 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust but Verify: Prover-Verifier Deliberation for Selective LLM Prediction
May 24, 2026Reliably knowing when a language model is correct is almost as important as being correct. We introduce prover-verifier deliberation (PVD), an inference-time protocol grounded in interactive proof theory, as a mechanism for selective prediction: the protocol produces both an answer and a structured confidence verdict, allowing a system to report high-confidence answers while abstaining on uncertain cases. In each dialogue, a prover defends a candidate answer through checkable sub-claims while a verifier issues targeted challenges and returns \textsc{Accept}, \textsc{Challenge}, or \textsc{Reject}. Because frozen language models are imperfect provers and verifiers operating over a noisy channel, formal soundness and completeness guarantees do not transfer; instead, we characterize the protocol empirically through its coverage-precision behavior. Our main experiment uses Claude Sonnet 4.6 as prover and Claude Haiku 4.5 as verifier on GPQA Diamond. Questions accepted with no answer revision, which we call Accept + No Change (ANC), are reported as the high-confidence subset; we evaluate this subset by its precision and coverage. ANC separates reliable from unreliable answers, yielding a $\sim$30pp HC-Prec gap over the non-ANC complement. Robustness experiments with GPT and Gemini pairings show that high HC-Prec can transfer across model families, while verifier strictness and domain competence largely determine the size of the selection gap. On Humanity's Last Exam, weaker prover-verifier pairings can collapse or invert the ANC signal, illustrating a practical failure mode when the verifier operates outside its effective region. Comparisons with self-consistency, universal self-consistency, multi-agent debate, and Reflexion suggest that prover-verifier deliberation supplies a distinct argument-defensibility signal for selective prediction.
Ready from Day 1: Population-Aware Coordination for Large-Scale Constrained Multi-Agent Systems
May 12, 2026In large-scale multi-agent systems with shared resource constraints, an upstream planner must iteratively evaluate candidate resource plans -- assessing feasibility, aggregate response, and marginal cost -- before committing to one. Lagrangian relaxation separates local decisions through a broadcast cost signal, but the planner still needs the cost-to-utilization response map to explore plan space, and this map depends on population composition that changes across planning cycles. We propose \emph{population-aware coordination interfaces}: learned primal and dual maps, conditioned on compact population summaries, that the planner queries inside its iterative loop. The primal map predicts aggregate utilization under a proposed cost trajectory; the dual map predicts the cost trajectory for a target plan. By encoding response-relevant population structure, these maps remain reliable across evolving populations without per-cycle retraining, and support coordination of large populations from compact subsamples. We additionally cast Sim2Real transfer as a backtestable procedure, enabling evaluation before deployment. In a supply-chain capacity-control case study, population-aware interfaces reduce forecast error by 16--19\% and capacity violations by 20--51\% relative to population-unaware baselines under composition shift; 20K-agent cohorts support accurate coordination of 500K-agent populations; and simulator-trained primal maps achieve 11.1\% MAPE on real observations versus 13--24\% for baselines.
Optimal Budgeted Adaptation of Large Language Models
Feb 01, 2026The trade-off between labeled data availability and downstream accuracy remains a central challenge in fine-tuning large language models (LLMs). We propose a principled framework for \emph{budget-aware supervised fine-tuning} by casting LLM adaptation as a contextual Stackelberg game. In our formulation, the learner (leader) commits to a scoring policy and a label-querying strategy, while an adaptive environment (follower) selects challenging supervised alternatives in response. To explicitly address label efficiency, we incorporate a finite supervision budget directly into the learning objective. Our algorithm operates in the full-feedback regime and achieves $\tilde{O}(d\sqrt{T})$ regret under standard linear contextual assumptions. We extend the framework with a Largest-Latency-First (LLF) confidence gate that selectively queries labels, achieving a budget-aware regret bound of $\tilde{O}(\sqrt{dB} + c\sqrt{B})$ with $B=βT$.
Structure-Informed Deep Reinforcement Learning for Inventory Management
Jul 29, 2025

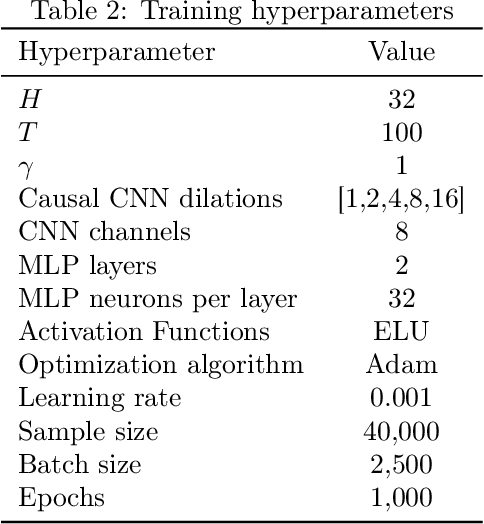
This paper investigates the application of Deep Reinforcement Learning (DRL) to classical inventory management problems, with a focus on practical implementation considerations. We apply a DRL algorithm based on DirectBackprop to several fundamental inventory management scenarios including multi-period systems with lost sales (with and without lead times), perishable inventory management, dual sourcing, and joint inventory procurement and removal. The DRL approach learns policies across products using only historical information that would be available in practice, avoiding unrealistic assumptions about demand distributions or access to distribution parameters. We demonstrate that our generic DRL implementation performs competitively against or outperforms established benchmarks and heuristics across these diverse settings, while requiring minimal parameter tuning. Through examination of the learned policies, we show that the DRL approach naturally captures many known structural properties of optimal policies derived from traditional operations research methods. To further improve policy performance and interpretability, we propose a Structure-Informed Policy Network technique that explicitly incorporates analytically-derived characteristics of optimal policies into the learning process. This approach can help interpretability and add robustness to the policy in out-of-sample performance, as we demonstrate in an example with realistic demand data. Finally, we provide an illustrative application of DRL in a non-stationary setting. Our work bridges the gap between data-driven learning and analytical insights in inventory management while maintaining practical applicability.
Mind the Gap: Examining the Self-Improvement Capabilities of Large Language Models
Dec 03, 2024Self-improvement is a mechanism in Large Language Model (LLM) pre-training, post-training and test-time inference. We explore a framework where the model verifies its own outputs, filters or reweights data based on this verification, and distills the filtered data. Despite several empirical successes, a fundamental understanding is still lacking. In this work, we initiate a comprehensive, modular and controlled study on LLM self-improvement. We provide a mathematical formulation for self-improvement, which is largely governed by a quantity which we formalize as the generation-verification gap. Through experiments with various model families and tasks, we discover a scaling phenomenon of self-improvement -- a variant of the generation-verification gap scales monotonically with the model pre-training flops. We also examine when self-improvement is possible, an iterative self-improvement procedure, and ways to improve its performance. Our findings not only advance understanding of LLM self-improvement with practical implications, but also open numerous avenues for future research into its capabilities and boundaries.
How Does Critical Batch Size Scale in Pre-training?
Oct 29, 2024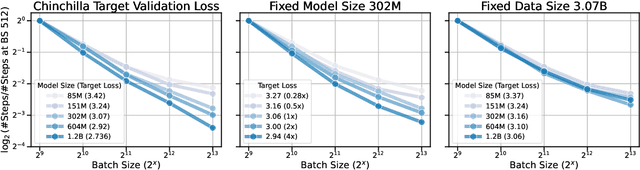

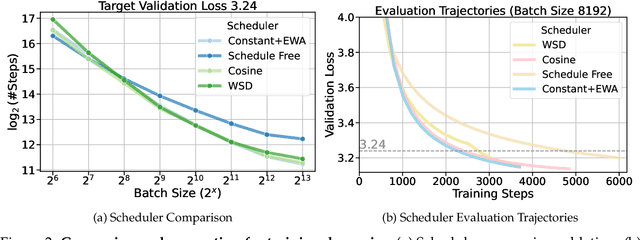
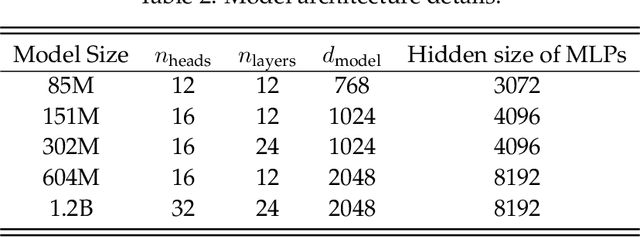
Training large-scale models under given resources requires careful design of parallelism strategies. In particular, the efficiency notion of critical batch size, concerning the compromise between time and compute, marks the threshold beyond which greater data parallelism leads to diminishing returns. To operationalize it, we propose a measure of CBS and pre-train a series of auto-regressive language models, ranging from 85 million to 1.2 billion parameters, on the C4 dataset. Through extensive hyper-parameter sweeps and careful control on factors such as batch size, momentum, and learning rate along with its scheduling, we systematically investigate the impact of scale on CBS. Then we fit scaling laws with respect to model and data sizes to decouple their effects. Overall, our results demonstrate that CBS scales primarily with data size rather than model size, a finding we justify theoretically through the analysis of infinite-width limits of neural networks and infinite-dimensional least squares regression. Of independent interest, we highlight the importance of common hyper-parameter choices and strategies for studying large-scale pre-training beyond fixed training durations.
A Study on the Calibration of In-context Learning
Dec 11, 2023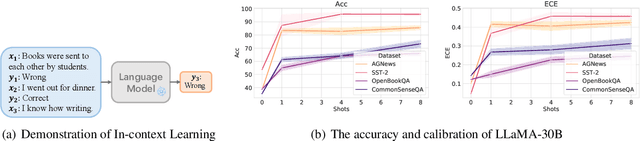

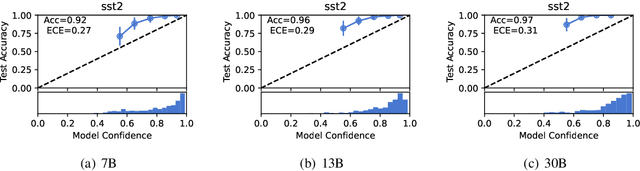
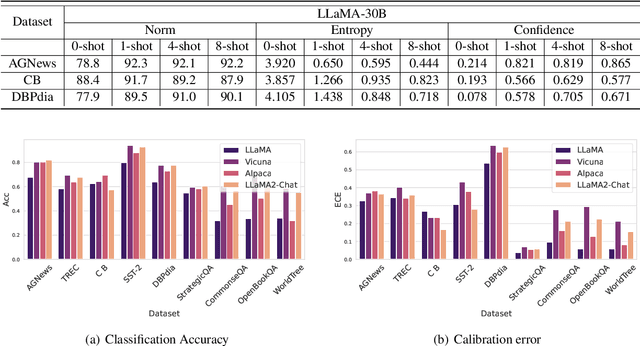
Modern auto-regressive language models are trained to minimize log loss on broad data by predicting the next token so they are expected to get calibrated answers in next-token prediction tasks. We study this for in-context learning (ICL), a widely used way to adapt frozen large language models (LLMs) via crafting prompts, and investigate the trade-offs between performance and calibration on a wide range of natural language understanding and reasoning tasks. We conduct extensive experiments to show that such trade-offs may get worse as we increase model size, incorporate more ICL examples, and fine-tune models using instruction, dialog, or reinforcement learning from human feedback (RLHF) on carefully curated datasets. Furthermore, we find that common recalibration techniques that are widely effective such as temperature scaling provide limited gains in calibration errors, suggesting that new methods may be required for settings where models are expected to be reliable.
AI safety by debate via regret minimization
Dec 08, 2023



We consider the setting of AI safety by debate as a repeated game. We consider the question of efficient regret minimization in this setting, when the players are either AIs or humans, equipped with access to computationally superior AIs. In such a setting, we characterize when internal and external regret can be minimized efficiently. We conclude with conditions in which a sequence of strategies converges to a correlated equilibrium.
Learning an Inventory Control Policy with General Inventory Arrival Dynamics
Oct 26, 2023



In this paper we address the problem of learning and backtesting inventory control policies in the presence of general arrival dynamics -- which we term as a quantity-over-time arrivals model (QOT). We also allow for order quantities to be modified as a post-processing step to meet vendor constraints such as order minimum and batch size constraints -- a common practice in real supply chains. To the best of our knowledge this is the first work to handle either arbitrary arrival dynamics or an arbitrary downstream post-processing of order quantities. Building upon recent work (Madeka et al., 2022) we similarly formulate the periodic review inventory control problem as an exogenous decision process, where most of the state is outside the control of the agent. Madeka et al. (2022) show how to construct a simulator that replays historic data to solve this class of problem. In our case, we incorporate a deep generative model for the arrivals process as part of the history replay. By formulating the problem as an exogenous decision process, we can apply results from Madeka et al. (2022) to obtain a reduction to supervised learning. Finally, we show via simulation studies that this approach yields statistically significant improvements in profitability over production baselines. Using data from an ongoing real-world A/B test, we show that Gen-QOT generalizes well to off-policy data.
Contextual Bandits for Evaluating and Improving Inventory Control Policies
Oct 24, 2023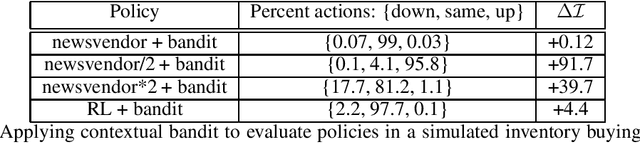
Solutions to address the periodic review inventory control problem with nonstationary random demand, lost sales, and stochastic vendor lead times typically involve making strong assumptions on the dynamics for either approximation or simulation, and applying methods such as optimization, dynamic programming, or reinforcement learning. Therefore, it is important to analyze and evaluate any inventory control policy, in particular to see if there is room for improvement. We introduce the concept of an equilibrium policy, a desirable property of a policy that intuitively means that, in hindsight, changing only a small fraction of actions does not result in materially more reward. We provide a light-weight contextual bandit-based algorithm to evaluate and occasionally tweak policies, and show that this method achieves favorable guarantees, both theoretically and in empirical studies.