 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Filtering for Learning Quantum Dynamics
Jan 29, 2026Learning high-dimensional quantum systems is a fundamental challenge that notoriously suffers from the curse of dimensionality. We formulate the task of predicting quantum evolution in the linear response regime as a specific instance of learning a Complex-Valued Linear Dynamical System (CLDS) with sector-bounded eigenvalues -- a setting that also encompasses modern Structured State Space Models (SSMs). While traditional system identification attempts to reconstruct full system matrices (incurring exponential cost in the Hilbert dimension), we propose Quantum Spectral Filtering, a method that shifts the goal to improper dynamic learning. Leveraging the optimal concentration properties of the Slepian basis, we prove that the learnability of such systems is governed strictly by an effective quantum dimension $k^*$, determined by the spectral bandwidth and memory horizon. This result establishes that complex-valued LDSs can be learned with sample and computational complexity independent of the ambient state dimension, provided their spectrum is bounded.
SFO: Learning PDE Operators via Spectral Filtering
Jan 23, 2026Partial differential equations (PDEs) govern complex systems, yet neural operators often struggle to efficiently capture the long-range, nonlocal interactions inherent in their solution maps. We introduce Spectral Filtering Operator (SFO), a neural operator that parameterizes integral kernels using the Universal Spectral Basis (USB), a fixed, global orthonormal basis derived from the eigenmodes of the Hilbert matrix in spectral filtering theory. Motivated by our theoretical finding that the discrete Green's functions of shift-invariant PDE discretizations exhibit spatial Linear Dynamical System (LDS) structure, we prove that these kernels admit compact approximations in the USB. By learning only the spectral coefficients of rapidly decaying eigenvalues, SFO achieves a highly efficient representation. Across six benchmarks, including reaction-diffusion, fluid dynamics, and 3D electromagnetics, SFO achieves state-of-the-art accuracy, reducing error by up to 40% relative to strong baselines while using substantially fewer parameters.
Research Program: Theory of Learning in Dynamical Systems
Dec 22, 2025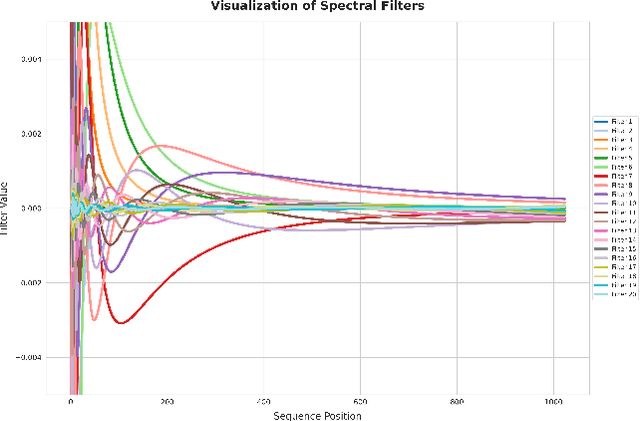
Modern learning systems increasingly interact with data that evolve over time and depend on hidden internal state. We ask a basic question: when is such a dynamical system learnable from observations alone? This paper proposes a research program for understanding learnability in dynamical systems through the lens of next-token prediction. We argue that learnability in dynamical systems should be studied as a finite-sample question, and be based on the properties of the underlying dynamics rather than the statistical properties of the resulting sequence. To this end, we give a formulation of learnability for stochastic processes induced by dynamical systems, focusing on guarantees that hold uniformly at every time step after a finite burn-in period. This leads to a notion of dynamic learnability which captures how the structure of a system, such as stability, mixing, observability, and spectral properties, governs the number of observations required before reliable prediction becomes possible. We illustrate the framework in the case of linear dynamical systems, showing that accurate prediction can be achieved after finite observation without system identification, by leveraging improper methods based on spectral filtering. We survey the relationship between learning in dynamical systems and classical PAC, online, and universal prediction theories, and suggest directions for studying nonlinear and controlled systems.
Efficient Spectral Control of Partially Observed Linear Dynamical Systems
May 27, 2025We propose a new method for the problem of controlling linear dynamical systems under partial observation and adversarial disturbances. Our new algorithm, Double Spectral Control (DSC), matches the best known regret guarantees while exponentially improving runtime complexity over previous approaches in its dependence on the system's stability margin. Our key innovation is a two-level spectral approximation strategy, leveraging double convolution with a universal basis of spectral filters, enabling efficient and accurate learning of the best linear dynamical controllers.
SpectraLDS: Provable Distillation for Linear Dynamical Systems
May 23, 2025We present the first provable method for identifying symmetric linear dynamical systems (LDS) with accuracy guarantees that are independent of the systems' state dimension or effective memory. Our approach builds upon recent work that represents symmetric LDSs as convolutions learnable via fixed spectral transformations. We show how to invert this representation, thereby recovering an LDS model from its spectral transform and yielding an end-to-end convex optimization procedure. This distillation preserves predictive accuracy while enabling constant-time and constant-space inference per token, independent of sequence length. We evaluate our method, SpectraLDS, as a component in sequence prediction architectures and demonstrate that accuracy is preserved while inference efficiency is improved on tasks such as language modeling.
A New Approach to Controlling Linear Dynamical Systems
Apr 04, 2025


We propose a new method for controlling linear dynamical systems under adversarial disturbances and cost functions. Our algorithm achieves a running time that scales polylogarithmically with the inverse of the stability margin, improving upon prior methods with polynomial dependence maintaining the same regret guarantees. The technique, which may be of independent interest, is based on a novel convex relaxation that approximates linear control policies using spectral filters constructed from the eigenvectors of a specific Hankel matrix.
Dimension-free Regret for Learning Asymmetric Linear Dynamical Systems
Feb 10, 2025


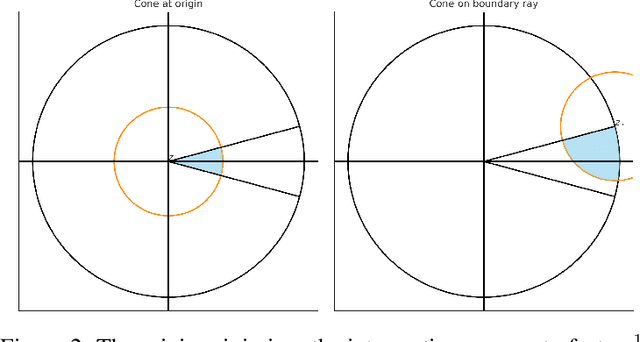
Previously, methods for learning marginally stable linear dynamical systems either required the transition matrix to be symmetric or incurred regret bounds that scale polynomially with the system's hidden dimension. In this work, we introduce a novel method that overcomes this trade-off, achieving dimension-free regret despite the presence of asymmetric matrices and marginal stability. Our method combines spectral filtering with linear predictors and employs Chebyshev polynomials in the complex plane to construct a novel spectral filtering basis. This construction guarantees sublinear regret in an online learning framework, without relying on any statistical or generative assumptions. Specifically, we prove that as long as the transition matrix has eigenvalues with complex component bounded by $1/\mathrm{poly} \log T$, then our method achieves regret $\tilde{O}(T^{9/10})$ when compared to the best linear dynamical predictor in hindsight.
Provable Length Generalization in Sequence Prediction via Spectral Filtering
Nov 01, 2024



We consider the problem of length generalization in sequence prediction. We define a new metric of performance in this setting -- the Asymmetric-Regret -- which measures regret against a benchmark predictor with longer context length than available to the learner. We continue by studying this concept through the lens of the spectral filtering algorithm. We present a gradient-based learning algorithm that provably achieves length generalization for linear dynamical systems. We conclude with proof-of-concept experiments which are consistent with our theory.
FutureFill: Fast Generation from Convolutional Sequence Models
Oct 02, 2024



We address the challenge of efficient auto-regressive generation in sequence prediction models by introducing FutureFill: a method for fast generation that applies to any sequence prediction algorithm based on convolutional operators. Our approach reduces the generation time requirement from linear to square root relative to the context length. Additionally, FutureFill requires a prefill cache sized only by the number of tokens generated, which is smaller than the cache requirements for standard convolutional and attention-based models. We validate our theoretical findings with experimental evidence demonstrating correctness and efficiency gains in a synthetic generation task.
Flash STU: Fast Spectral Transform Units
Sep 17, 2024This paper describes an efficient, open source PyTorch implementation of the Spectral Transform Unit. We investigate sequence prediction tasks over several modalities including language, robotics, and simulated dynamical systems. We find that for the same parameter count, the STU and its variants outperform the Transformer as well as other leading state space models across various modalities.