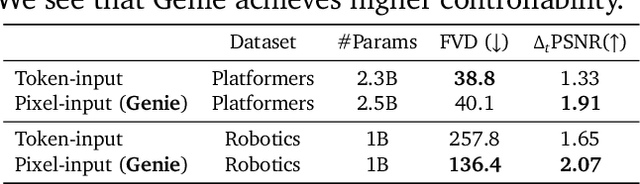
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Combining Behaviors with the Successor Features Keyboard
Oct 24, 2023The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the "Successor Features Keyboard" (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the "Categorical Successor Feature Approximator" (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
On the Convergence of Bounded Agents
Jul 20, 2023When has an agent converged? Standard models of the reinforcement learning problem give rise to a straightforward definition of convergence: An agent converges when its behavior or performance in each environment state stops changing. However, as we shift the focus of our learning problem from the environment's state to the agent's state, the concept of an agent's convergence becomes significantly less clear. In this paper, we propose two complementary accounts of agent convergence in a framing of the reinforcement learning problem that centers around bounded agents. The first view says that a bounded agent has converged when the minimal number of states needed to describe the agent's future behavior cannot decrease. The second view says that a bounded agent has converged just when the agent's performance only changes if the agent's internal state changes. We establish basic properties of these two definitions, show that they accommodate typical views of convergence in standard settings, and prove several facts about their nature and relationship. We take these perspectives, definitions, and analysis to bring clarity to a central idea of the field.
A Definition of Continual Reinforcement Learning
Jul 20, 2023In this paper we develop a foundation for continual reinforcement learning.
Structured State Space Models for In-Context Reinforcement Learning
Mar 09, 2023



Structured state space sequence (S4) models have recently achieved state-of-the-art performance on long-range sequence modeling tasks. These models also have fast inference speeds and parallelisable training, making them potentially useful in many reinforcement learning settings. We propose a modification to a variant of S4 that enables us to initialise and reset the hidden state in parallel, allowing us to tackle reinforcement learning tasks. We show that our modified architecture runs asymptotically faster than Transformers and performs better than LSTM models on a simple memory-based task. Then, by leveraging the model's ability to handle long-range sequences, we achieve strong performance on a challenging meta-learning task in which the agent is given a randomly-sampled continuous control environment, combined with a randomly-sampled linear projection of the environment's observations and actions. Furthermore, we show the resulting model can adapt to out-of-distribution held-out tasks. Overall, the results presented in this paper suggest that the S4 models are a strong contender for the default architecture used for in-context reinforcement learning