 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Imitation Learning in NetHack
Paper and Code
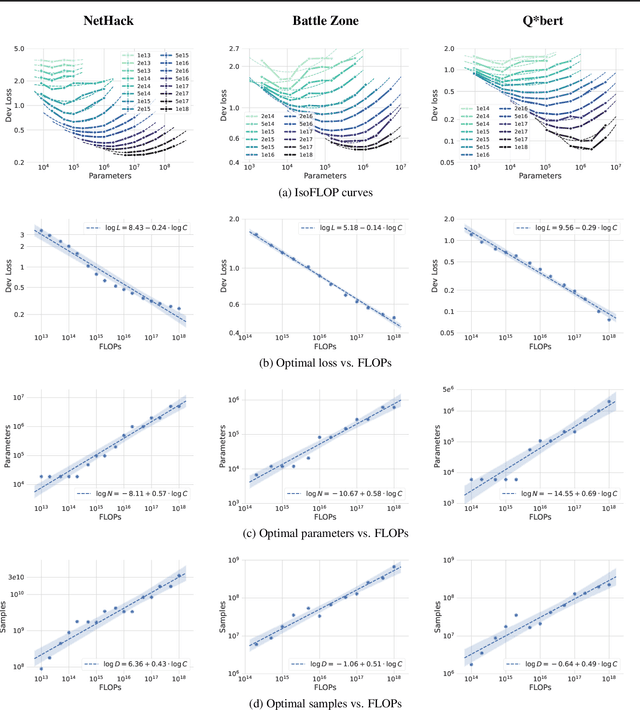

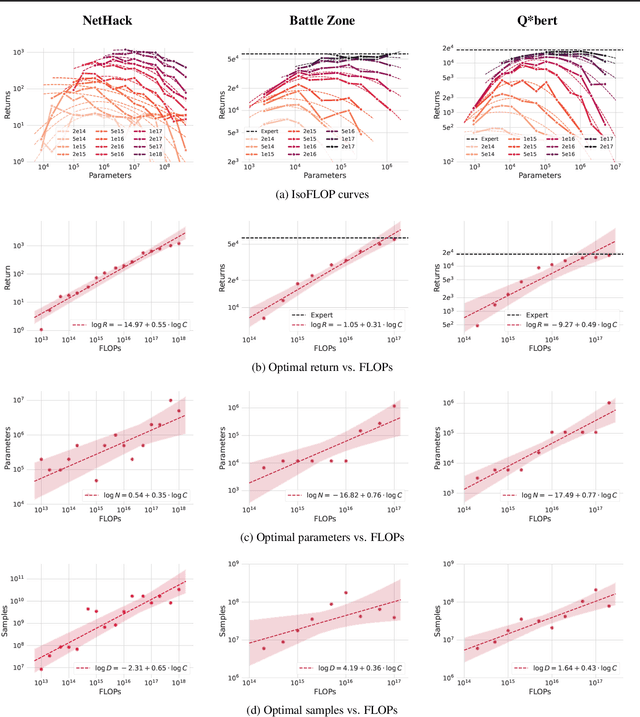
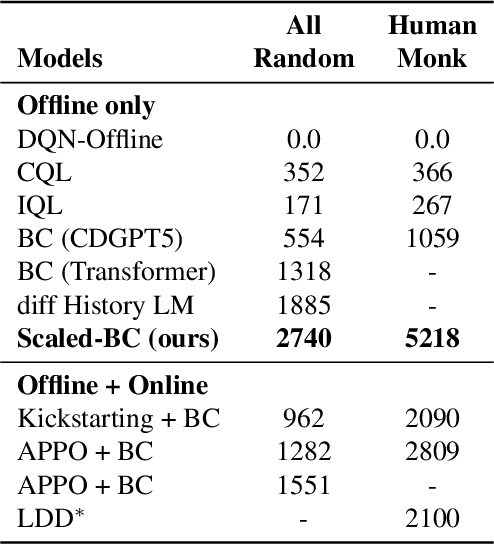
Imitation Learning (IL) is one of the most widely used methods in machine learning. Yet, while powerful, many works find it is often not able to fully recover the underlying expert behavior. However, none of these works deeply investigate the role of scaling up the model and data size. Inspired by recent work in Natural Language Processing (NLP) where "scaling up" has resulted in increasingly more capable LLMs, we investigate whether carefully scaling up model and data size can bring similar improvements in the imitation learning setting. To demonstrate our findings, we focus on the game of NetHack, a challenging environment featuring procedural generation, stochasticity, long-term dependencies, and partial observability. We find IL loss and mean return scale smoothly with the compute budget and are strongly correlated, resulting in power laws for training compute-optimal IL agents with respect to model size and number of samples. We forecast and train several NetHack agents with IL and find they outperform prior state-of-the-art by at least 2x in all settings. Our work both demonstrates the scaling behavior of imitation learning in a challenging domain, as well as the viability of scaling up current approaches for increasingly capable agents in NetHack, a game that remains elusively hard for current AI systems.