 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Capabilities of Reinforcement Learning via Text Feedback
Feb 02, 2026The success of RL for LLM post-training stems from an unreasonably uninformative source: a single bit of information per rollout as binary reward or preference label. At the other extreme, distillation offers dense supervision but requires demonstrations, which are costly and difficult to scale. We study text feedback as an intermediate signal: richer than scalar rewards, yet cheaper than complete demonstrations. Textual feedback is a natural mode of human interaction and is already abundant in many real-world settings, where users, annotators, and automated judges routinely critique LLM outputs. Towards leveraging text feedback at scale, we formalize a multi-turn RL setup, RL from Text Feedback (RLTF), where text feedback is available during training but not at inference. Therefore, models must learn to internalize the feedback in order to improve their test-time single-turn performance. To do this, we propose two methods: Self Distillation (RLTF-SD), which trains the single-turn policy to match its own feedback-conditioned second-turn generations; and Feedback Modeling (RLTF-FM), which predicts the feedback as an auxiliary objective. We provide theoretical analysis on both methods, and empirically evaluate on reasoning puzzles, competition math, and creative writing tasks. Our results show that both methods consistently outperform strong baselines across benchmarks, highlighting the potential of RL with an additional source of rich supervision at scale.
Maximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Towards Scalable Pre-training of Visual Tokenizers for Generation
Dec 15, 2025The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation. We identify this as the ``pre-training scaling problem`` and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy and 0.36 rFID on ImageNet) and 4.1 times faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8\% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS. Our pre-trained models are available at https://github.com/MiniMax-AI/VTP.
Outcome-based Exploration for LLM Reasoning
Sep 08, 2025Reinforcement learning (RL) has emerged as a powerful method for improving the reasoning abilities of large language models (LLMs). Outcome-based RL, which rewards policies solely for the correctness of the final answer, yields substantial accuracy gains but also induces a systematic loss in generation diversity. This collapse undermines real-world performance, where diversity is critical for test-time scaling. We analyze this phenomenon by viewing RL post-training as a sampling process and show that, strikingly, RL can reduce effective diversity even on the training set relative to the base model. Our study highlights two central findings: (i) a transfer of diversity degradation, where reduced diversity on solved problems propagates to unsolved ones, and (ii) the tractability of the outcome space, since reasoning tasks admit only a limited set of distinct answers. Motivated by these insights, we propose outcome-based exploration, which assigns exploration bonuses according to final outcomes. We introduce two complementary algorithms: historical exploration, which encourages rarely observed answers via UCB-style bonuses, and batch exploration, which penalizes within-batch repetition to promote test-time diversity. Experiments on standard competition math with Llama and Qwen models demonstrate that both methods improve accuracy while mitigating diversity collapse. On the theoretical side, we formalize the benefit of outcome-based exploration through a new model of outcome-based bandits. Together, these contributions chart a practical path toward RL methods that enhance reasoning without sacrificing the diversity essential for scalable deployment.
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Dec 03, 2024Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights data based on this verification, and distills the filtered data. Despite several empirical successes, a fundamental understanding is still lacking. In this work, we initiate a comprehensive, modular and controlled study on LLM self-improvement. We provide a mathematical formulation for self-improvement, which is largely governed by a quantity which we formalize as the generation-verification gap. Through experiments with various model families and tasks, we discover a scaling phenomenon of self-improvement -- a variant of the generation-verification gap scales monotonically with the model pre-training flops. We also examine when self-improvement is possible, an iterative self-improvement procedure, and ways to improve its performance. Our findings not only advance understanding of LLM self-improvement with practical implications, but also open numerous avenues for future research into its capabilities and boundaries.
Hybrid Reinforcement Learning from Offline Observation Alone
Jun 11, 2024
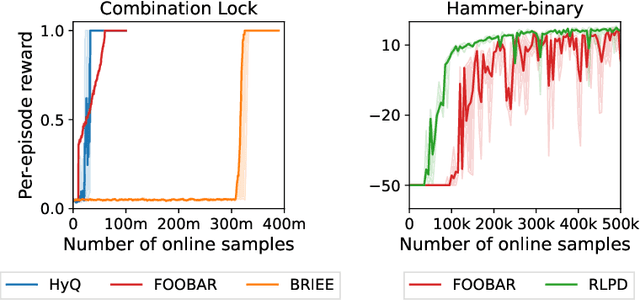

We consider the hybrid reinforcement learning setting where the agent has access to both offline data and online interactive access. While Reinforcement Learning (RL) research typically assumes offline data contains complete action, reward and transition information, datasets with only state information (also known as observation-only datasets) are more general, abundant and practical. This motivates our study of the hybrid RL with observation-only offline dataset framework. While the task of competing with the best policy "covered" by the offline data can be solved if a reset model of the environment is provided (i.e., one that can be reset to any state), we show evidence of hardness when only given the weaker trace model (i.e., one can only reset to the initial states and must produce full traces through the environment), without further assumption of admissibility of the offline data. Under the admissibility assumptions -- that the offline data could actually be produced by the policy class we consider -- we propose the first algorithm in the trace model setting that provably matches the performance of algorithms that leverage a reset model. We also perform proof-of-concept experiments that suggest the effectiveness of our algorithm in practice.
Understanding Preference Fine-Tuning Through the Lens of Coverage
Jun 03, 2024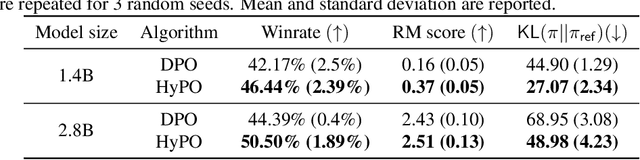
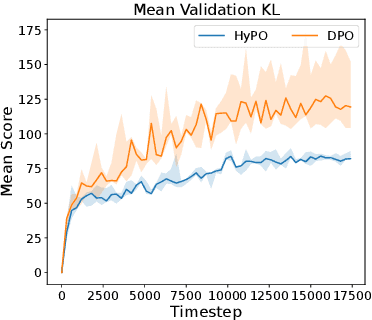

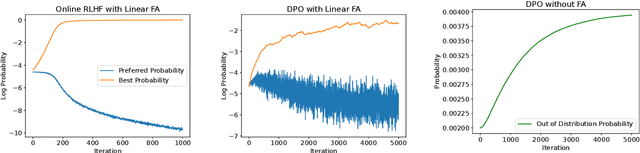
Learning from human preference data has emerged as the dominant paradigm for fine-tuning large language models (LLMs). The two most common families of techniques -- online reinforcement learning (RL) such as Proximal Policy Optimization (PPO) and offline contrastive methods such as Direct Preference Optimization (DPO) -- were positioned as equivalent in prior work due to the fact that both have to start from the same offline preference dataset. To further expand our theoretical understanding of the similarities and differences between online and offline techniques for preference fine-tuning, we conduct a rigorous analysis through the lens of dataset coverage, a concept that captures how the training data covers the test distribution and is widely used in RL. We prove that a global coverage condition is both necessary and sufficient for offline contrastive methods to converge to the optimal policy, but a weaker partial coverage condition suffices for online RL methods. This separation provides one explanation of why online RL methods can perform better than offline methods, especially when the offline preference data is not diverse enough. Finally, motivated by our preceding theoretical observations, we derive a hybrid preference optimization (HyPO) algorithm that uses offline data for contrastive-based preference optimization and online data for KL regularization. Theoretically and empirically, we demonstrate that HyPO is more performant than its pure offline counterpart DPO, while still preserving its computation and memory efficiency.
Rich-Observation Reinforcement Learning with Continuous Latent Dynamics
May 29, 2024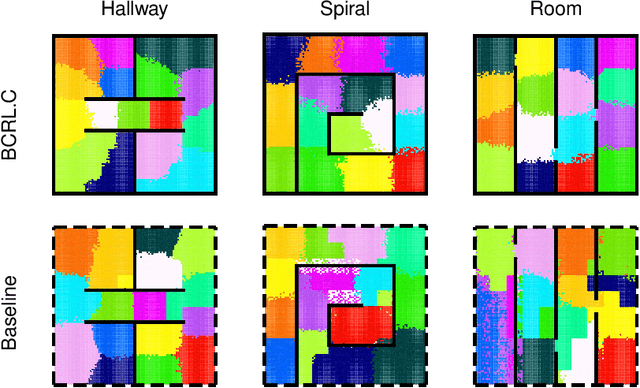
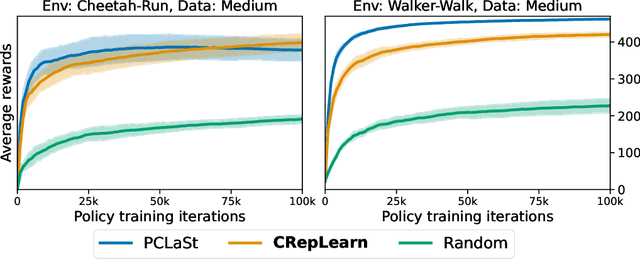
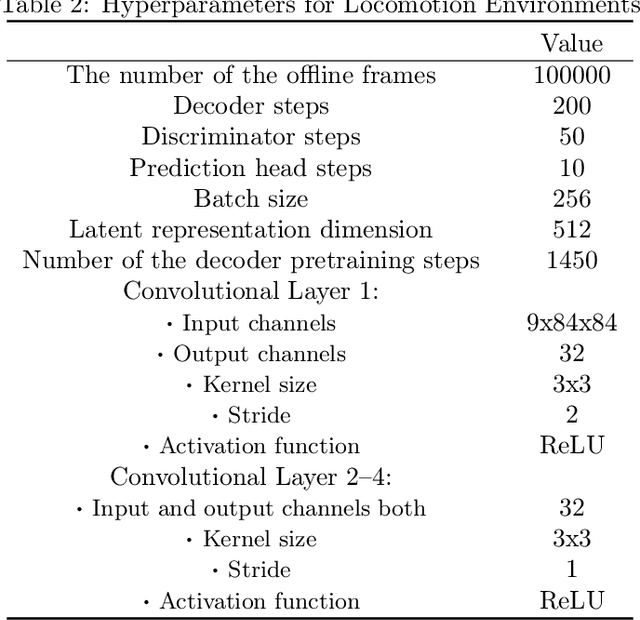
Sample-efficiency and reliability remain major bottlenecks toward wide adoption of reinforcement learning algorithms in continuous settings with high-dimensional perceptual inputs. Toward addressing these challenges, we introduce a new theoretical framework, RichCLD (Rich-Observation RL with Continuous Latent Dynamics), in which the agent performs control based on high-dimensional observations, but the environment is governed by low-dimensional latent states and Lipschitz continuous dynamics. Our main contribution is a new algorithm for this setting that is provably statistically and computationally efficient. The core of our algorithm is a new representation learning objective; we show that prior representation learning schemes tailored to discrete dynamics do not naturally extend to the continuous setting. Our new objective is amenable to practical implementation, and empirically, we find that it compares favorably to prior schemes in a standard evaluation protocol. We further provide several insights into the statistical complexity of the RichCLD framework, in particular proving that certain notions of Lipschitzness that admit sample-efficient learning in the absence of rich observations are insufficient in the rich-observation setting.
SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
Mar 25, 2024Recent advancements in diffusion models have positioned them at the forefront of image generation. Despite their superior performance, diffusion models are not without drawbacks; they are characterized by complex architectures and substantial computational demands, resulting in significant latency due to their iterative sampling process. To mitigate these limitations, we introduce a dual approach involving model miniaturization and a reduction in sampling steps, aimed at significantly decreasing model latency. Our methodology leverages knowledge distillation to streamline the U-Net and image decoder architectures, and introduces an innovative one-step DM training technique that utilizes feature matching and score distillation. We present two models, SDXS-512 and SDXS-1024, achieving inference speeds of approximately 100 FPS (30x faster than SD v1.5) and 30 FP (60x faster than SDXL) on a single GPU, respectively. Moreover, our training approach offers promising applications in image-conditioned control, facilitating efficient image-to-image translation.
Offline Data Enhanced On-Policy Policy Gradient with Provable Guarantees
Nov 14, 2023

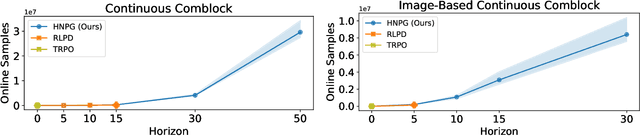

Hybrid RL is the setting where an RL agent has access to both offline data and online data by interacting with the real-world environment. In this work, we propose a new hybrid RL algorithm that combines an on-policy actor-critic method with offline data. On-policy methods such as policy gradient and natural policy gradient (NPG) have shown to be more robust to model misspecification, though sometimes it may not be as sample efficient as methods that rely on off-policy learning. On the other hand, offline methods that depend on off-policy training often require strong assumptions in theory and are less stable to train in practice. Our new approach integrates a procedure of off-policy training on the offline data into an on-policy NPG framework. We show that our approach, in theory, can obtain a best-of-both-worlds type of result -- it achieves the state-of-art theoretical guarantees of offline RL when offline RL-specific assumptions hold, while at the same time maintaining the theoretical guarantees of on-policy NPG regardless of the offline RL assumptions' validity. Experimentally, in challenging rich-observation environments, we show that our approach outperforms a state-of-the-art hybrid RL baseline which only relies on off-policy policy optimization, demonstrating the empirical benefit of combining on-policy and off-policy learning. Our code is publicly available at https://github.com/YifeiZhou02/HNPG.