 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Worst-Case Dimensionality Reduction for Sparse Vectors
Feb 27, 2025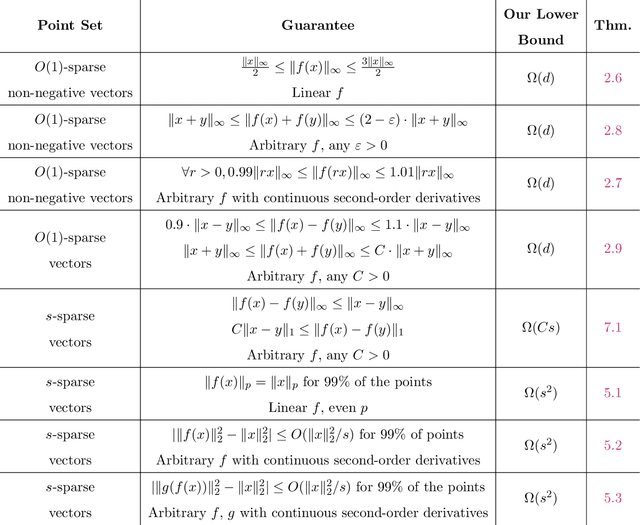
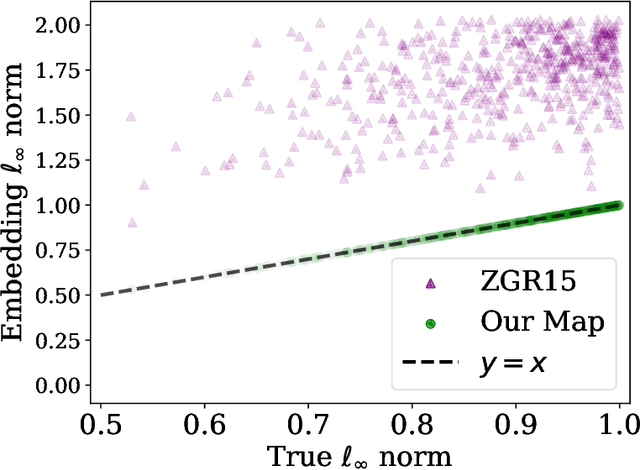
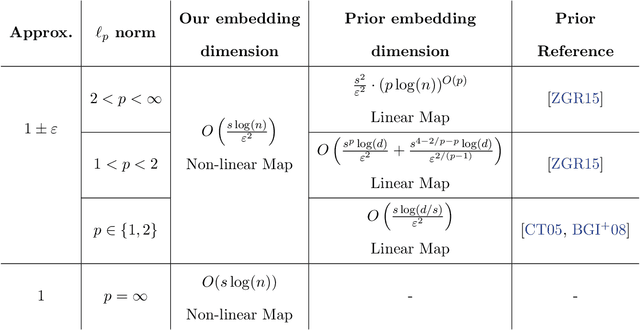
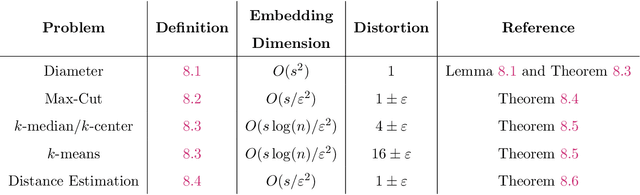
We study beyond worst-case dimensionality reduction for $s$-sparse vectors. Our work is divided into two parts, each focusing on a different facet of beyond worst-case analysis: We first consider average-case guarantees. A folklore upper bound based on the birthday-paradox states: For any collection $X$ of $s$-sparse vectors in $\mathbb{R}^d$, there exists a linear map to $\mathbb{R}^{O(s^2)}$ which \emph{exactly} preserves the norm of $99\%$ of the vectors in $X$ in any $\ell_p$ norm (as opposed to the usual setting where guarantees hold for all vectors). We give lower bounds showing that this is indeed optimal in many settings: any oblivious linear map satisfying similar average-case guarantees must map to $\Omega(s^2)$ dimensions. The same lower bound also holds for a wide class of smooth maps, including `encoder-decoder schemes', where we compare the norm of the original vector to that of a smooth function of the embedding. These lower bounds reveal a separation result, as an upper bound of $O(s \log(d))$ is possible if we instead use arbitrary (possibly non-smooth) functions, e.g., via compressed sensing algorithms. Given these lower bounds, we specialize to sparse \emph{non-negative} vectors. For a dataset $X$ of non-negative $s$-sparse vectors and any $p \ge 1$, we can non-linearly embed $X$ to $O(s\log(|X|s)/\epsilon^2)$ dimensions while preserving all pairwise distances in $\ell_p$ norm up to $1\pm \epsilon$, with no dependence on $p$. Surprisingly, the non-negativity assumption enables much smaller embeddings than arbitrary sparse vectors, where the best known bounds suffer exponential dependence. Our map also guarantees \emph{exact} dimensionality reduction for $\ell_{\infty}$ by embedding into $O(s\log |X|)$ dimensions, which is tight. We show that both the non-linearity of $f$ and the non-negativity of $X$ are necessary, and provide downstream algorithmic improvements.
Quantifying Knowledge Distillation Using Partial Information Decomposition
Nov 12, 2024



Knowledge distillation provides an effective method for deploying complex machine learning models in resource-constrained environments. It typically involves training a smaller student model to emulate either the probabilistic outputs or the internal feature representations of a larger teacher model. By doing so, the student model often achieves substantially better performance on a downstream task compared to when it is trained independently. Nevertheless, the teacher's internal representations can also encode noise or additional information that may not be relevant to the downstream task. This observation motivates our primary question: What are the information-theoretic limits of knowledge transfer? To this end, we leverage a body of work in information theory called Partial Information Decomposition (PID) to quantify the distillable and distilled knowledge of a teacher's representation corresponding to a given student and a downstream task. Moreover, we demonstrate that this metric can be practically used in distillation to address challenges caused by the complexity gap between the teacher and the student representations.
Predicting from Strings: Language Model Embeddings for Bayesian Optimization
Oct 15, 2024


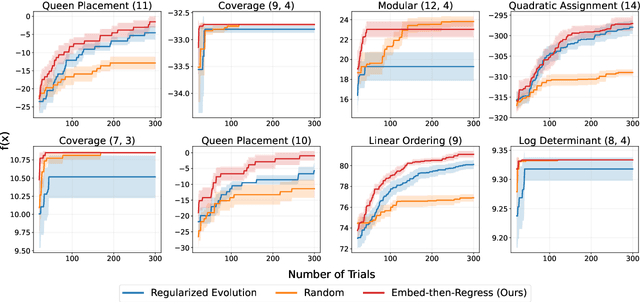
Bayesian Optimization is ubiquitous in the field of experimental design and blackbox optimization for improving search efficiency, but has been traditionally restricted to regression models which are only applicable to fixed search spaces and tabular input features. We propose Embed-then-Regress, a paradigm for applying in-context regression over string inputs, through the use of string embedding capabilities of pretrained language models. By expressing all inputs as strings, we are able to perform general-purpose regression for Bayesian Optimization over various domains including synthetic, combinatorial, and hyperparameter optimization, obtaining comparable results to state-of-the-art Gaussian Process-based algorithms. Code can be found at https://github.com/google-research/optformer/tree/main/optformer/embed_then_regress.
The Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024



Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
Quantifying Spuriousness of Biased Datasets Using Partial Information Decomposition
Jun 29, 2024



Spurious patterns refer to a mathematical association between two or more variables in a dataset that are not causally related. However, this notion of spuriousness, which is usually introduced due to sampling biases in the dataset, has classically lacked a formal definition. To address this gap, this work presents the first information-theoretic formalization of spuriousness in a dataset (given a split of spurious and core features) using a mathematical framework called Partial Information Decomposition (PID). Specifically, we disentangle the joint information content that the spurious and core features share about another target variable (e.g., the prediction label) into distinct components, namely unique, redundant, and synergistic information. We propose the use of unique information, with roots in Blackwell Sufficiency, as a novel metric to formally quantify dataset spuriousness and derive its desirable properties. We empirically demonstrate how higher unique information in the spurious features in a dataset could lead a model into choosing the spurious features over the core features for inference, often having low worst-group-accuracy. We also propose a novel autoencoder-based estimator for computing unique information that is able to handle high-dimensional image data. Finally, we also show how this unique information in the spurious feature is reduced across several dataset-based spurious-pattern-mitigation techniques such as data reweighting and varying levels of background mixing, demonstrating a novel tradeoff between unique information (spuriousness) and worst-group-accuracy.
Preference Learning Algorithms Do Not Learn Preference Rankings
May 29, 2024Preference learning algorithms (e.g., RLHF and DPO) are frequently used to steer LLMs to produce generations that are more preferred by humans, but our understanding of their inner workings is still limited. In this work, we study the conventional wisdom that preference learning trains models to assign higher likelihoods to more preferred outputs than less preferred outputs, measured via $\textit{ranking accuracy}$. Surprisingly, we find that most state-of-the-art preference-tuned models achieve a ranking accuracy of less than 60% on common preference datasets. We furthermore derive the $\textit{idealized ranking accuracy}$ that a preference-tuned LLM would achieve if it optimized the DPO or RLHF objective perfectly. We demonstrate that existing models exhibit a significant $\textit{alignment gap}$ -- $\textit{i.e.}$, a gap between the observed and idealized ranking accuracies. We attribute this discrepancy to the DPO objective, which is empirically and theoretically ill-suited to fix even mild ranking errors in the reference model, and derive a simple and efficient formula for quantifying the difficulty of learning a given preference datapoint. Finally, we demonstrate that ranking accuracy strongly correlates with the empirically popular win rate metric when the model is close to the reference model used in the objective, shedding further light on the differences between on-policy (e.g., RLHF) and off-policy (e.g., DPO) preference learning algorithms.
Adaptive Regret for Bandits Made Possible: Two Queries Suffice
Jan 17, 2024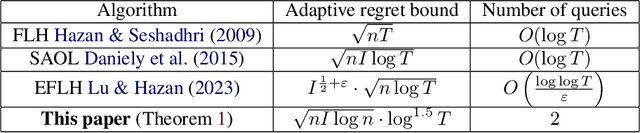
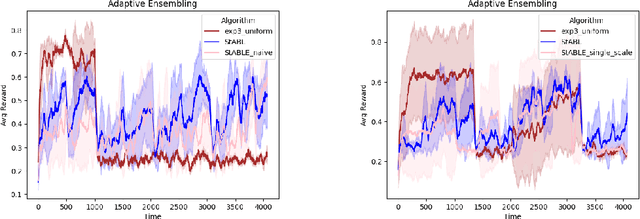
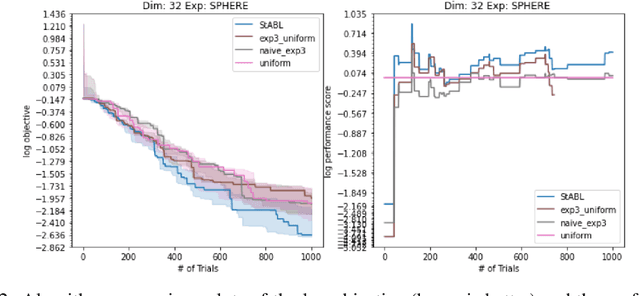
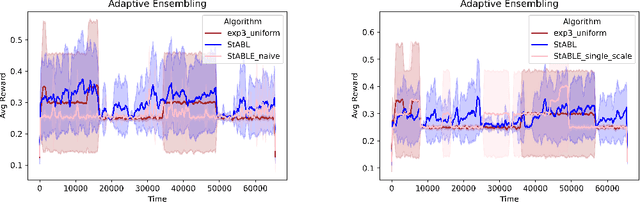
Fast changing states or volatile environments pose a significant challenge to online optimization, which needs to perform rapid adaptation under limited observation. In this paper, we give query and regret optimal bandit algorithms under the strict notion of strongly adaptive regret, which measures the maximum regret over any contiguous interval $I$. Due to its worst-case nature, there is an almost-linear $\Omega(|I|^{1-\epsilon})$ regret lower bound, when only one query per round is allowed [Daniely el al, ICML 2015]. Surprisingly, with just two queries per round, we give Strongly Adaptive Bandit Learner (StABL) that achieves $\tilde{O}(\sqrt{n|I|})$ adaptive regret for multi-armed bandits with $n$ arms. The bound is tight and cannot be improved in general. Our algorithm leverages a multiplicative update scheme of varying stepsizes and a carefully chosen observation distribution to control the variance. Furthermore, we extend our results and provide optimal algorithms in the bandit convex optimization setting. Finally, we empirically demonstrate the superior performance of our algorithms under volatile environments and for downstream tasks, such as algorithm selection for hyperparameter optimization.
Computing Approximate $\ell_p$ Sensitivities
Nov 21, 2023



Recent works in dimensionality reduction for regression tasks have introduced the notion of sensitivity, an estimate of the importance of a specific datapoint in a dataset, offering provable guarantees on the quality of the approximation after removing low-sensitivity datapoints via subsampling. However, fast algorithms for approximating $\ell_p$ sensitivities, which we show is equivalent to approximate $\ell_p$ regression, are known for only the $\ell_2$ setting, in which they are termed leverage scores. In this work, we provide efficient algorithms for approximating $\ell_p$ sensitivities and related summary statistics of a given matrix. In particular, for a given $n \times d$ matrix, we compute $\alpha$-approximation to its $\ell_1$ sensitivities at the cost of $O(n/\alpha)$ sensitivity computations. For estimating the total $\ell_p$ sensitivity (i.e. the sum of $\ell_p$ sensitivities), we provide an algorithm based on importance sampling of $\ell_p$ Lewis weights, which computes a constant factor approximation to the total sensitivity at the cost of roughly $O(\sqrt{d})$ sensitivity computations. Furthermore, we estimate the maximum $\ell_1$ sensitivity, up to a $\sqrt{d}$ factor, using $O(d)$ sensitivity computations. We generalize all these results to $\ell_p$ norms for $p > 1$. Lastly, we experimentally show that for a wide class of matrices in real-world datasets, the total sensitivity can be quickly approximated and is significantly smaller than the theoretical prediction, demonstrating that real-world datasets have low intrinsic effective dimensionality.
Getting aligned on representational alignment
Nov 02, 2023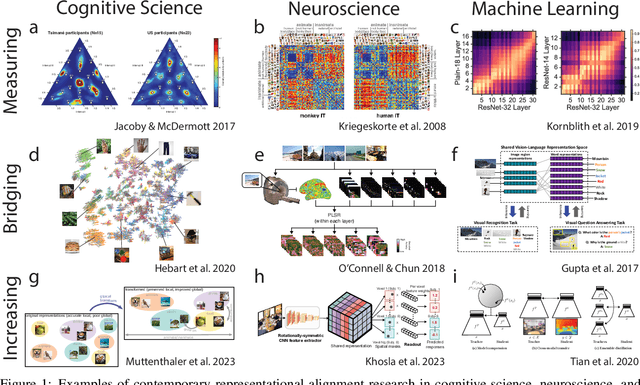
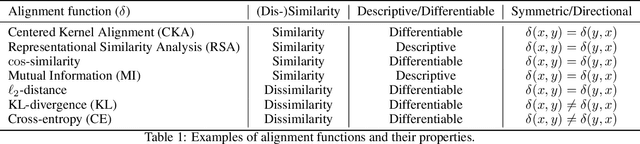
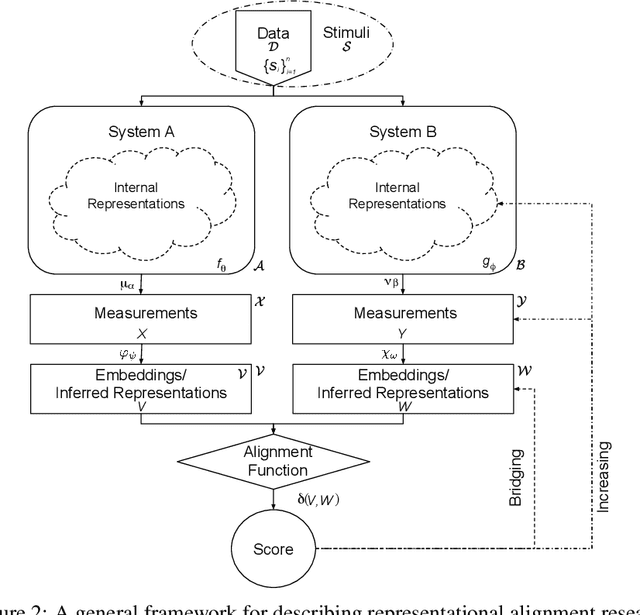
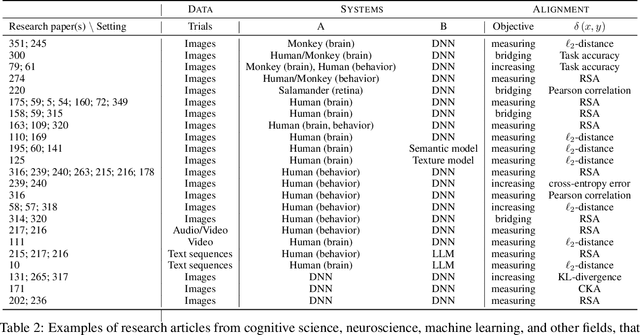
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Set Learning for Accurate and Calibrated Models
Jul 10, 2023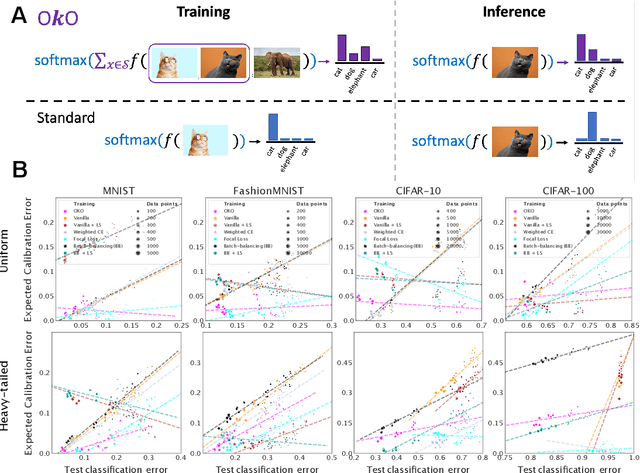
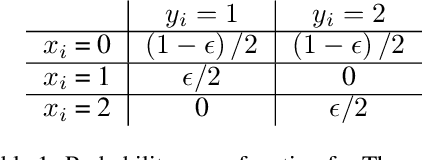
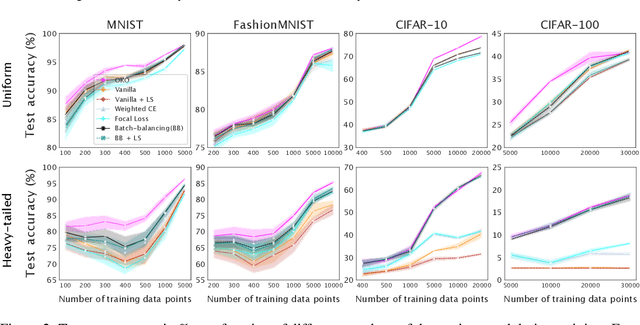
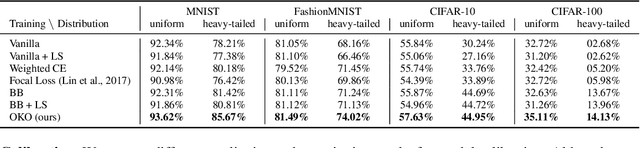
Model overconfidence and poor calibration are common in machine learning and difficult to account for when applying standard empirical risk minimization. In this work, we propose a novel method to alleviate these problems that we call odd-$k$-out learning (OKO), which minimizes the cross-entropy error for sets rather than for single examples. This naturally allows the model to capture correlations across data examples and achieves both better accuracy and calibration, especially in limited training data and class-imbalanced regimes. Perhaps surprisingly, OKO often yields better calibration even when training with hard labels and dropping any additional calibration parameter tuning, such as temperature scaling. We provide theoretical justification, establishing that OKO naturally yields better calibration, and provide extensive experimental analyses that corroborate our theoretical findings. We emphasize that OKO is a general framework that can be easily adapted to many settings and the trained model can be applied to single examples at inference time, without introducing significant run-time overhead or architecture changes.