 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Endedness is Essential for Artificial Superhuman Intelligence
Jun 06, 2024


In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
Genie: Generative Interactive Environments
Feb 23, 2024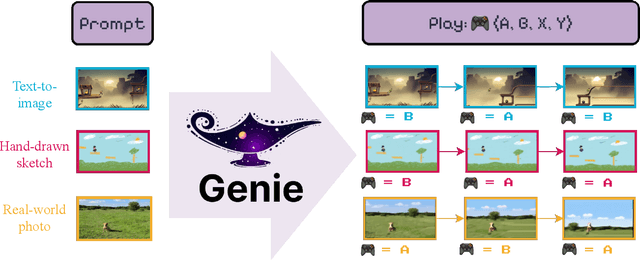
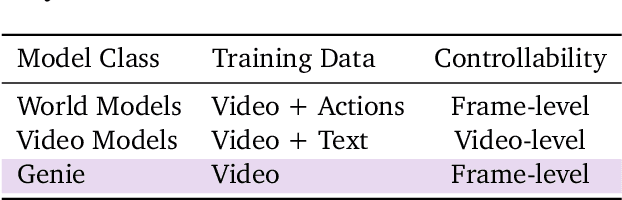
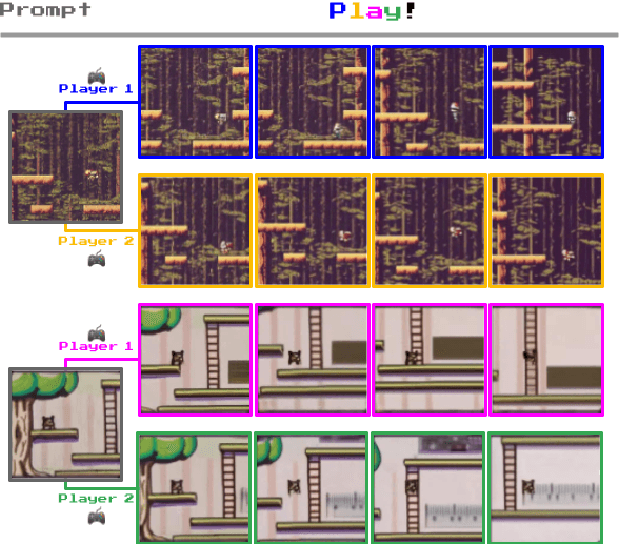
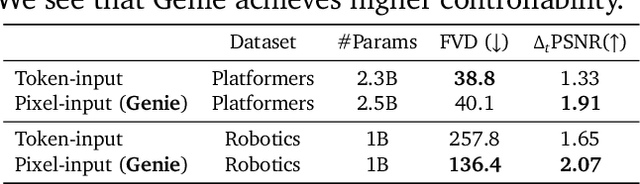
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Provably Efficient Model-based Policy Adaptation
Jun 14, 2020

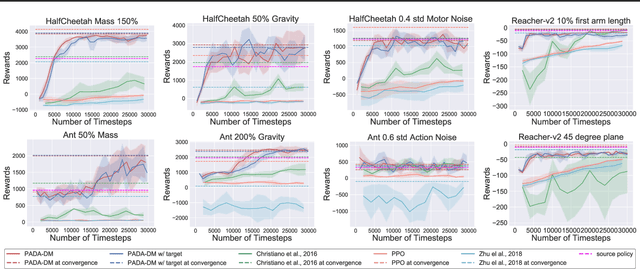

The high sample complexity of reinforcement learning challenges its use in practice. A promising approach is to quickly adapt pre-trained policies to new environments. Existing methods for this policy adaptation problem typically rely on domain randomization and meta-learning, by sampling from some distribution of target environments during pre-training, and thus face difficulty on out-of-distribution target environments. We propose new model-based mechanisms that are able to make online adaptation in unseen target environments, by combining ideas from no-regret online learning and adaptive control. We prove that the approach learns policies in the target environment that can quickly recover trajectories from the source environment, and establish the rate of convergence in general settings. We demonstrate the benefits of our approach for policy adaptation in a diverse set of continuous control tasks, achieving the performance of state-of-the-art methods with much lower sample complexity.
Goal-conditioned Batch Reinforcement Learning for Rotation Invariant Locomotion
Apr 17, 2020



We propose a novel approach to learn goal-conditioned policies for locomotion in a batch RL setting. The batch data is collected by a policy that is not goal-conditioned. For the locomotion task, this translates to data collection using a policy learnt by the agent for walking straight in one direction, and using that data to learn a goal-conditioned policy that enables the agent to walk in any direction. The data collection policy used should be invariant to the direction the agent is facing i.e. regardless of its initial orientation, the agent should take the same actions to walk forward. We exploit this property to learn a goal-conditioned policy using two key ideas: (1) augmenting data by generating trajectories with the same actions in different directions, and (2) learning an encoder that enforces invariance between these rotated trajectories with a Siamese framework. We show that our approach outperforms existing RL algorithms on 3-D locomotion agents like Ant, Humanoid and Minitaur.